



CSE502: Computer Architecture
CSE 502:
Computer Architecture
Core Pipelining


































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An in-depth exploration of computer architecture, focusing on pipelining and instruction dependencies. Topics include the fetch, decode, execute, and memory stages of the pipeline, as well as data and control hazards and their resolution. Students will gain a solid understanding of the concepts and terminology related to computer architecture and pipelining.
Typology: Lecture notes
1 / 43

This page cannot be seen from the preview
Don't miss anything!
insn0.(fetch,decode,exec) insn1.(fetch,decode,exec)
insn0.fetch insn0.dec insn0.exec insn1.fetch insn1.dec insn1.exec
time
Stage delay = 𝑛
Bandwidth = ~(
𝑛)
Stage delay =
Bandwidth = ~(
𝑛)
Stage delay =
Bandwidth = ~(
𝑛)
address (^) hit?
=
=
=
=
Increases throughput at the expense of latency
address (^) hit?
=
=
=
=
address (^) hit?
=
=
=
=
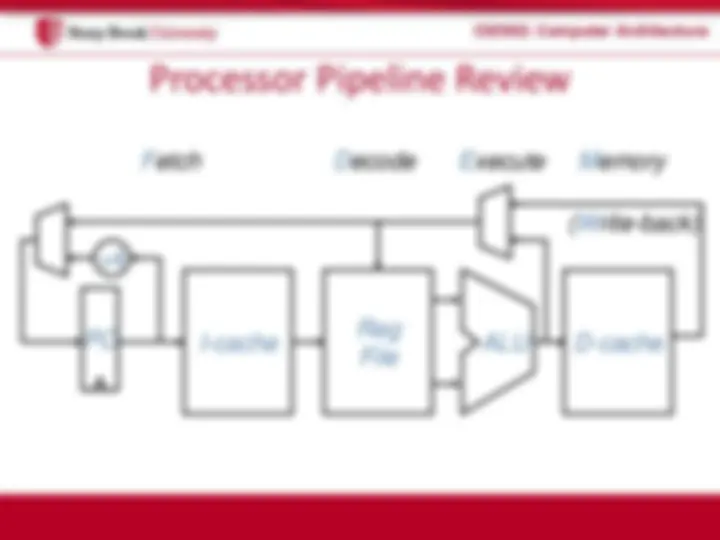
I-cache
Reg
File
PC
+ 4
ALU D-cache
Fetch Decode Memory
(Write-back)
Execute
Instruction
bits
Pipeline register
PC
Instruction
Cache
en
en
1
M
U
X
Decode
target
Pipeline register
regA contents
regB contents
ALU result
EX/Mem
Pipeline register
Control
signals Control
signals
PC+1+offset
regB contents
Decode Memory
destReg data
target
ALU result
Mem/WB
Pipeline register
ALUresult
EX/Mem
Pipeline register
Control
signals
PC+1+offset
regB contents
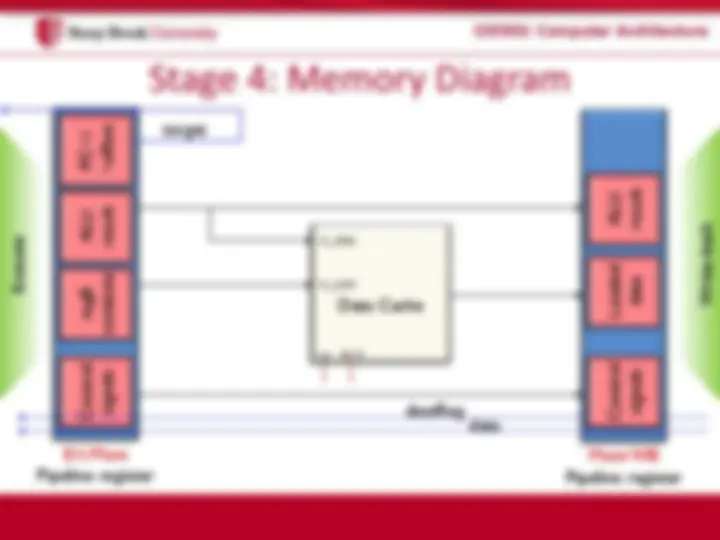
Loaded
Data Cache^ data
en R/W
in_data
in_addr
Control
signals
Execute
Write-back
destReg data
target
PC Inst
Cache Register file
M U X
A
L
U
1
Data Cache
M U X
IF/ID ID/EX EX/Mem Mem/WB
M U X
op
dest
offset
valB
valA
PC+1 PC+
target
ALU result
op
dest
valB
op
dest
ALU
result
mdata
instruction^ eq?
0
R R R R
R
R
R
R
regA regB
data
dest
M U X
Instruction Fetch
Instruction Decode
Operand Fetch
Instruction Execute
Write-back
TIF= 6 units
TID= 2 units
TID= 9 units
TEX= 5 units
TOS= 9 units
Tcyc TIF+TID+TOF+TEX+TOS
Tcyc max{TIF, TID, TOF, TEX, TOS}
ID
Can we do better?