



Pipelining Basics
Docsity.com



















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
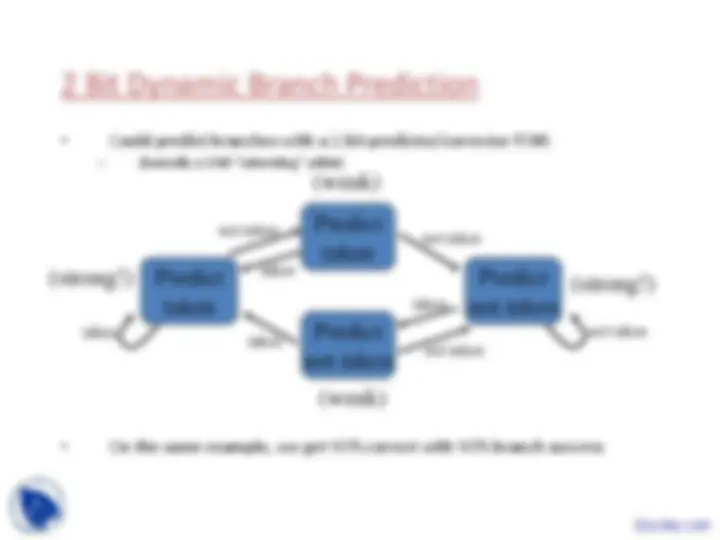
An overview of pipelining basics, including the 5 cycles in mips, pipelining history, performance possibilities, pipeline performance, and hazards. It covers the principles of pipelining, the benefits of pipelining, and the limitations and roadblocks to pipelining. The document also includes examples and solutions to control and data hazards.
Typology: Slides
1 / 28

This page cannot be seen from the preview
Don't miss anything!