Download Computer Architecture: Pipelining and Instruction Set Architecture - Prof. Edgar Gabriel and more Study notes Computer Architecture and Organization in PDF only on Docsity!
COSC 6385 – Computer ArchitectureEdgar Gabriel
COSC 6385
Computer Architecture
Edgar Gabriel
Fall 2006
Some of the slides are based on a lecture by David Culler,
University of California, Berkley
http://www.eecs.berkeley.edu/~culler/courses/cs252-s
COSC 6385 – Computer ArchitectureEdgar Gabriel
Instruction Set Architecture
Relevant features for distinguishing ISA’s
– Internal storage– Memory addressing– Type and size of operands– Operations– Instructions for Flow Control– Encoding of the IS
COSC 6385 – Computer ArchitectureEdgar Gabriel
Classes of instructions
ALU instructions
– Take either 2 registers as operands or 1 register and one
16bit immediate offset
– Results are stored in a 3
rd
register
Load and store instructions
Branches and jumps
COSC 6385 – Computer ArchitectureEdgar Gabriel
Typical implementation of an instruction
(I)
Instruction fetch cycle (IF):•
send PC to memory
Fetch current instruction
Update PC to next sequential PC (+4 bytes)
Instruction decode/register fetch cycle (ID)•
Decode instruction
Read registers corresponding to register source specifiersfrom register file
Sign extend offset fields if needed
Compute possible branch target address
COSC 6385 – Computer ArchitectureEdgar Gabriel
Typical implementation of an instruction
(III)
Memory
Access
Write
Back
Instruction
Fetch
Instr. Decode
Reg. Fetch
Execute
Addr. Calc
L MD
ALU
MUX
Memory
Reg File
MUX MUX
Data
Memory
MUX
Sign Extend
4
Adder
Zero?
Next SEQ PC
Next PC PC
WB Data
Inst
RS1 RS2 RD
Imm
Slide based on a lecture by David Culler,University of California, Berkleyhttp://www.eecs.berkeley.edu/~culler/courses/cs252-s
COSC 6385 – Computer ArchitectureEdgar Gabriel
Datapath (I)
4
Adder
PC
Readaddress
Instruction
memory
Instruction
Fetching instructions and incrementing program count (PC)
COSC 6385 – Computer ArchitectureEdgar Gabriel
Datapath (III)
Address
Data
memory
Load/Store instructions, e.g.
LW R1,offset (R2)
WriteData
Readdata
MemWrite MemRead
Sign Extend
16
32
Basic steps for a load/store operation• sign extend the offset from 16 to 32 bit• add the sign extended offset to R
- Load the content of the resulting address into R1 or• store the data from R1 into the resulting memory address
COSC 6385 – Computer ArchitectureEdgar Gabriel
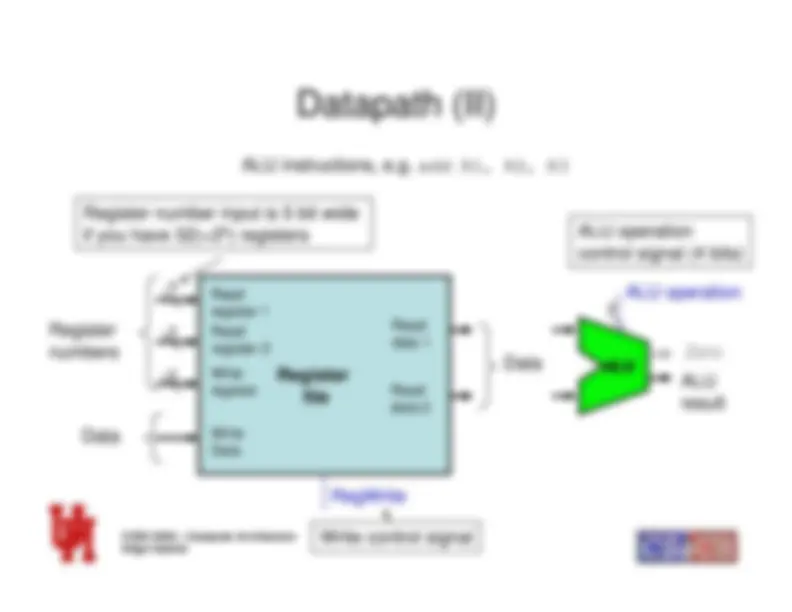
Datapath (IV)
Combining Load/Store and ALU instructions
Readregister 1
Register
file
Readregister 2WriteregisterWriteData
Readdata 1Readdata 2
RegWrite
Instruction
Sign Extend
16
32
MU X
0 1
ALU
4
Address
Data memory
WriteData
Readdata
MemWrite MemRead
ALUsrc
MU X
MemtoReg^01
ALU operation
COSC 6385 – Computer ArchitectureEdgar Gabriel
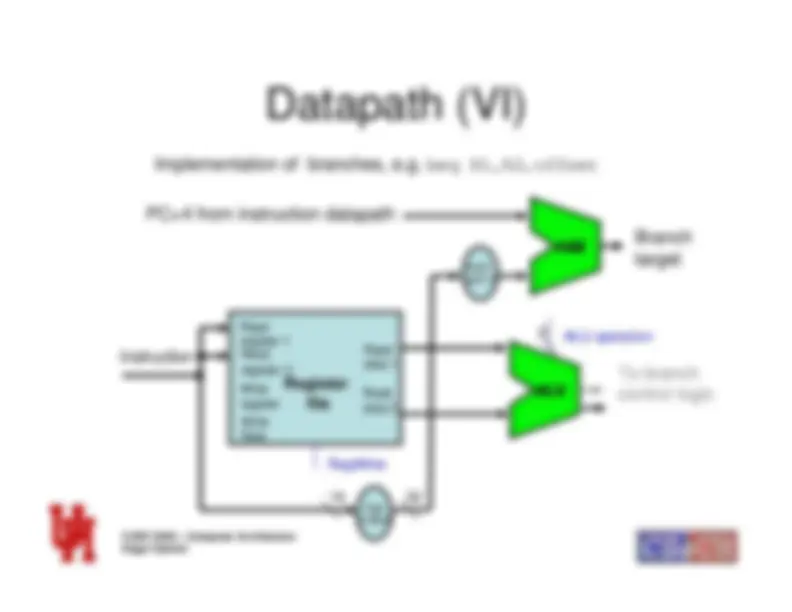
Datapath (VI)
Implementation of branches, e.g.
beq R1,R2,offset
Readregister 1
Register
file
Readregister 2WriteregisterWriteData
Readdata 1Readdata 2
RegWrite
Sign Extend
16
32
ALU
4
ALU operation
Instruction
To branchcontrol logic
ShiftLeft 2
Add
PC+4 from instruction datapath
Branchtarget
COSC 6385 – Computer ArchitectureEdgar Gabriel
Visualizing pipelining
I n s t r. O r d e r
Time (clock cycles)
ID
ALU
Mem
IF
WB
ID
ALU
Mem
IF
WB
ID
ALU
Mem
IF
WB
ID
ALU
Mem
IF
WB
Cycle 1 Cycle 2
Cycle 3
Cycle 4
Cycle 6 Cycle 7
Cycle 5
Slide based on a lecture by David Culler,University of California, Berkleyhttp://www.eecs.berkeley.edu/~culler/courses/cs252-s
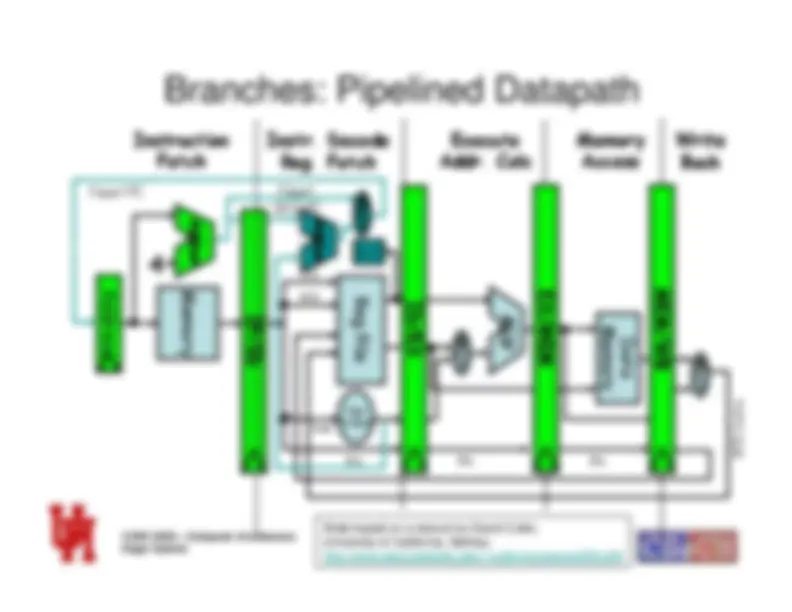
COSC 6385 – Computer ArchitectureEdgar Gabriel
Memory
Access
Write
Back
Instruction
Fetch
Instr. Decode
Reg. Fetch
Execute
Addr. Calc
ALU
Memory
Reg File
MUX MUX
Data
Memory
MUX
Sign Extend
Zero?
IF/ID
ID/EX
MEM/WB
EX/MEM
4
Adder
Next SEQ PC
Next SEQ PC
RD
RD
RD
Next PC
Address
RS1 RS
Imm
MUX
Slide based on a lecture by David Culler,University of California, Berkleyhttp://www.eecs.berkeley.edu/~culler/courses/cs252-s
COSC 6385 – Computer ArchitectureEdgar Gabriel
Pipeline Hazards
Limits to pipelining: Hazards prevent next instructionfrom executing during its designated clock cycle
– Structural hazards: HW cannot support this combination of
instructions
– Data hazards: Instruction depends on result of prior
instruction still in the pipeline
– Control hazards: Caused by delay between the fetching of
instructions and decisions about changes in control flow(branches and jumps).
Slide based on a lecture by David Culler,University of California, Berkleyhttp://www.eecs.berkeley.edu/~culler/courses/cs252-s
COSC 6385 – Computer ArchitectureEdgar Gabriel
One Memory Port/Structural Hazards
I n s t r. O r d e r
LoadInstr 1
Instr 2Stall
Instr 3
Reg
ALU
DMem
Ifetch
Reg
Reg
ALU
DMem
Ifetch
Reg
Reg
ALU
DMem
Ifetch
Reg
Cycle 1 Cycle 2
Cycle 3
Cycle 4
Cycle 6 Cycle 7
Cycle 5
Reg
ALU
DMem
Ifetch
Reg
Bubble
Bubble
Bubble
Bubble
Bubble
Slide based on a lecture by David Culler,University of California, Berkleyhttp://www.eecs.berkeley.edu/~culler/courses/cs252-s
COSC 6385 – Computer ArchitectureEdgar Gabriel
Speed Up Equation for Pipelining
pipelined
d
unpipeline
Time
Cycle
Time
Cycle
CPI
stall
Pipeline
CPI
Ideal
depth
Pipeline
CPI
Ideal
Speedup
×
×
=
pipelined
d
unpipeline
Time
Cycle
Time
Cycle
CPI
stall
Pipeline
1
depth
Pipeline
Speedup
×
=
Inst
per
cycles
Stall
Average
CPI
Ideal
CPI
pipelined
=
For simple RISC pipeline, CPI = 1:
Slide based on a lecture by David Culler,University of California, Berkleyhttp://www.eecs.berkeley.edu/~culler/courses/cs252-s