Download Machine Learning Map from Scikit-learn: Clustering Techniques and Evaluation and more Lecture notes Machine Learning in PDF only on Docsity!
COMP5310: Principles of
Data Science
W8: Clustering and
Dimensionality Reduction
Presented by Ali Anaissi
School of IT
Unsupervised Learning:
- We’ll focus on unsupervised machine learning techniques Association rule mining
- Dimensionality reduction
- Clustering
- Outlier detection
- Etc.
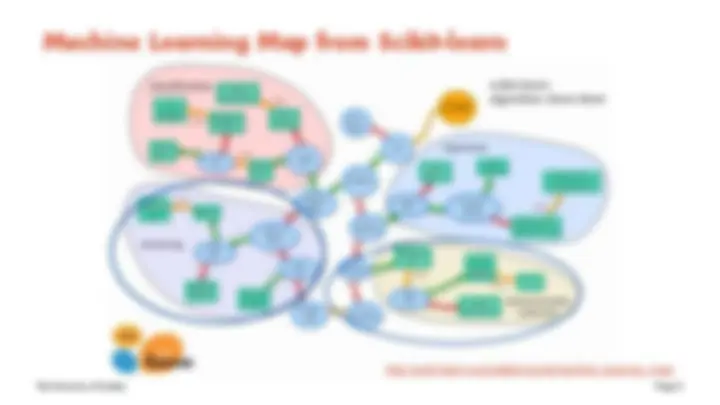
Machine Learning Map from Scikit-learn
http://scikit-learn.org/stable/tutorial/machine_learning_map/
Clustering: Group Similar Objects
- Group data points into clusters such that
- Data points in one cluster are more similar to one another.
- Data points in separate clusters are less similar to one another.
- Distance function specifies the “closeness” of two objects. Inter-cluster distances are maximized Intra-cluster distances are minimized
The University of Sydney Page 8
Similarity and Dissimilarity Between Objects
- Distances are normally used to measure the similarity or dissimilarity between two data objects
- Some popular ones include: Minkowski distance : where i = ( x i1, x i2, …, x ip) and j = ( x j1, x j2, …, x jp) are two p - dimensional data objects, and q is a positive integer
- If q = 1 , d is Manhattan distance q q p p q q j x i x j x i x j x i d ( i , j ) (| x | | | ... | | ) 1 1 2 2 ( , ) | | | | ... | | 1 1 2 2 p jp x i x j x i x j x i d i j x
Data Structures
- Data matrix n-observations with p-attributes (measurements).
- Dissimilarity matrix d(i,j) is the dissimilarity between objects i and j
- expresses the pairwise dissimilarities (distances) between observations in the data set
- the desired data input to some clustering algorithm ( , 1 ) ( , 2 ) ... 0 : : : ) ( 3 , 2 ) d n d n ... d(3,1 d 0 d(2,1) 0 0 attributes/dimensions tuples/objects objects objects x 11 ... x 1f ... x 1p ... ... ... ... ... x i ... x if ... x ip ... ... ... ... ... x n ... x nf ... x np é ë ê ê ê ê ê ê ê ê ù û ú ú ú ú ú ú ú ú
Clustering for Understanding
- Group related documents for browsing
- Group genes, proteins, or cells that have similar functionality
- Group stocks with similar price fluctuations
- etc
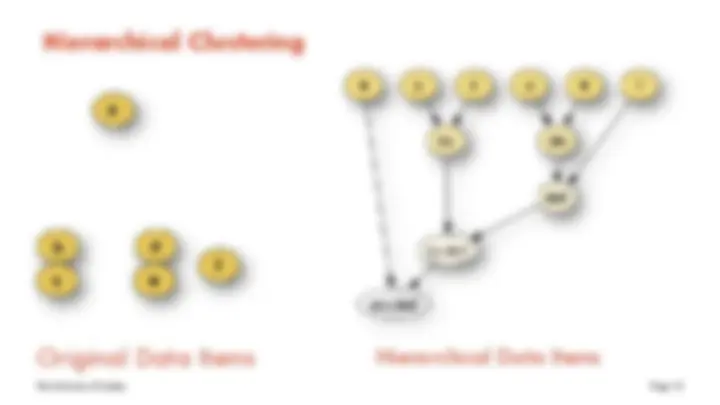
Hierarchical Clustering
Original Data Items Hierarchical Data Items
Hierarchical Clustering
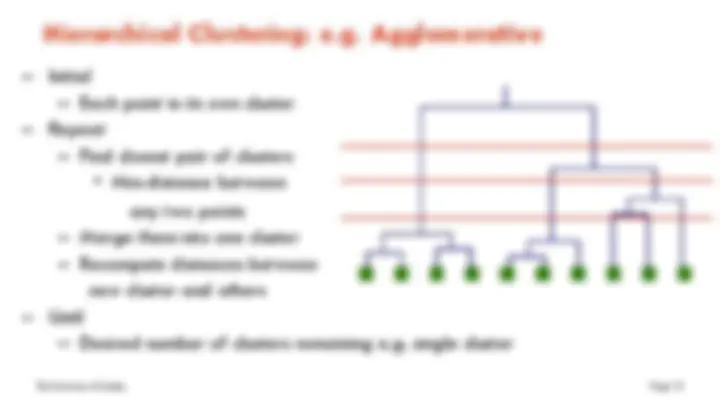
Strategies for hierarchical clustering generally fall into two types:
- Agglomerative : This is a "bottom up" approach: each object starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
- Divisive : This is a "top down" approach: all objects start in one cluster, and splits are performed recursively as one moves down the hierarchy.
Hierarchical Algorithm Steps in Hierarchical Algorithm:
- The first step generates the distance calculation matrix for each data item as shown in table below, in this case: {a}, {b}, {c}, {d}, {e}, {f}. a b c d e f a 0 184 222 177 216 231 b 184 0 45 123 128 200 c 222 45 0 129 121 203 d 177 123 129 0 46 83 e 216 128 121 46 0 83 f 231 200 203 83 83 0
Hierarchical Algorithm
- Next step is to merge the closest data items.
- In this case: {b , c} are merged.
- Therefore, the first clustering process generates: {a}, {b , c}, {d},{e},{f}. a b c d e f a 0 184 222 177 216 231 b 184 0 45 123 128 200 c 222 45 0 129 121 203 d 177 123 129 0 46 83 e 216 128 121 46 0 83 f 231 200 203 83 83 0 a b,c d e f a (^0)? 177 216 231 b,c? 0??? d 177? 0 46 83 e 216? 46 0 83 f 231? 83 83 0
Hierarchical Algorithm with Single Linkage
– Repeat the distance calculation process based on single linkage
– Apply merging process based on previous merge results.
– In this case: {d , e} are merged.
– The final results are: {a}, {b, c} {d, e} {a}, {b, c}, {d, e, f}
{a}, {b, c, d, e, f} {a, b, c, d, e, f}
a b c d e f a 0 184 222 177 216 231 b 184 0 45 123 128 200 c 222 45 0 129 121 203 d 177 123 129 0 46 83 e 216 128 121 46 0 83 f 231 200 203 83 83 0 a b, c d e f a 0 184 177 216 231 b, c 184 0 123 121 200 d 177 123 0 46 83 e 216 121 46 0 83 f 231 200 83 83 0
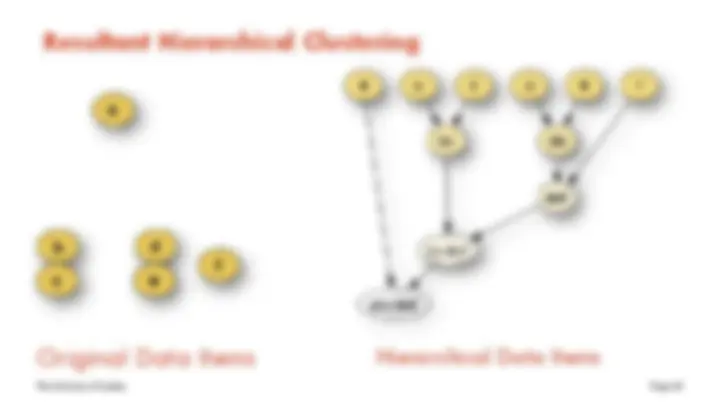
Resultant Hierarchical Clustering
Original Data Items Hierarchical Data Items