Download Protein Structure Prediction - Lecture Notes | CMSC 838 and more Study notes Computer Science in PDF only on Docsity!
CMSC 838T – Lecture 6
CMSC 838T – Lecture 6
X Protein structure prediction
0 Predict protein 3D structure from (amino acid) sequence 0 One step closer to useful biological knowledge 0 Sequence → secondary structure → 3D structure → function
5' atgcccaagctgaat … 3'
atg ccc aag ctg aat …
M P K L N …
Protein Structure Prediction
X Protein structure
0 Assume in most cases, 3D structure → biological function O Lock & key model of enzyme function (docking) 0 Folding problem: protein sequence ⇔ 3D structure 0 Structure prediction → protein design, drug design, etc … 0 The “holy grail” of bioinformatics
X Prediction is possible because
0 Sequence information uniquely determines 3D structure 0 Sequence similarity (>50%) tends to imply structural similarity
X Prediction is necessary because
0 DNA sequence data » protein sequence data » structure data
CMSC 838T – Lecture 6
Protein Structure Prediction & Alignment
X Protein structure
0 Interatomic forces 0 Secondary structure 0 Tertiary structure
X Structure prediction
0 Secondary structure 0 3D structure O Ab initio O Comparative modeling O Threading
X Structure alignment
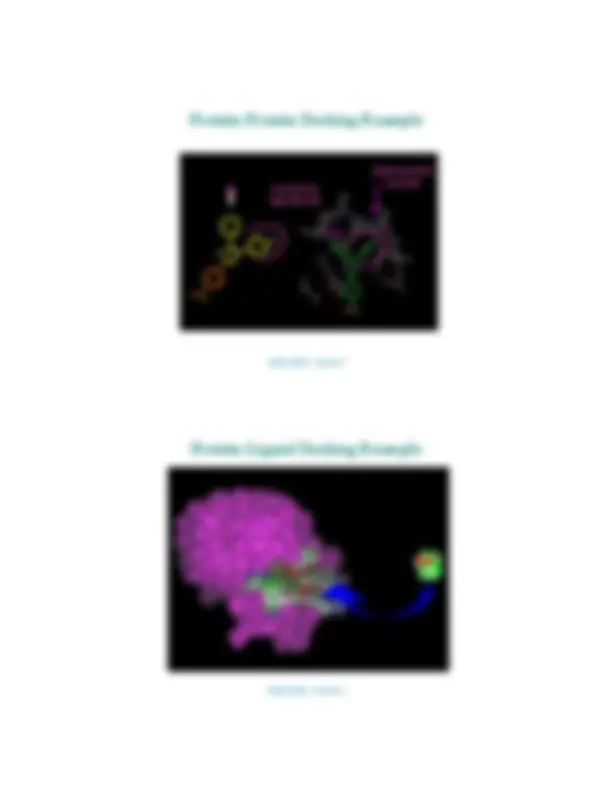
0 3D structure alignment 0 Protein docking
Amino Acid (AA.) – Structure & Residues
X Basic structure
X 20 residues
0 Residues can share similar biochemical properties
CMSC 838T – Lecture 6
Inter-atomic Forces
X Hydrophobic / hydrophillic interaction (weak)
0 Hydrogen bonding w/ H 2 O in solution O Non-polar residues interfere (hydrophobic) O Polar residues participate (hydrophillic) 0 Main cause of globular 3D protein → protect hydrophobic core
X Charge-charge, charge-dipole, dipole-dipole (weak)
0 Electrostatic attractive force
X Van der Waal’s interaction (very weak)
0 Nonspecific electrostatic attractive force 0 From transitive attractions between instantaneous dipoles
X Steric interaction (very short range, very strong)
0 Repulsive force between atomic nuclei
Types of Inter-atomic Forces
Covalent Bond
van der Waal Interaction
Hydrogen Bond
Charge-charge Interaction
Negative Charge
Positive Charge
No Charge
Atoms &
H 2 O Molecules
C=O NH SH, SH → S S
Disulfide Bond / Bridge
CMSC 838T – Lecture 6
Inter-atomic Forces – Hydrophobicity Plot
X Hydrophobicity
0 Meaningful in context of protein sequence region 0 Hydrophobicity plot → track local hydrophobic residues 0 Many local hydrophobic residues → hydrophobic region
Human tumor antigen p (window = 19 residues)
Inter-atomic Forces – Lennard-Jones Potential
X Forces
0 Van der Waal’s (attractive, far) 0 Steric interaction (repulsive, close)
X Lennard-Jones
0 Plot of pair potential energy vs. distance 0 Local minima (energy well) is stable distance for two atoms Distance → Potential energy
CMSC 838T – Lecture 6
Proteins – Secondary Structure
X α-helix (30-35%)
0 Hydrogen bond between C=O (carbonyl) & NH (amine) groups within strand (4 positions apart) 0 3.6 residues / turn, 1.5 Å rise / residue 0 Typically right hand turn 0 Most abundant secondary structure 0 α-helix formers: A,C,L,M,E,Q,H,K
X β-sheet / β-strand (20-25%)
0 Hydrogen bond between groups across strands 0 Forms parallel and antiparallel pleated sheets 0 Amino acids less compact – 3.5 Å between adjacent residues 0 Residues alternate above and below β-sheet 0 β-sheet formers: V,I,P,T,W
Proteins – Parallel & Antiparallel β -sheet
CMSC 838T – Lecture 6
Proteins – Secondary Structure
X Coil (40-50%)
0 Generally speaking, anything besides α-helix, β-sheet, β-turn
X β-turn
0 Short turn (4 residues) 0 Hydrogen bond between C=O & NH groups within strand (3 positions apart) 0 Usually polar, found near surface 0 β-turn formers: S,D,N,P,R
X Loop
0 Regions between α-helices and β-sheets 0 On the surface, vary in length and 3D configurations 0 Do not have regular periodic structures 0 Loop formers: small polar residues
Proteins – Secondary Structure
X Properties
0 Secondary structure is very context-dependent O Relies on substructures in nearby environment O β-sheet stabilized by hydrogen bonds w/ other β-sheet O α-helix more stable on its own 0 Prediction is difficult
X Uses
0 Can help predict 3D protein structure O Intermediate step in prediction O Use topology of secondary structures to predict 3D 0 Can help model protein folding process O Sequences first form secondary structures as frame O 3D structure formed by attaching substructures to frame
CMSC 838T – Lecture 6
Proteins – Structural Classes
X SCOP classification results
0 Protein Data Bank (PDB) version 1.61, September 2002 0 17406 entries, 44327 domains
Class folds superfamilies families
Class α 151 257 409
Class β 111 213 362
Class α / β 117 190 467
Class α + β 212 308 488
Multidomain 39 39 52
Membrane 12 19 34
Small proteins 59 84 128
Total 701 1110 1940
Proteins – Tertiary Structures
X Overall 3D structure
0 Globular 0 Membrane
X Globular core
0 Hydrophobic 0 Closely packed 0 Limited substitutions
X Globular surface
0 Loops 0 Hydrophillic (usually >70%) 0 Contact with other molecules 0 More flexibility in substitutions
Hydrophobic core
Hydrophillic surface
Globular protein
CMSC 838T – Lecture 6
Proteins – Tertiary Structures
X Myoglobin example
Protein Structure → Function
X Hemoglobin
0 Oxygen transport
X Porin
0 Transmembrane transport
CMSC 838T – Lecture 6
Methods for Predicting Secondary Structure
X Sequence-based vs. alignment-based
0 Can use individual or multiple sequence alignment (MSA) O Predict structure based on profile / consensus alignment
X Statistical approaches
0 Lim – rules based on physicochemical nature of residues 0 Chou-Fasman – residue frequency statistics (6 AA window) 0 GOR – pairwise residue frequency statistics (17 AA window)
X Neural network approaches
0 PHDsec – combines results from different neural networks 0 PSIPRED – combines neural network with PSI-BLAST result
X Consensus approach
0 JPRED – combine multiple prediction tools with MSA
Prediction – Sequence vs. Alignment
X Single sequence
0 Examine single protein sequence 0 Base prediction on O Statistics – composition of amino acids O Neural networks – patterns of amino acids
X Multiple sequence alignment [Zvelebil+ 1987, Levin+ 1993]
0 First create MSA O Use sequences from PSI-BLAST, CLUSTALW, etc… O Align sequence with related proteins in family 0 Predict secondary structure based on consensus / profile 0 Generally improves prediction 8-9%
CMSC 838T – Lecture 6
Predicting Secondary Structure
X Assumptions
0 Amino acid sequence is sufficient information 0 Residues determine secondary structure 0 Examining small windows of 13 – 17 residues is sufficient 0 Finds α-helices, β-sheet, β-turn; everything else → coil
Secondary Structure – Statistical Prediction
X Prediction based on
0 Statistics of local residue interactions within sliding window O Considers nearby residues
T S P T A E L M R S T G
T S P T A E L M R S T G
T S P T A E L M R S T G
T S P T A E L M R S T G
0 Secondary structural state of the central residue O Consider current predicted structure
window size = 6
CMSC 838T – Lecture 6
Chou-Fasman Example
X Assign parameters to sequence
X Identify α-helix candidate regions (4 of 6 P(α-helix) > 100)
T S P T A E L M R S T G
P(H) 69 77 57 69 142 151 121 145 98 77 69 57 P(E) 147 75 55 147 83 37 130 105 93 75 147 75 P(turn) 114 143 152 114 66 74 59 60 95 143 114 156
T S P T A E L M R S T G
P(H) 69 77 57 69 142 151 121 145 98 77 69 57
T S P T A E L M R S T G
P(H) 69 77 57 69 142 151 121 145 98 77 69 57
Chou-Fasman Example
X Extend α-helix region
0 Until average P(α-helix) <100 for 4 contiguous amino acids
X Identify β-sheet candidate regions (3 of 5 P(β-sheet) > 100)
T S P T A E L M R S T G
P(H) 69 77 57 69 142 151 121 145 98 77 69 57
T S P T A E L M R S T G
P(H) 69 77 57 69 142 151 121 145 98 77 69 57 P(E) 147 75 55 147 83 37 130 105 93 75 147 75
CMSC 838T – Lecture 6
Secondary Structure – Statistical Prediction
X GOR [Garnier, Osguthorpe & Robson 1978]
0 Build on Chou-Fasman P values 0 Assumes residues outside central region affect structure 0 Evaluates interaction of residue with 16 adjacent residues 0 Use 17 × 20 scoring matrix (17 residues, 20 amino acids) to calculate probability of α-helix, β-sheet, β-turn, coil
X GOR IV [Garnier+ 1996]
0 Predicts α-helix, β-sheet, coil 0 Also uses 17 residue sliding window 0 Calculates probabilities for all N (N-1) / 2 paired positions O Considers correlation between residues 0 Post-processing for α-helix, β-sheet minimum lengths
Secondary Structure – Statistical Prediction
X PREDATOR [Frishman & Argos 1996]
0 Predictions based on combination of O Amino acid population statistics for α-helix, β-sheet O Long-range interactions (hydrogen bonding) X Within strand – α-helix (N, N+4) X Between strands – β-sheet (statistics) 0 Use statistics on residues for hydrogen bonds in β-sheets 0 For multiple sequences O Uses pairwise local alignment to query sequence (instead of multiple sequence alignment)
CMSC 838T – Lecture 6
Secondary Structure – Neural Networks
X Jury decisions
0 Use multiple neural networks & combine results O Average output O Majority decision Input
Output
Secondary Structure Prediction
X JPRED [Cuff+ 1998]
0 Finds consensus from PHD, PREDATOR, DSC, NNSSP, etc…
: 1---------11--------21--------31-: OrigSeq : ASYKVTLKTPDGDNVITVPDDEYILDVAEEEGL: cons : --EEEEEE-----EEEE----HHHHHHHHH---: dsc : ---EEEEE------EEE-----HHHHHHHH---: mul : --EEEEEE-------EE-----HHHHHHHH---: nnssp : --EEEEEE-----EEEE----HHHHHHHHH---: phd : --EEEEEEE----EEEE---HHHHHHHHHH---: pred : ---EEEE------EEEE-----HHHHHHHH---: zpred : HHHEEEEE-------EE---HHHHHHHHHHH--: dssp : --EEEEEEE--EEEEEEE-----HHHHHHHH--: define : EEEEEEEE---EEEEEE-----HHHHHHHHHHE: stride : -EEEEEEEE--EEEEEEEE----HHHHHHHH--:
E → β-strand H → α-helix
CMSC 838T – Lecture 6
Predicting Secondary Structure
X Accuracy
0 Random guess (for 30% α-helices, 20% β-sheet) = 40% 0 Sequence-based: Chou-Fasman 50%, GOR 53%, GOR IV 64% 0 Alignment-based: PHD 71%, PREDATOR 75%, PSIPRED 77% 0 More accurate for α-helices than β-sheet
X Observations
0 Secondary prediction is very difficult 0 Accuracy seems to be reaching limits 0 Absolute accuracy may not be necessary 0 Focus on usage of secondary structure prediction instead O Using secondary structure motifs to predict 3D structure
Additional (Similar) Prediction Techniques
X Other secondary protein structures
0 Transmembrane helices O 20-30 residues with strong hydrophobicity 0 Coiled coils O 2-3 α-helices coiled around each other in supercoil 0 Leucine zippers O Antiparallel α-helices held together by L interactions O Leucine residues spaced every 7 amino acids
X RNA secondary structure
0 Strands, stems, hairpin / interior / bulge loops, knots, etc…
0 Useful since some RNA perform protein-like functions