Download Query Processing Algorithms - Database Systems Implementation | CS 4420 and more Study notes Computer Science in PDF only on Docsity!
1
CS 4420 Database System Implementation
Query Optimization
Recovery
Ling Liu Associate Professor College of Computing, Georgia Tech
DB
Lecture Outline
Query Optimization (final remarks)
z Architectures z Complexity and general methodology
Failure Recovery
z Database Consistency and Constraints z Consistent Database State and Transactions z Undo logging z Redo logging (next lecture) z Undo/Redo logging (next lecture) z Checkpoints (next lecture)
3
Query Optimization
Query Processing Algorithms
z Iterative Approach (nested loop) z Sort-based z Hash-based z Index-based
Query Optimization Architecture
z Pipelining
z Materialization
DB
Pipelining
Many operations (or certain implementations of
them) allow us to use pipeline
z To accept one or both arguments in a stream without seeing the entire relation before starting
Materialization
z When pipelining is not possible, then the arguments must be materialized (sorted on disk if it is large), before beginning the processing
7
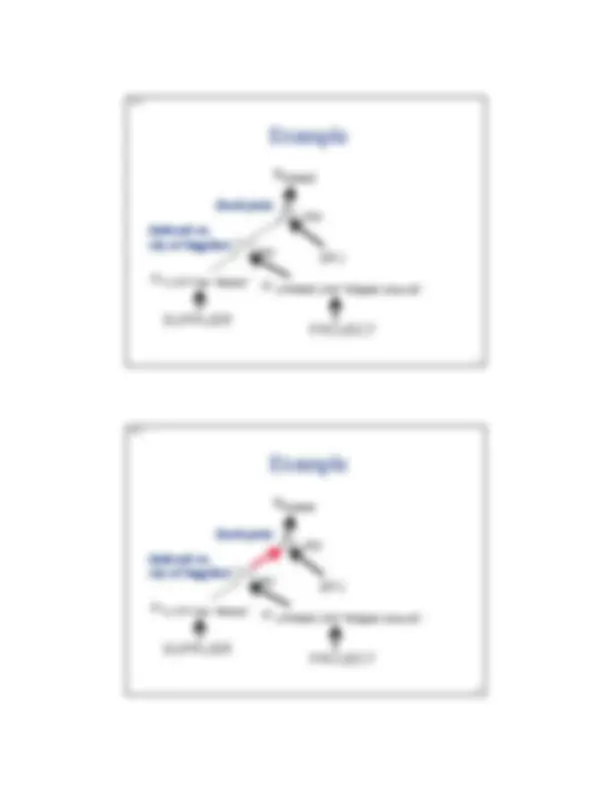
Example
σ J.PNAME LIKE “%Digital Library%”
πSNAME
SUPPLIER
SPJ
PROJECT
city
σ S.CITY like “Atlanta”
city
(indexed on city of Supplier)
(hash-join)
DB
Example
σ J.PNAME LIKE “%Digital Library%”
πSNAME
SUPPLIER
SPJ
PROJECT
city
σ S.CITY like “Atlanta”
city
(hash-join)
(indexed on city of Supplier)
9
Query Processing Methodology
High-level Calculus-based Query (SQL)
Query Preprocessing
Query Preprocessing
Query Optimization
Query Optimization
Algebraic Query (a tree structure) LOGICAL SCHEMA
LOGICAL SCHEMA
INTERNAL SCHEMA
INTERNAL SCHEMA Execution Schedule (file access plan)
EXTERNAL SCHEMA
EXTERNAL SCHEMA
DB
Not really optimizing, but planning to avoid
bad execution strategies
Models
z Heuristics-based (Algebraic Rewriting and Algebraic Transformation) ÆApply transformation rules according to a general strategy z Cost-based ÆMinimize a cost function I/O cost + CPU cost subject to a set of constraints
Query Optimization
13
Algebraic Transformation
πENAME
σW.RESP = "Manager“
E.ENO = W.ENO
E
Moving selection downward (using Cascade of selections, Commutativity of selections, and Commuting selection with binary operations)
W
Strategy 2
Plan 3
DB
Algebraic Transformation
πENAME
σW.RESP = "Manager“
E.ENO = W.ENO
E
W
πENAME
σW.RESP = "Manager“
E.ENO = W.ENO
E
W
Plan 3 Plan 4
Strategy 2 (two possible plans)
15
Example SELECT ENAME FROM E,W WHERE E.ENO = W.ENO AND W.RESP = "Manager" Strategy 1 (Algebraic rewriting) z πENAME (σRESP="Manager"∧E.ENO=G.ENO (E × W)) z πENAME (σRESP="Manager"∧E.ENO=G.ENO (W × E))
Strategy 2 (algebraic transformation) z πENAME ( E (^) ENO (σRESP="Manager"(W))) z πENAME (σRESP="Manager"(W) (^) ENO E)
Query Optimization: An Example
Different join ordering
Different join ordering
DB
Assume : z card (E) = 4,000; card(W)=10, z 10% of tuples in W satisfy RESP="Manager" (selection generates 1,000 tuples) (i.e., V(W, RESP) = 10) z No index on either E or W execution time proportional to the sum of the cardinalities of the temporary relations (join cost dominates the overall cost) searching is done by sequential scanning Strategy 1 Strategy 2 Cartesian prod. = 40,000,000 Selection over W = 10, Search over all = 40,000,000 Join(4000*1000) = 4,000, 80,000,000 4,010,
Cost of Alternatives
19
Search Strategies
z exhaustive search v.s Heuristics
Optimization granularity
z Single query v.s. multiple queries
Optimization timing
z Compile time v.s. run time
Query Optimization Issues
DB
Search Strategies
z exhaustive search
Æ“optimal” Æcombinatorial complexity in the number of relations Æcost-based
z heuristics
Ænot optimal Ægroup common sub-expressions Æperform selection, projection first Æreorder operations to reduce intermediate relation size Æoptimize individual operations
Query Optimization Issues
21
Optimization granularity
z single query at a time
Æcan not use common intermediate
results
z multiple queries at a time
Æefficient if many similar queries
Ædecision space is much larger
Query Optimization Issues
DB
Optimization timing
z static Æ compilation ⇒ optimize prior to the execution Æ difficult to estimate the size of the intermediate results ⇒ error propagation Æ can amortize over many executions z dynamic Æ run time optimization Æ exact information on the intermediate relation sizes Æ have to reoptimize for multiple executions z hybrid Æ compile using a static algorithm Æ if the error in estimate sizes > threshold, reoptimize at run time
Query Optimization Issues