Download Random Error - Quantitative Analysis - Lecture Slides and more Slides Analytical Chemistry in PDF only on Docsity!
Random Error
The Nature of Random Errors
Random, or indeterminate, errors occur whenever a
measurement is made. This type of error is caused by the
many uncontrollable variables that are an inevitable part of
every physical or chemical measurement. There are many
contributors to random error, but often we cannot
positively identify or measure them because they are small
enough to avoid individual detection. The accumulated
effect of the individual random uncertainties, however,
causes the data from a set of replicate measurements to
fluctuate randomly around the mean of the set.
Three dimensional plot showing absolute error
Frequency distribution
Range of measured values, mL
Sources of Random Errors
Sources of random uncertainties in the calibration of a pipet include (1) visual judgments, such as the level of the water with respect to the marking on the pipet and the mercury level in the thermometer; (2) variations in the drainage time and in the angle of the pipet as it drains; (3) temperature fluctuations, which affect the volume of the pipet, the viscosity of the liquid, and the performance of the balance; and (4) vibrations and drafts that cause small variations in the balance readings. Undoubtedly, numerous other sources of random uncertainty also operate in this calibration process. It is difficult or impossible to determine the influence of any one of the random errors arising from these variables, but the cumulative effect is responsible for the scatter of data points around the mean.
Normal error curves
Samples and Populations
A finite number of experimental observations is
called a sample of data. The sample is treated as a
tiny fraction of an infinite number of observations
that could in principle be made given infinite time.
Statisticians call the theoretical infinite number of
data a population , or a universe , of data. Statistical
laws have been derived assuming a population of
data; often, they must be modified substantially
when applied to a small sample because a few data
points may not be representative of the population.
…continued…
To emphasize the difference between the two
means, the sample mean is symbolized by x and
the population mean by . When N is small, x
differs from because a small sample of data does
not exactly represent its population. The probable
difference between x and decreases rapidly as
the number of measurements making up the
sample increases; ordinarily, by the time N reaches
20 to 30, this difference is negligibly small.
The Population Standard Deviation( )
The population standard deviation , which is a measure of
the precision or scatter of a population of data, is given by the equation
where, N is the number of data points making up the population.
The two normal error curves in Fig. 6-4 are for two populations of data that differ only in their standard deviations. The standard deviation for the data set yielding the broader but lower curve B is twice that for the measurements yielding curve A. the breadth of these curves is a measure of the precision of the two sets of data. Thus, the precision of the data leading to curve A is twice as good as that of the data that are represented by curve B.
x
N
i i
N
1
2
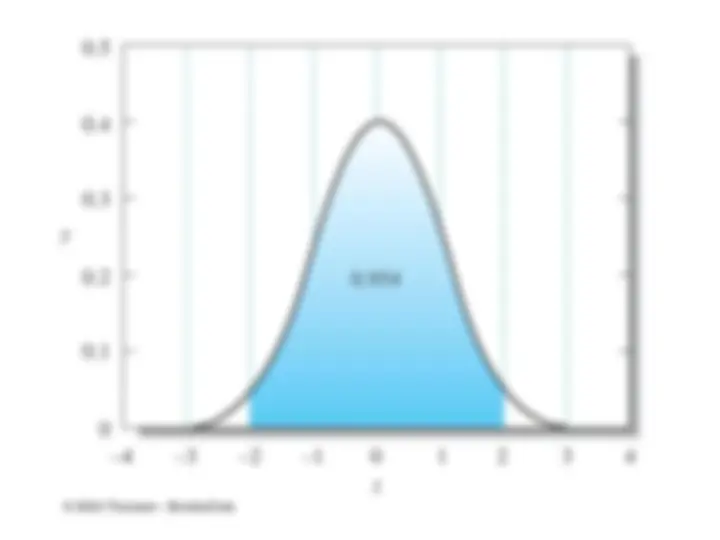
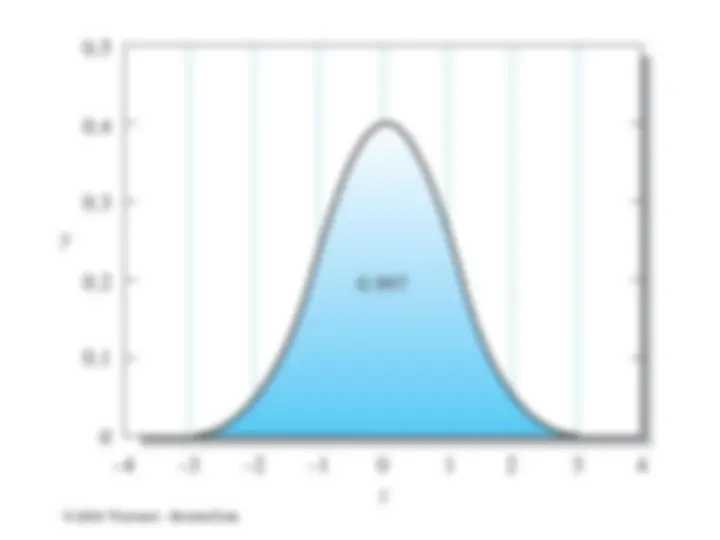
Areas under a Gaussian Curve
It can be shown that, regardless of its width,
68.3% of the area beneath a Gaussian curve for
a population of data lies within one standard
deviation ( 1 ) of the mean . Thus, 68.3% of
the data making up the population will lie
within these bounds. Furthermore,
approximately 95.4% of all data points are
within 2 of the mean and 99.7% within 3 .
Sample Standard Deviation
Standard Deviation equation must be modified when it is applied to a small sample of data. Thus, the sample standard deviation s is given by the equation
This equation differs from the standard deviation equation in two ways. First, the sample mean, x, appears in the numerator of sample standard deviation equation in place of the population mean, . Second, N in standard deviation equation is replaced by the number of degrees of freedom (N – 1).
The sample variance s^2 is also of importance in statistical calculations. It is an estimate of the population variance ^2.
x^ x
N
d
N
i i
N i i
N
1 1 1 1
(^22)
_