Download Recommendation systems and more Slides Computer science in PDF only on Docsity!
Content-Based Recommender
Systems
UNIT II: Basic Components of Content-Based
Systems, Pre-processing and Feature
Extraction, Learning User Profiles and
Filtering, Nearest Neighbor Classification.
Core Functionality of Content-Based Systems:
- (^) Match users to items similar to what they have liked in the past using item attributes rather than ratings correlations.
- (^) Leverage two main data sources:
- (^) Item Descriptions: Content-centric attributes , such as keywords, genre, and manufacturer.
- (^) User Profiles: Built from explicit (ratings) or implicit (actions) feedback, or specified keywords of interest.
Advantages of Content-Based Systems:
- (^) Effective in cold-start scenarios for items (new items with no user ratings).
- (^) Suitable for text-rich and unstructured domains , like web pages and product descriptions.
- (^) Personalized recommendations based solely on the user’s past interactions. Disadvantages of Content-Based Systems:
- (^) Limited diversity and novelty in recommendations , as items are often too similar to past preferences.
- (^) Struggles with the cold-start problem for new users , as it requires prior user interaction data.
- (^) Recommendations may lack surprise or creativity.
Relation to Knowledge-Based Systems:
- (^) Both systems use content attributes for recommendations.
- (^) Differences:
- (^) Knowledge-based systems allow explicit specification of user requirements and interactive interfaces.
- (^) Content-based systems rely on past user behavior using learning-based approaches. Hybrid Systems:
- (^) Combine content-based and collaborative methods to address the limitations of each approach.
- (^) Provide a unified framework for leveraging both learning- based and interactive aspects of recommendations.
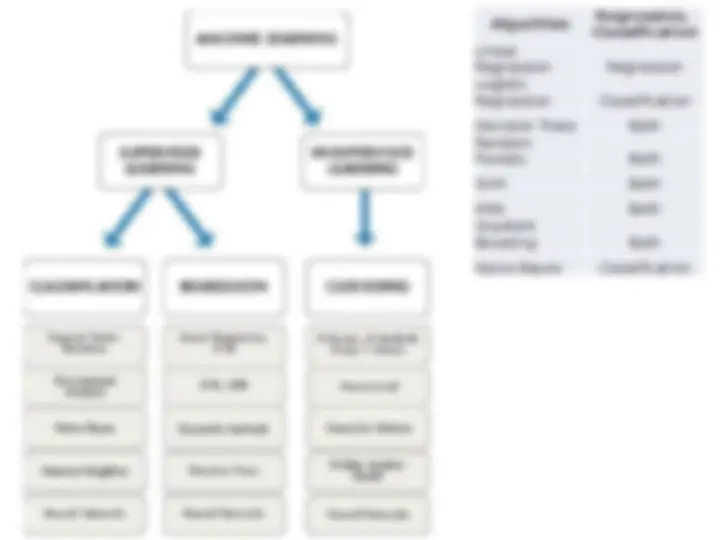
Basic Components of Content-Based Systems General Characteristics:
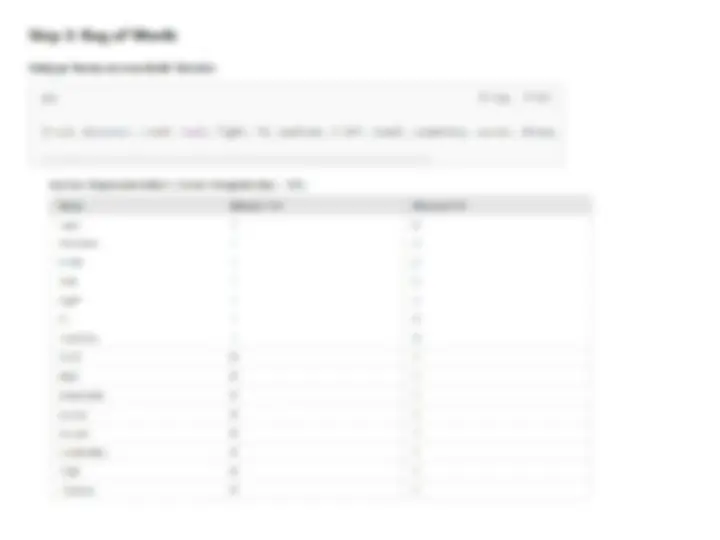
- (^) Content-based systems convert unstructured data into standardized descriptions , often keyword- based vector-space representations.
- (^) These systems largely operate in the text domain and are commonly used in applications like news recommendation systems.
- (^) Text classification and regression modeling are the primary tools for content-based recommenders.
- (^) Use classification (for categorical feedback) or regression (for numerical feedback) to relate user interests to item attributes.
- (^) Filtering and Recommendation:
- (^) Use the learned model to generate recommendations for users in real-time.
- (^) Efficiency is crucial since predictions need to be performed quickly.
Model Utilization:
- (^) Classification models are commonly used in the learning phase.
- (^) Content-based systems can use these models as black- box components, focusing on how they relate user profiles to item attributes. Additional Notes:
- (^) The learning phase is often based on well-known classification or regression techniques.
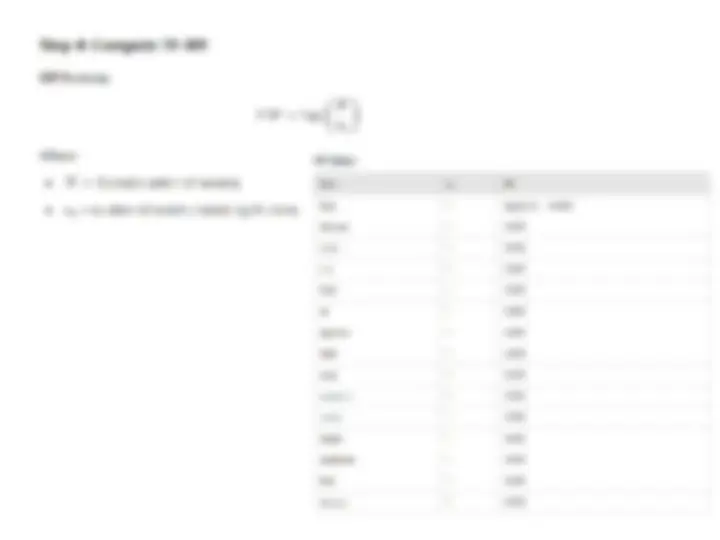
Preprocessing and Feature Extraction
- (^) General Overview:
- (^) The first phase in content-based systems is extracting discriminative features to represent items effectively.
- (^) Discriminative features are predictive of user interests and vary based on the application (e.g., product recommendation vs. web pages).
Feature Weighting:
- (^) Assign different levels of importance to attributes.
- (^) Approaches:
- (^) Domain-Specific Knowledge: Heuristics to decide keyword weights (e.g., title and main actor in movies).
- (^) Automated Methods: Learn feature weights algorithmically (closely related to feature selection).
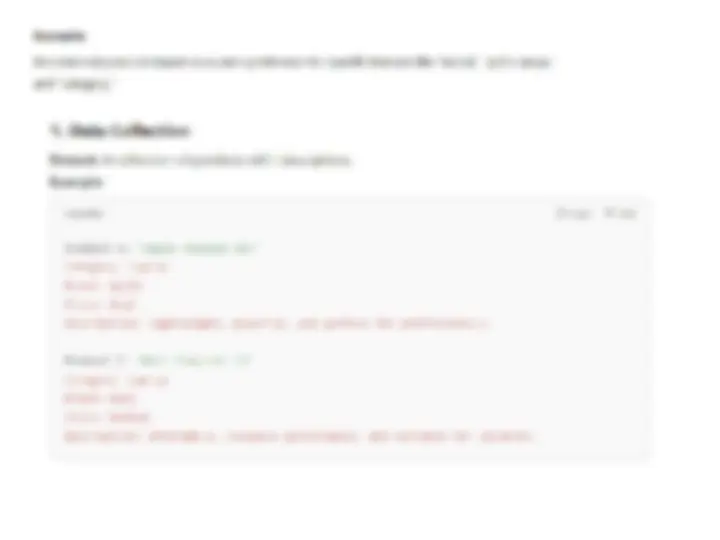
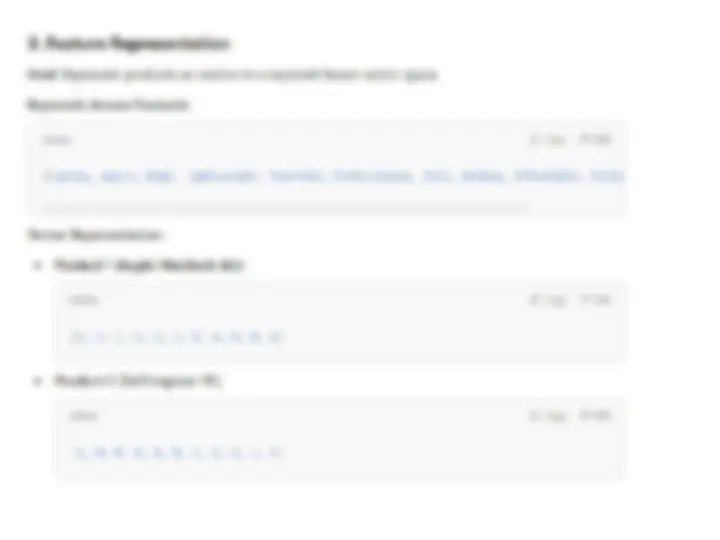
Examples of Feature Extraction in Various Applications:
- (^) Product Recommendation (e.g., IMDb):
- (^) Attributes include movie synopsis, director, actors, and genre.
- (^) Example: For the movie Shrek , attributes like "ogre," "princess," and "magical creatures" form the keyword set.
- (^) Importance of features (e.g., actors vs. synopsis) can be determined using: - (^) Domain-Specific Knowledge: Weight features like title or primary actor higher. - (^) Automated Methods: Use feature weighting or selection algorithms.
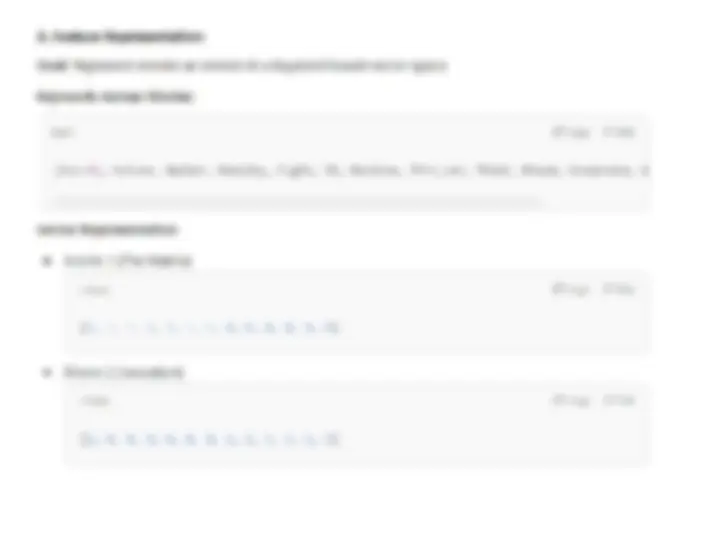
Music Recommendation (e.g., Pandora):
- (^) Features are extracted from the Music Genome Project , including attributes like: - (^) “Trance roots,” “synth riffs,” “tonal harmonies,” “straight drum beats.”
- (^) Users create a "station" by specifying one track, and similar songs are recommended.
- (^) User feedback (likes/dislikes) refines recommendations over time.
- (^) Keywords or structured attributes (e.g., genres or beats) form the basis for recommendation.