


RL Cont’d













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An introduction to reinforcement learning (rl), focusing on policies, value functions, and markov decision processes. Rl is a type of machine learning where an agent learns to make decisions by interacting with its environment. The total accumulated reward depends on the agent's starting point, actions, and the policy it follows. The policy defines what action to take in every state. Experience and histories are essential in rl, with an experience tuple consisting of the state, action, reward, and next state. The document also discusses finite horizon reward, infinite horizon reward, uncertainty of outcomes, and transition functions.
Typology: Study notes
1 / 21

This page cannot be seen from the preview
Don't miss anything!
Total accumulated reward ( value , V ) depends on
Where agent starts
What agent does at each step (duh)
Plan of action is called a policy , π
Policy defines what action to take in every state of the system:
Value is a function of start state and policy:
π
Assuming that an episode is finite:
Agent acts in the world for a finite number of time steps, T , experiences history h T
What should total aggregate value be?
Assuming that an episode is finite:
Agent acts in the world for a finite number of time steps, T , experiences history h T
What should total aggregate value be?
Total accumulated reward :
Occasionally useful to use average reward :
T
t=
T
t=
Let
be an infinite history
We define the infinite-horizon discounted value to be:
where is the discount factor
Q1: Why does this work?
Q2: if R max is the max possible reward attainable in the environment, what is V max
∞
t=
t
Consider:You can go to one of two startups:
SplatSoft Inc. (makes game software)
Might win big:
R (survives) = $15 Mil , Pr[survives]=0.
Might tank:
R (tanks) =- $0.25 Mil , Pr[tanks]=0.
Google Inc. (makes some web software)
Might win big:
R (survives) = $2 Mil , Pr[survives]=0.
Might tank:
R (tanks) = $-0.5 Mil , Pr[tanks]=0.
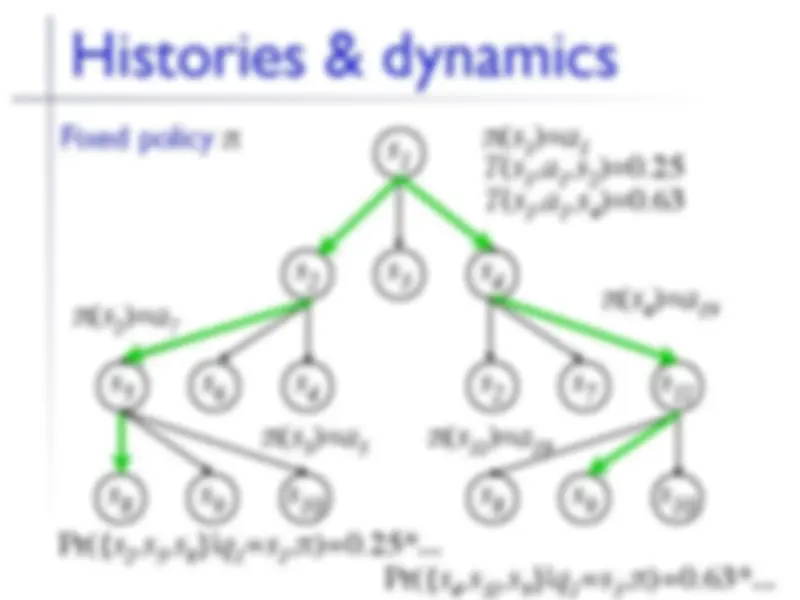
s 1 s 2 s 3 s 4 s 5 s 6 s 4 s 2 s 7 s 11 s 8 s 9 s 10 s 8 s 9 s 10 Fixed policy π π ( s 1 )= a 1 π ( s 2 )= a 7 π ( s 4 )= a 19 π ( s 5 )= a 3 π ( s 11 )= a 19 T ( s 1 , a 1 , s 2
T ( s 1 , a 1 , s 4
Pr({ s 2 , s 5 , s 8 }| q 1 =s 1 , π ) = 0.25 *... Pr({ s 4 , s 11 , s 9 }| q 1 =s 1 , π ) = 0.63 *...
Combination of:
Initial state, q 1
Policy, π
Transition function, T ()
Produces a probability over histories
Pr T [ h | q 1 , π ]
Note: for any fixed length of history, t :
(i.e., something has to happen...)
h ′ ∈all hist. of len t
′
Problem is that there are a truly vast number of possible history traces
Think about size of complete tree of histories
Don’t want to have to think about history when figuring out what will happen when agent acts now
For many useful systems, all important info can be encoded in the state alone
Definition: An order-k Markov process is a stochastic temporal process in which:
for some finite, bounded k<t
Important special case: k =
First order Markov process -- only need to know current state to make the best possible prediction of next state
Note! We’re not talking RL here -- no actions, no rewards
We’re just talking about random procs. in general
Let’s assume our world is (1st order) Markov
Don’t need to know how Mack got to any specific state in the world
Knowing his current state tells us everything important we need to know about what will happen when he takes a specific action
Now how many params do you need to describe the transition function?
Such a world is called a Markov decision process
To describe all possible transitions under all possible actions, need a set of transition matrices
j i,k
Given a Markov chain (in general, proc), and a start state, can generate a trajectory
Start w/ q 1 =s i , pick next state from
Repeat for t steps
Yields a t-step trajectory,
Any specific trajectory has a fixed probability:
Markov decision process + fixed policy π Markov chain
Markov chain distribution over trajectories
Full definition:
A Markov decision process (MDP), M , is a model of a stochastic, dynamic, controllable, rewarding process given by:
S : State space
A : Action space
T : Transition function
R : Reward function
For most of RL, we’ll assume the agent is living in an MDP