Download Scientific Modeling & Resource Discovery in Workflows: A Comprehensive Overview and more Lab Reports Algorithms and Programming in PDF only on Docsity!
Scientific Modeling and Resource
Discovery in Scientific Workflows
†
Maliha Aziz
Scientific Data management Lab
Computational Biosciences
May 28, 2008
† This work was partially supported by the National Science Foundation17 (grants IIS 0431174, IIS 0551444, and IIS 0612273). Any opinion, finding, and conclusion or recommendation expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Outline
• Terminology
• Introduction
– An Example Scenario in OMICS
– Bioinformatics Resources
– Resource representation
– Implementing and Executing Scientific
Workflows
• Scientific Modeling
• Resource Discovery
Introduction
- (^) Scientific approaches for experimentation
- (^) Hypothesis centric
- (^) Data centric
An Example Scenario in OMICS
Phylogenetic Analysis
- (^) Retrieve DNA sequences belonging to different species.
Align and perform phylogenetic analysis†.
- (^) Some simple questions that arise
- (^) How is the experiment to be conducted?
- (^) Which data sources and tools should I use?
- (^) What would be the input/output formats?
- (^) How do I connect the output of one resource to the input of the
other?
† Taken From: CBS 598-Phylogenetics Author:Dr. Martin F. Wojciechowski, Assistant Professor, School of Life Sciences
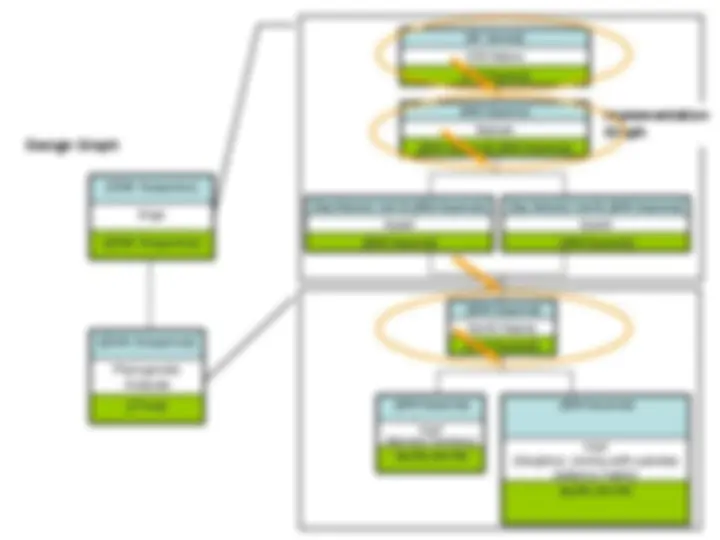
Scientific Modeling Resource Discovery
Resource Composition
{[DNA Sequence]}
Align
{DNA Sequence}
[{Tree}]
Phylogenetic Analysis
{[DNA Sequence]}
{[DNA Sequence]}, {[DNA Sequence]}
Duplicate
{DNA Sequence}
{[DNA Sequence]}
ClustalX
[Gap Extension Cost A], {[DNA Sequence]}
{[DNA Sequence]}
ClustalX
[Gap Extension Cost B], {[DNA Sequence]}
{[DNA Sequence]}
Specify Outgroup
{[DNA Sequence]}
[log file], [tree file]
(Maximum Parsimony)^ PAUP
{[DNA Sequence]}
[log file], [tree file]
PAUP (Neighbor Joining with pairwise distance matrix)
{[DNA Sequence]}
Design Graph
Implementation Graph
{DNA Sequence}
NCBI Retrieve
[{ID, Species}]
Resource Representation
- (^) To be meaningful data/tool need to be annotated.
- (^) Information about data/tool ‘meta data’.
- (^) Data and resources need to be structured.
- (^) Structure provided by XML
- (^) Allows message level interoperability.
- (^) Machine processable language.
- (^) Some Minimum Information (MI) Standards for structuring and
annotating data used in omics†
- (^) CIMR
- (^) MIACA
- (^) MIAME
- (^) MIAME/Env
- (^) MIAME/Nutr
- (^) MIAPE
- (^) MIARE
- (^) MIFlowCyt
- (^) MIGS
- (^) MISFISHIE
- (^) MIAME/Plant
- (^) MIAME/Tox
- (^) MIMPP
- (^) MIMIX
- (^) MIQAS
- MIRIAM
Some Markup languages used in omics
- (^) SBML
- (^) PDBML
- HUP-ML
- (^) AGML
- (^) mzXML
- (^) MAGE-ML
† http://mibbi.sourceforge.net/portal.shtml
Resource Representation
- (^) Simple XML has limitations.
- (^) Need for layer at conceptual level introduction of
various standards.
- (^) Further automation achieved by making tools available
as web services.
- (^) Provides
- (^) Advanced Automation.
- (^) Application Integration.
XML
RDF
OWL, RDFS
OWL-S, WSDL-S, SAWSDL etc.
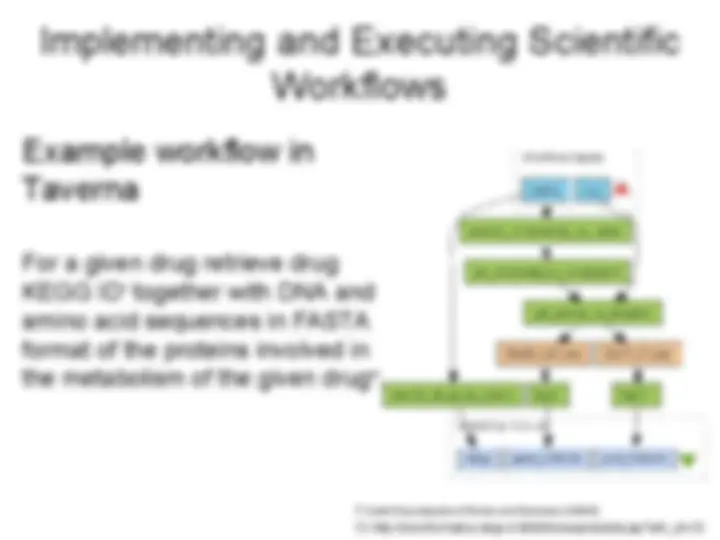
Example workflow in
Taverna
For a given drug retrieve drug
KEGG ID† together with DNA and
amino acid sequences in FASTA
format of the proteins involved in
the metabolism of the given drug††.
Implementing and Executing Scientific
Workflows
†† http://bioinformatics.istge.it:8080/biowep/details.jsp?wfv_id=
† Kyoto Encyclopedia of Genes and Genomes (KEGG)
Scientific Modeling
- (^) A scientific protocol is constructed in two phases†
- (^) design
- (^) implementation
- (^) Aim of the protocol : Superpose proteins structures evaluated at the
residue level, when both sequences and structures have diverged.
- (^) GAPS†† (Gaussian Based Alignment of Protein Structures) algorithm performs the main superposition task.
- (^) Use of ProtocolDB††† workflow model for design and implementation.
- (^) Concepts derived from domain ontology for proteins i.e., Protein Ontology (PO).
† N Kwasnikowska, Y Chen, Z Lacroix: Modeling and storing scientificprotocols. In: OTM Workshops (1). (2006) 730– †† Fabra, Barcelona, Catalonia, Spain Provided by Dr Jordi Mestres - Chemogenomics Laboratory, Research Unit on Biomedical Informatics Institut Municipal d'Investigació Mèdica and Universitat Pompeu ††† M Kinsy, Z Lacroix, C Legendre, P Wlodarczyk, "ProtocolDB: Storing scientific protocols with a domain ontology," in International Workshop on Web Data Integration and Mining in Life; LNCS, 2007, pp. 17-28.
Design Phase
Results
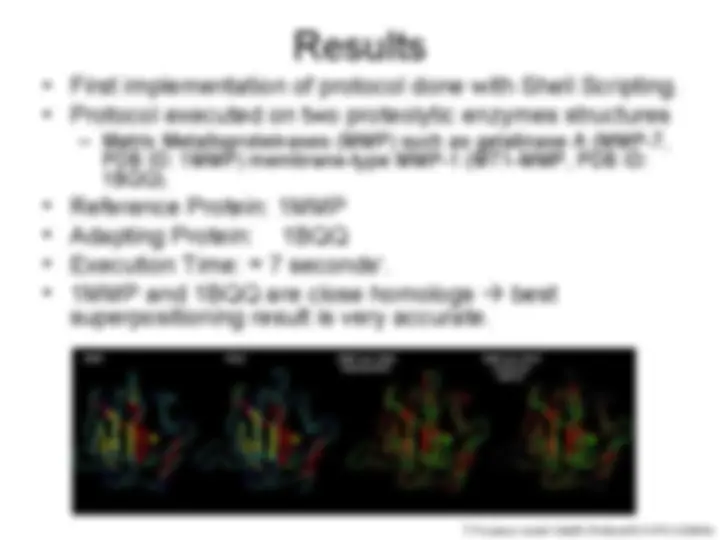
- (^) First implementation of protocol done with Shell Scripting.
- (^) Protocol executed on two proteolytic enzymes structures
- (^) Matrix Metalloproteinases (MMP) such as gelatinase A (MMP-7,
PDB ID: 1MMP) membrane-type MMP-1 (MT1-MMP, PDB ID:
1BQQ).
- (^) Reference Protein: 1MMP
- (^) Adapting Protein: 1BQQ
- (^) Execution Time: ≈ 7 seconds†.
- (^) 1MMP and 1BQQ are close homologs best
superpositioning result is very accurate.
† Processor model: Intel(R) Pentium(R) 4 CPU 3.20GHz
Limitations & Improvements
Performance limitations:
- (^) Manual steps
- (^) retrieval of files from the PDB repository.
- (^) cleaning of files to remove any excess chains of the protein structures.
- (^) A more sophisticated version of the
protocol.
- (^) User provided an interface to view all the
orientations of the adapting protein.
- (^) Availability of a browsing function enables
the scientist to select the best orientations
of the adapting protein based on other
considerations including structural ones.
Resource Discovery
- (^) BioMoby differs from WSDL
- (^) Uses an ontology
- to provide a semantic annotation to the resources.
- to classify resources with respect to a conceptual hierarchy.
get_compounds_ return {[String]} by_pathway
pathway _id
String
Data Type Input Name Operation Name Output Name Data Type
Object namespace=“ KEGG _COMPOUND”
getKeggCompounds compounds OnKegg Pathway
Object pathway namespace=“KEGG _PATHWAY ”
Data Type Input Name Biomoby Service Output Name Data Type
Simple KEGG † Web Service
KEGG Service in BioMoby
In our effort we wish to,
- (^) Perform automatic mapping of resource registries in a domain ontology.
Our focus:
We analyze the
- (^) Semantic layer of BioMoby services.
- (^) Propose algorithm to map BioMoby services to a domain ontology. † Kyoto Encyclopedia of Genes and Genomes (KEGG) : http://www.genome.jp/kegg/soap/doc/keggapi_manual.html
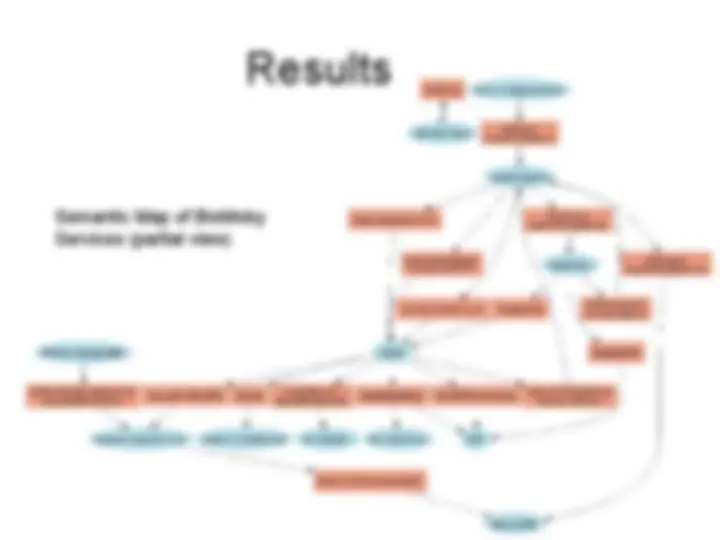
BioMoby Service type Conceptual
Graph
- (^) Tree of root ‘Service’
- (^) Total No. of Nodes: 114
- (^) Depth: 5
- (^) Stored in a SQL relational database the Moby Central
Registry†.
- (^) Access is provided through the Moby Central API††.
Zoom on Analysis in BioMoby Service type conceptual graph
† M. Wilkinson, D. Gessler, A. Farmer, and L. Stein, “The biomoby project explores open-source, simple, extensible protocols for enabling biological database interoperability,” in Proceedings of the Virtual Conference on Genomics and Bioinformatics, 2003, pp. 17–27. [Online]. Available: www.virtualgenomics.org ††http://biomoby.open-bio.org/CVS CONTENT/moby-live/Docs/MOBYSAPI/index API.html
Zoom on VirtualSequence in BioMoby data type ontology
- (^) Tree of root ‘Object’
- (^) Total No. of Nodes:
- (^) 237 registered immediately under Object
- (^) Depth: 8
BioMoby Data type Conceptual
Graph
BioMoby Data type Conceptual
Graph
- (^) The design of the datatype ontology in BioMoby is inspired by the
GO ontology.
- (^) Two types of relationships
- (^) ‘is-a’ depicting subclass.
- (^) ‘has’ or ‘has-a’ for complex data types depicting container ship.
- (^) Problems:
- (^) The same ontology contains concepts and formats.
- (^) All formats must be organized in a tree regardless of their complexity.
- Lacks consistency.
- (^) Graph is format driven.
- (^) The higher nodes should be more conceptual than the leaves but are not.