



More on Indexes
Secondary Indexes
B-Trees
1
Docsity.com




















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of Database System are Secondary Indexes, Security and Integrity, Sequential Files, Serializability, SQL Authorization, The Relational Data Model, Transaction Management. Main points of this lecture are: Secondary Indexes , Candies, Multiple Indexes, Manufacturer, Primary Index, Secondary Index, Facilitates Finding, Secondary Index, Predict, Duplicates
Typology: Slides
1 / 40

This page cannot be seen from the preview
Don't miss anything!
4
Sequence field
50
30
70
20
40
80
10
100
60
90
30 20 80 100
90 ...
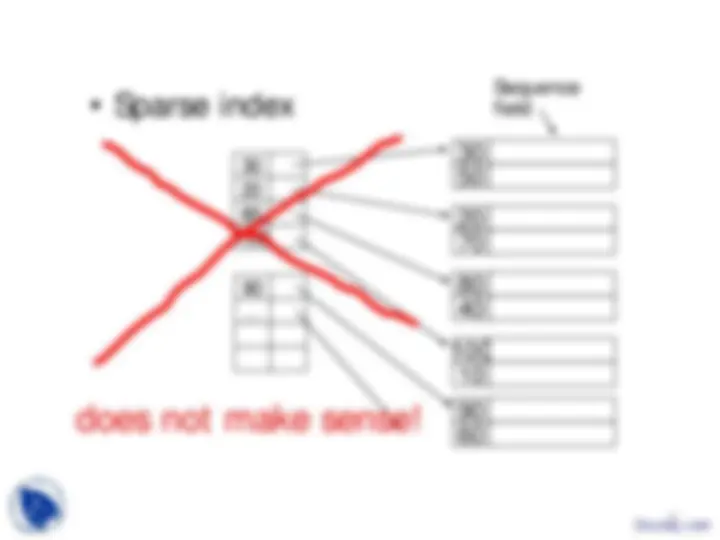
does not make sense!
Secondary Index and Duplicate Keys
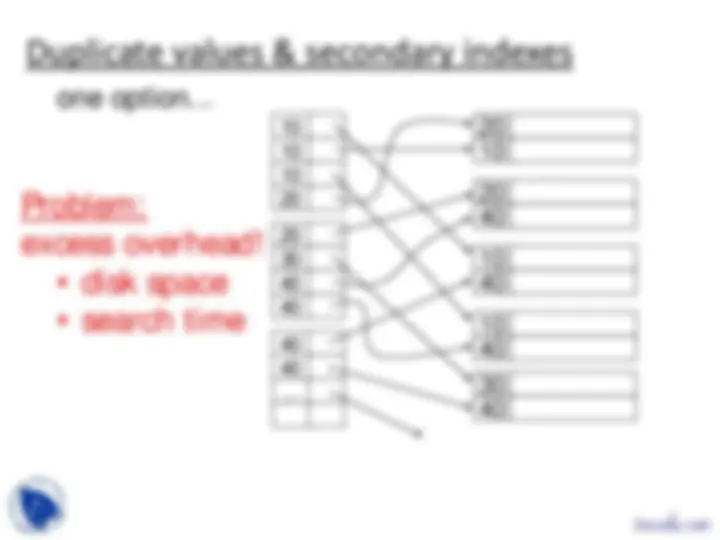
Duplicate values & secondary indexes
8
10
20
40
20
40
10
40
10
40
30
10 10 10 20 20 30 40 40 40 40 ...
one option...
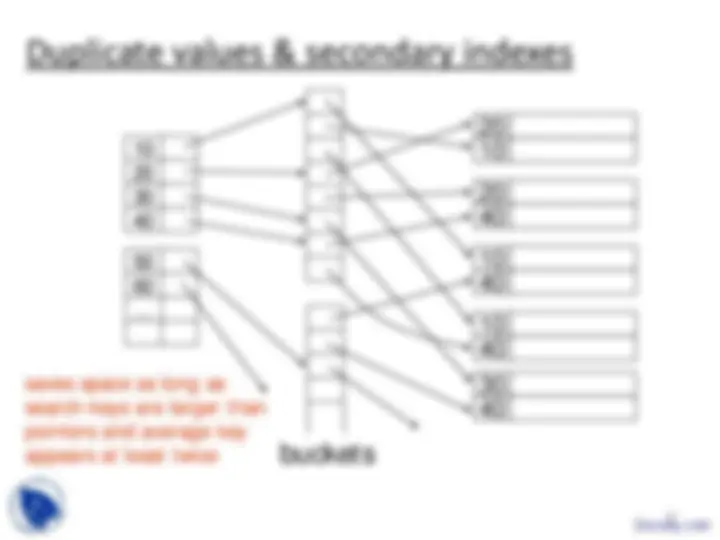
Duplicate values & secondary indexes
10
10
20
40
20
40
10
40
10
40
30
10 20 30 40
50 60 ...
buckets
saves space as long as search-keys are larger than pointers and average key appears at least twice
Why “bucket” idea is useful
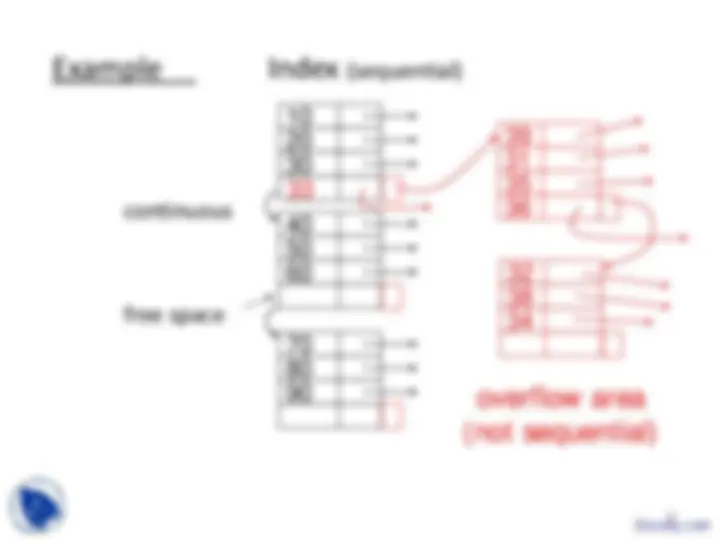
continuous
free space
14
10 20 30
40 50 60
70 80 90
39 31 35 36
32 38 34
33
overflow area (not sequential)
leaf path has same length
contains search keys and pointers
pointers and n keys fit in one block
sorted order
pointers
( n +1)/2 and n +1 index node pointers
ptr 1 ,key 1 ,ptr 2 ,key 2 ,…,keym-1 ,ptr (^) m where ptri points to index node with keys between keyi-1 and keyi
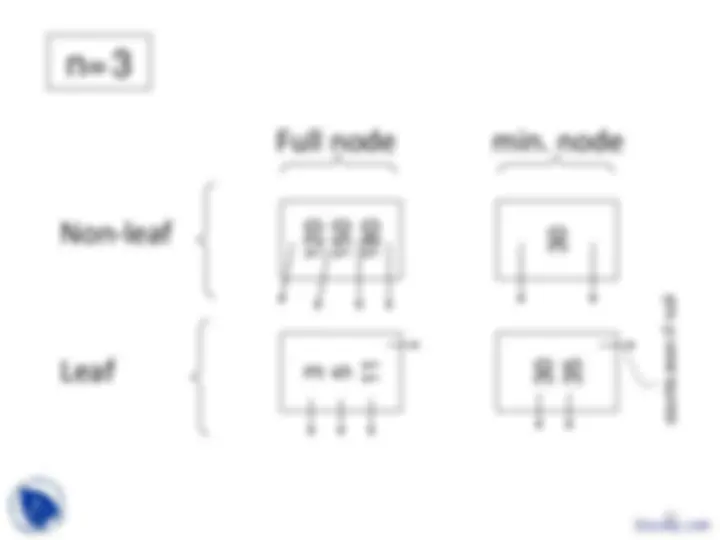
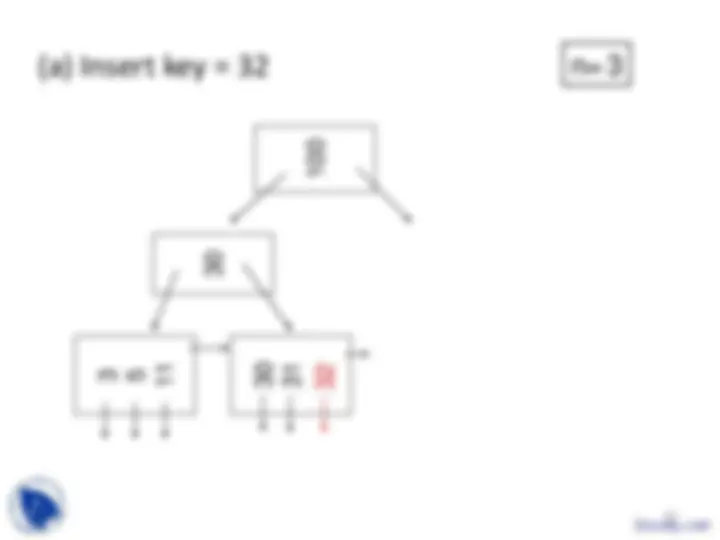
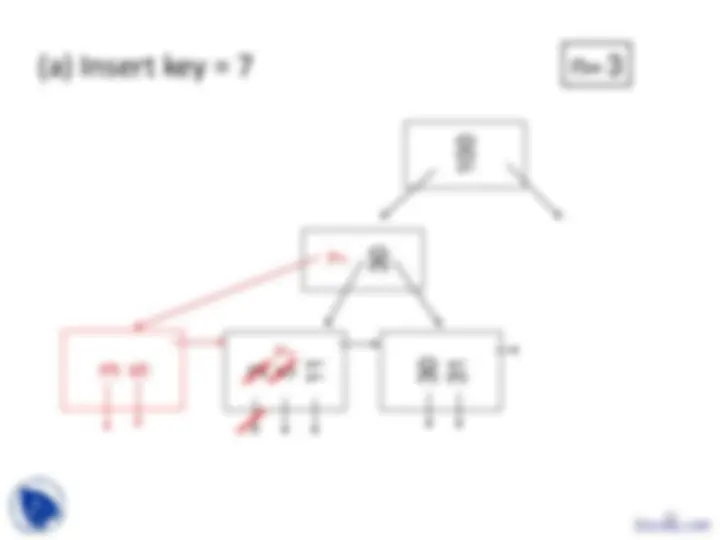
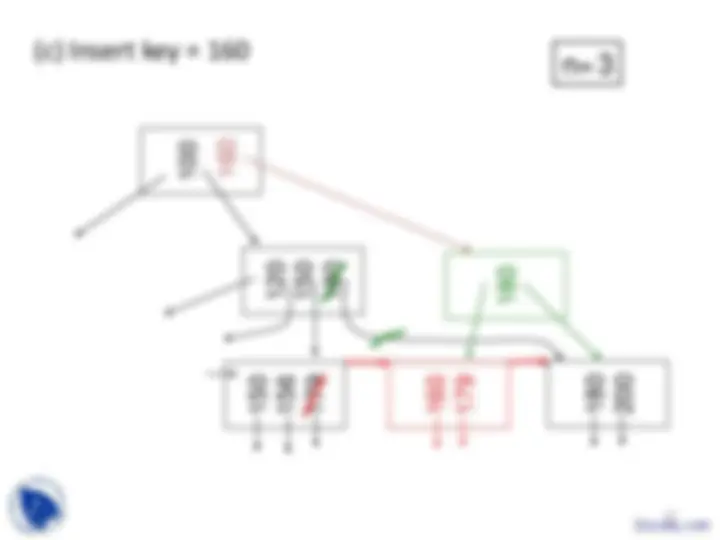
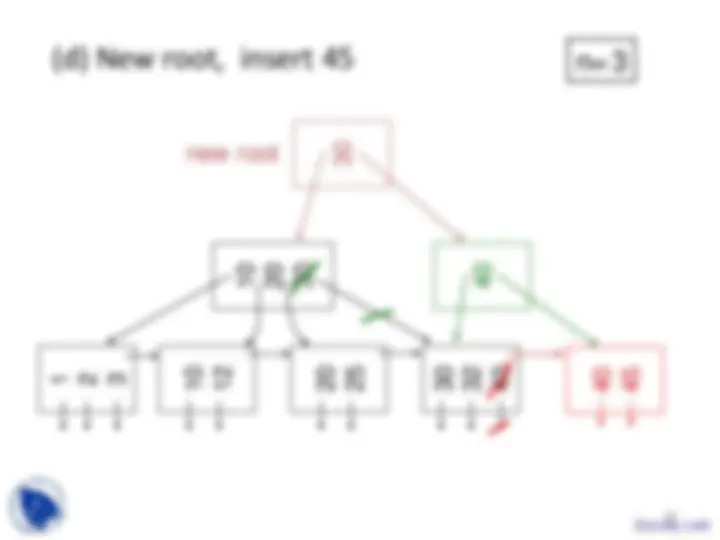
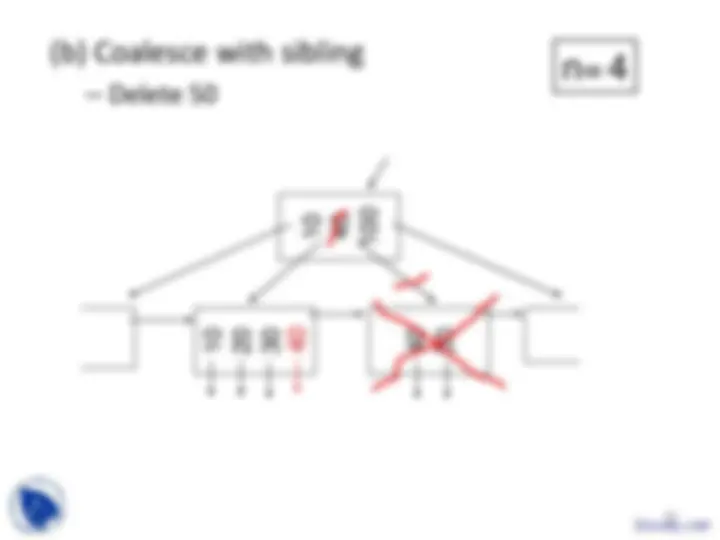
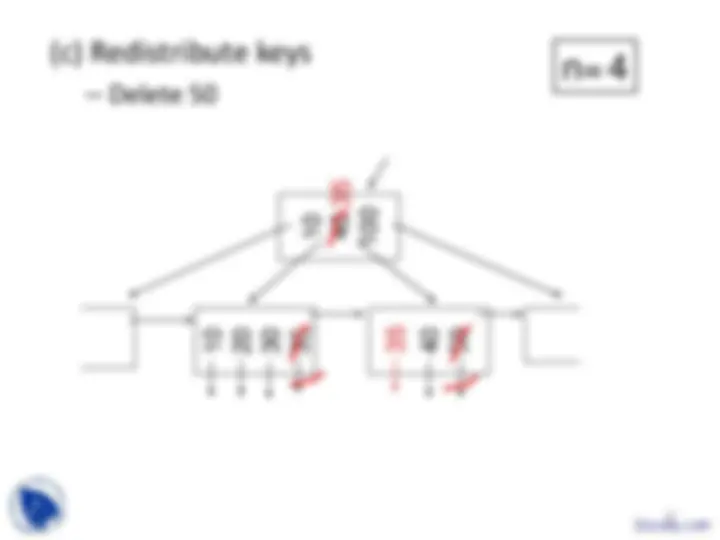
Example B-tree nodes with n = 3
19
3035
30
(^30 )
30
more concise notation textbook notation
Leaf:
Non-leaf:
to record with key 30
to record with key 35
to part of tree with keys < 30
to part of tree with keys ≥ 30
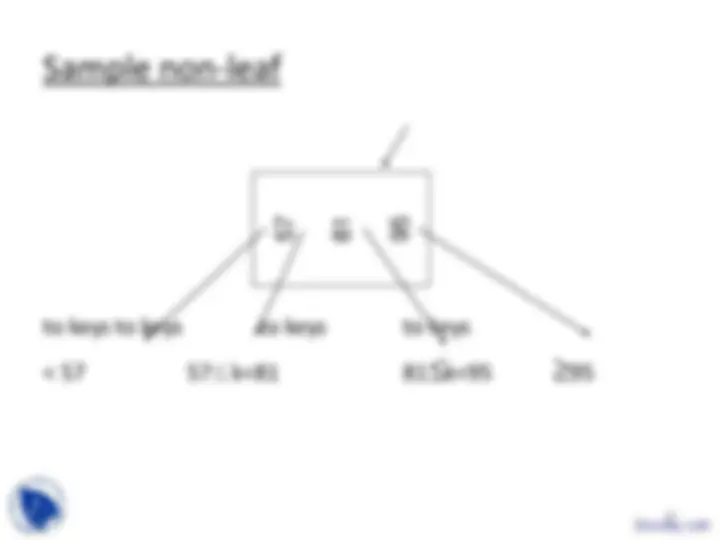
Sample non-leaf
to keys to keys to keys to keys
20
57 81 95