Download Semaphore - High Performance Computing - Lecture Slides and more Slides Computer Science in PDF only on Docsity!
High Performance Computing
Lecture 21
2
Semaphore Examples
Semaphores can do more than mutex locks
Example: Consider our concurrent program
where process P1 reads 2 matrices; process
P2 multiplies them & process P3 outputs the
product
Semaphores
Process P1 Process P2 Process P
Read A[ ], B[ ] C[ ] = A[ ] * B[ ] Write C[ ]
S
1 P(S 1
V(S
1
S
2
P(S
2
V(S
2
4
Classical Problems
Producers-Consumers Problem
Bounded buffer problem
Producer process makes things and puts them
into a fixed size shared buffer
Consumer process takes things out of shared
buffer and uses them
Must ensure that producer doesn’t put into full
buffer or consumer take out of empty buffer
While treating buffer accesses as critical section
5
Producers-Consumers Problem
shared Buffer[0 .. N-1]
Producer: repeatedly
Produce x
Buffer[i++] = x
Consumer: repeatedly
y = Buffer[- - i]
Consume y
; if (buffer is full) wait for consumption
; signal consumer
If (buffer is empty) wait for production
; signal producer
7
THREADS
Thread
Thread of control in a process
`Light weight process’
Weight related to
Time for creation
Time for context switch
Size of context
Recall: Process as a Data Structure
8
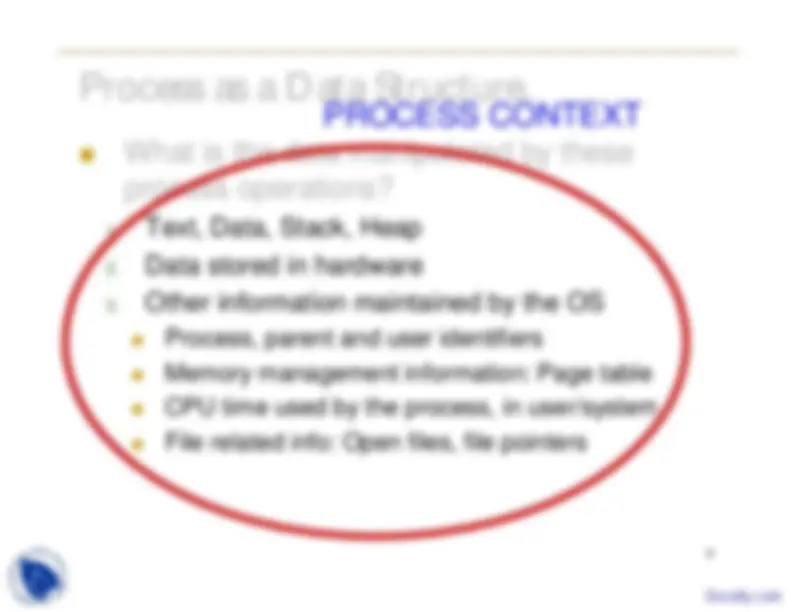
Process as a Data Structure.
What is the data manipulated by these
process operations?
1. Text, Data, Stack, Heap
2. Data stored in hardware
3. Other information maintained by the OS
Process, parent and user identifiers Memory management information: Page table CPU time used by the process, in user/system File related info: Open files, file pointers
PROCESS CONTEXT
10
Thread Implementation
Could either be supported in the operating
system or by a library
Pthreads: POSIX thread library
int pthread_create
pthread_t *thread, const pthread_attr_t *attr, void (start_routine), void *arg
pthread_attr
pthread_join
pthread_exit
pthread_detach
11
Synchronization Primitives
Mutex locks
int pthread_mutex_lock(pthread_mutex_t *mutex)
If the mutex is already locked, the calling thread blocks until the mutex becomes available. Returns with the mutex object referenced by mutex in the locked state with the calling thread as its owner.
pthread_mutex_unlock
Semaphores
sem_init
sem_wait
sem_post
13
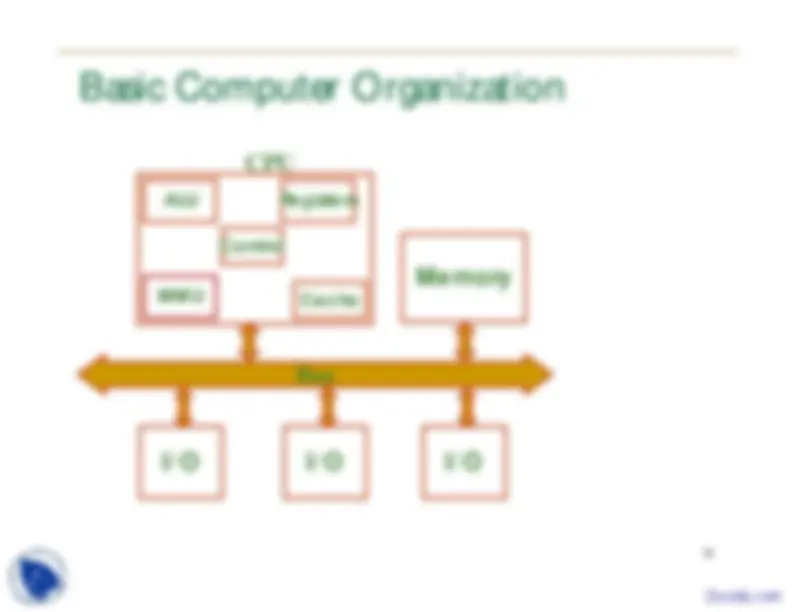
Basic Computer Organization
Cache Memory I/O Bus I/O I/O MMU ALU Registers
CPU
Control
14
Performance of Processor
Which is more important?
execution time of a single instruction
throughput of instruction execution
i.e., number of instructions executed per unit time
Cycles Per Instruction (CPI)
Current ideas: CPI between 3 and 5
Pipelining
Why keep Fetch hardware idle while instruction is
being decoded
Inspired by petroleum pipelines?
16
Inside the Processor
Mem IR
PC NPC Reg File sign extend A Imm B Inst Fetch IF Inst Decode ID 4 ALU ALU out Zero? Mem LMD Execution EX Memory MEM Cond WB IF ID EX MEM WB
17
Processor Pipelining
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
- Execution time of each instruction is still 5 cycles, but the throughput is now 1 instruction per cycle
- Initial pipeline fill time (4 cycles), after which 1 instruction completes every cycle time i i i i
clock cycles