Download Setting up your environment and more Study Guides, Projects, Research Linux skills in PDF only on Docsity!
FIT5202 - Data processing for big
data
Activity: Setting up your development environment
In this activity, we will learn how to set up the system and make it ready for processing big data. We will use Ubuntu 18.04.02 LTS (Bionic Beaver) as the operating system and install the following tools and technologies to learn data processing for big data.
- Python as a programming language
- Jupyter Notebook as an IDE for python development
- Apache Spark as a big data processing and analysis tool
- MongoDB as a NoSQL data store, and
We will be using MoVE(Monash Virtual Environment) for running the Virtual Machine where you will be accessing a hosted instance of Ubuntu. You can also install the Ubuntu Image in your own machine using Virtualbox.
Let's get started with the setup.
Using MoVE 2
Using Virtualbox (In personal computer) 5
Installing the required software 6
Step 1. Install JAVA 6 Step 2: Set Up Python 6 Step 3: Create a Virtual Environment for Jupyter 7 Step 4: Install Jyputer 8 Step 5: Run Jupyter Notebook 8 Step 6: Using Jupyter Notebook 9 Step 7: Install pyspark 10 Step 8: Test Spark Installation 11 Step 9: Install MongoDB 11 How to run Jupyter Notebook? 13
Using MoVE
The Virtual Machine(VM) is hosted in MOVE (Monash Virtual Environment). To access it you will be using your Monash Authgate credentials.
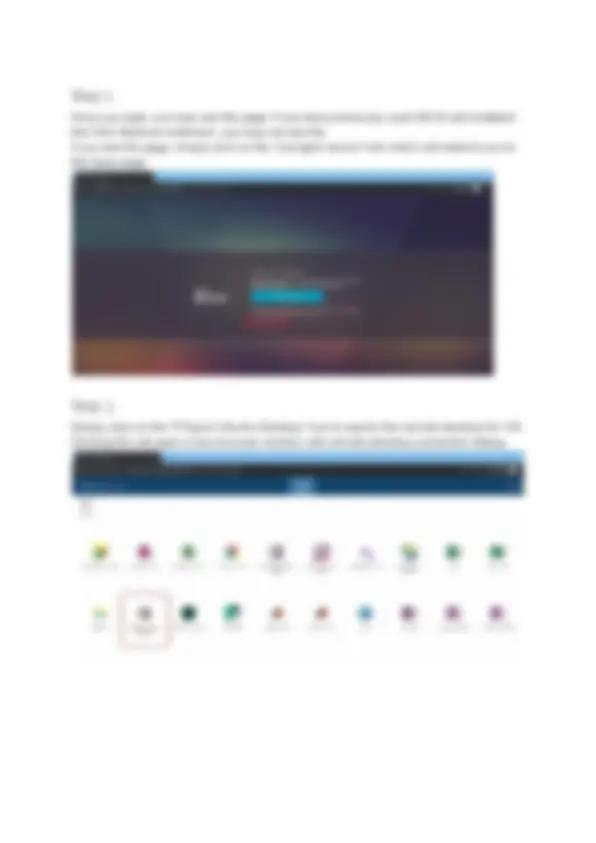
Step 1
Go to https://move.monash.edu If you are not logged in already with your monash account, it will redirect you to this page for Okta Verification. Enter your monash email address and password and login.
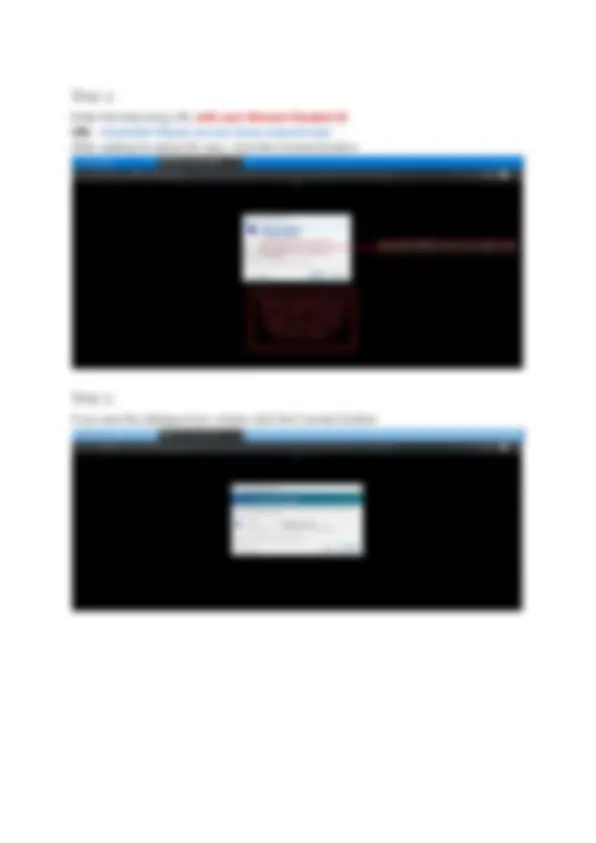
Step 4
Enter the following URL with your Monash Student ID. URL : studentid-fit5202.access.move.monash.edu After waiting for about 60 secs, click the Connect button.
Step 5
If you see this dialogue box, simply click the Connect button.
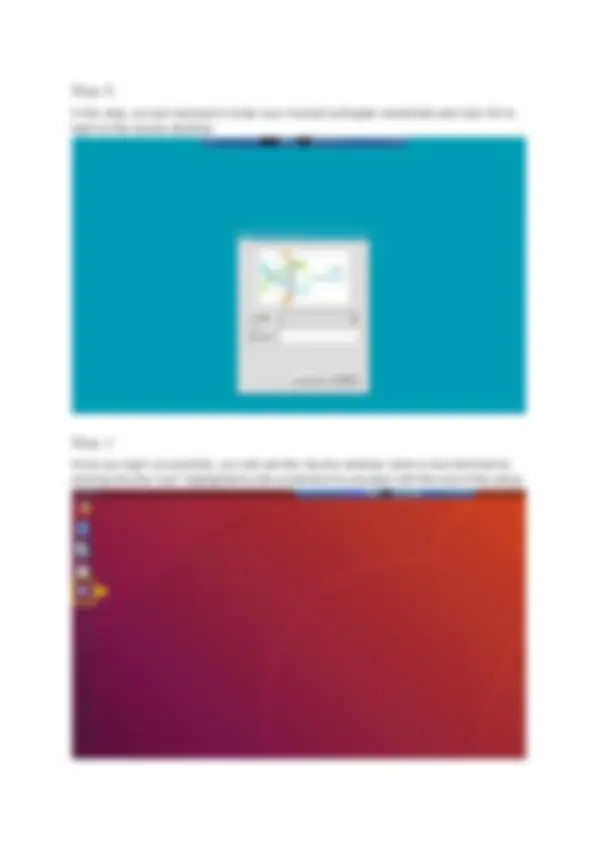
Step 6
In this step, you are required to enter your monash authgate credentials and click OK to login to the ubuntu desktop.
Step 7
Once you login successfully, you will see the Ubuntu desktop. Open a new terminal by clicking into the “icon” highlighted in the screenshot to proceed with the rest of the setup.
Installing the required software
We will go through one by one the installation of required software for FIT5202.
Step 1. Install JAVA
We first need to update the local apt package index and then download and install the packages:
$ sudo apt update
Apache Spark needs JAVA to run. We can install JAVA by typing:
$ sudo apt install openjdk-8-jdk
Test your JAVA installation by typing:
$ java -version
You should see the following output:
OpenJDK version "1.8.0_191" OpenJDK Runtime Environment (build 1.8.0_191-8u191-b12-2ubuntu0.18.04.1-b12) OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
Step 2: Set Up Python
To begin the process, we’ll install the dependencies we need for our Python programming environment from the Ubuntu repositories. Ubuntu 18.04 comes preinstalled with Python 3.6. We will use the Python package manager pip to install additional components a bit later.
Now, install pip and the Python header files, which are used by some of Jupyter’s dependencies by typing:
$ sudo apt install python3-pip python3-dev
We can now move on to set up a Python virtual environment into which we’ll install Jupyter.
Step 3: Create a Virtual Environment for Jupyter
Now that we have Python 3, its header files, and pip ready to go, we can create a Python virtual environment to manage our projects. We will install Jupyter into this virtual environment. To do this, we first need access to the virtualenv command which we can install with pip. Install the package by typing:
$ sudo -H pip3 install virtualenv
The -H flag ensures that the security policy sets the home environment variable to the home directory of the target user.
With virtualenv installed, we can start forming our environment. Create and move into a directory where we can keep our project files. You can call this FIT5202.
$ mkdir ~/FIT $ cd ~/FIT
Within the project directory, we’ll create a Python virtual environment. For the purpose of this tutorial, we’ll call it jupyter.
$ virtualenv jupyter
This will create a directory called jupyter within your jupyter directory. Inside, it will install a local version of Python and a local version of pip. We can use this to install and configure an isolated Python environment for Jupyter.
Before we install Jupyter, we need to activate the virtual environment. You can do that by typing:
$ source jupyter/bin/activate
Your prompt should change to indicate that you are now operating within a Python virtual environment. It will look something like this:
(jupyter) student@student-VM:~/FIT5202$
You’re now ready to install Jupyter into this virtual environment.
http://localhost: 8888 /?token=1fefa6ab49a498a3f37c959404f7baf16b9a2eda3eaa6d 2
Step 6: Using Jupyter Notebook
You should now be connected to the jupyter notebook using a web browser. Jupyter Notebook is a very powerful tool with many features. This section will outline a few of the basic features to get you started using the Notebook. Jupyter Notebook will show all of the files and folders in the directory it is run from, so when you’re working on a project make sure to start it from the project directory.
To create a new Notebook file, select New > Python 3 from the top right pull-down menu:
This will open a Notebook. We can now run the Python code in the cell or change the cell to markdown. For example, change the first cell to accept Markdown by clicking Cell > Cell Type > Markdown from the top navigation bar. We can now write notes using Markdown and even include equations written in LaTeX by putting them between the $$ symbols. For example, type the following into the cell after changing it to markdown:
First Equation
Let us now implement the following equation: $$ y = x^2$$
where $x = 2$
To turn the markdown into rich text, press CTRL+ENTER, and the following should be the results:
You can use the markdown cells to make notes and document your code. Let's implement that equation and print the result. Click on the top cell, then press ALT+ENTER to add a cell below it. Enter the following code in the new cell.
x = 2 y = x** 2 print(y)
To run the code, press CTRL+ENTER. You’ll receive the following results:
You now have the ability to import modules and use the Notebook as you would with any other Python development environment!
Step 7: Install pyspark
Enter the following installation command in the new cell.
!pip install pyspark
To run the code, press CTRL+ENTER. You’ll receive the following results:
This command installs several packages containing the latest stable version of MongoDB, along with helpful management tools for the MongoDB server. The database server is automatically started after installation. You can verify it by running the command as below.
$ mongo
You should receive the following output:
MongoDB shell version v3.6. connecting to: mongodb://127.0.0.1: MongoDB server version: 3.6. Welcome to the MongoDB shell. For interactive help, type "help". For more comprehensive documentation, see http://docs.mongodb.org/ Questions? Try the support group http://groups.google.com/group/mongodb-user Server has startup warnings: 2019-03-11T16:09:08.520+1100 I STORAGE [initandlisten] 2019-03-11T16:09:08.520+1100 I STORAGE [initandlisten] ** WARNING: Using the XFS filesystem is strongly recommended with the WiredTiger storage engine 2019-03-11T16:09:08.520+1100 I STORAGE [initandlisten] ** See http://dochub.mongodb.org/core/prodnotes-filesystem 2019-03-11T16:09:09.984+1100 I CONTROL [initandlisten] 2019-03-11T16:09:09.984+1100 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database. 2019-03-11T16:09:09.984+1100 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted. 2019-03-11T16:09:09.984+1100 I CONTROL [initandlisten] >
Now you are inside Mongo Shell which verifies that the MongoDB server is running. Type ‘exit’ to get out of the Mongo Shell.
Additional Information:
MongoDB installs as a systemd service, which means that you can manage it using standard systemd commands alongside all other system services in Ubuntu.
To verify the status of the service, type: $ sudo systemctl status mongodb
You can stop the server anytime by typing:
$ sudo systemctl stop mongodb
To start the server when it is stopped, type: $ sudo systemctl start mongodb
You can also restart the server with a single command. $ sudo systemctl restart mongodb
By default, MongoDB is configured to start automatically with the server. If you wish to disable the automatic startup, type: $ sudo systemctl disable mongodb
It's just as easy to enable it again. To do this, use: $sudo systemctl enable mongodb
How to run Jupyter Notebook?
You can start Jupyter Notebook by typing:
$ cd ~/FIT FIT5202$ source jupyter/bin/activate (jupyter) student@student-VM:~/FIT5202$ (jupyter) student@student-VM:~/FIT5202$ jupyter notebook
A log of the activities of the Jupyter Notebook will be printed to the terminal. When you run Jupyter Notebook, it runs on a specific port number. The first Notebook you run will usually use port 8888. To check the specific port number Jupyter Notebook is running on, refer to the output of the command used to start it:
Output: [I 21:23:21.198 NotebookApp] Writing notebook server cookie secret to /run/user/1001/jupyter/notebook_cookie_secret [I 21:23:21.361 NotebookApp] Serving notebooks from local directory: /home/student/FIT [I 21:23:21.361 NotebookApp] The Jupyter Notebook is running at: [I 21:23:21.361 NotebookApp] http://localhost: 8888 /?token=1fefa6ab49a498a3f37c959404f7baf16b9a2eda3eaa6d 2 [I 21:23:21.361 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [W 21:23:21.361 NotebookApp] No web browser found: could not locate runnable browser. [C 21:23:21.361 NotebookApp]