Download Simple Parity Check Code - Information Theory - Lecture Slides and more Slides Information Technology in PDF only on Docsity!
EE514a – Information Theory I
Fall Quarter 2013
Prof. Jeff Bilmes
University of Washington, Seattle Department of Electrical Engineering Fall Quarter, 2013 http://j.ee.washington.edu/~bilmes/classes/ee514a_fall_2013/
Lecture 17 - Nov 26th, 2013
Class Road Map - IT-I
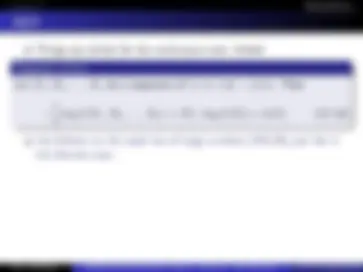
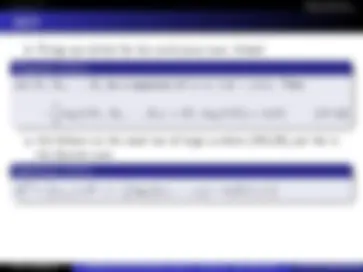
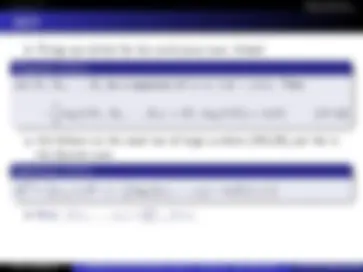
L1 (9/26): Overview, Communications, Information, Entropy L2 (10/1): Props. Entropy, Mutual Information, L3 (10/3): KL-Divergence, Convex, Jensen, and properties. L4 (10/8): Data Proc. Ineq., thermodynamics, Stats, Fano, M. of Conv L5 (10/10): AEP, Compression L6 (10/15): Compression, Method of Types, L7 (10/17): Types, U. Coding., Stoc. Processes, Entropy rates, L8 (10/22): Entropy rates, HMMs, Coding, Kraft, L9 (10/24): Kraft, Shannon Codes,Huffman, Shannon/Fano/Elias
L10 (10/28): Huffman, Shannon/Fano/Elias L11 (10/29): Shannon Games, LXX (10/31): Midterm, in class. L12 (11/7): Arith. Coding, Channel Capacity L13 (11/12): Channel Capacity L14 (11/14): Channel Capacity, Shannon’s 2nd thm L15 (11/19): Shannon’s 2nd thm, zero error codes, feedback L16 (11/21): Joint thm, coding, hamming, L17 (11/26): hamming, diff. entropy L
Finals Week: December 12th–16th.
Homework
Homework 7 on our web page (http://j.ee.washington.edu/ ~bilmes/classes/ee514a_fall_2013/), due Sunday night, at 11:45pm.
Announcements
Office hours, every week, now Thursdays 4:30-5:30pm. Can also reach me at that time via a canvas conference. Email me if you want to skype/google hangout over the break and we can arrange a time. Final assignment now online, need to upload pdf scan we send you by Tuesday Dec 11th, at 4:00pm.
Repetition Repetition Repetition Code Code Code
Rather than send message x 1 x 2... xk we repeat each symbol K times redundantly. Recall our example of repeating each word in a noisy analog radio connection. Message becomes x ︸ 1 x (^1) ︷︷... x 1 ︸ k×
x ︸ 2 x (^2) ︷︷... x 2 ︸ k×
For many channels (e.g., BSC(p < 1 /2)), error goes to zero as k → ∞. Easy decoding: when k is odd, take a majority vote (which is optimal for a BSC) On the other hand, R ∝ 1 /k → 0 as k → ∞ This is really a pre-1948 way of thinking code. Thus, this is not a good code.
Simple Parity Check Code
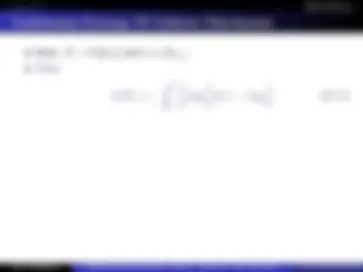
Binary input/output alphabets X = Y = { 0 , 1 }. Block sizes of n − 1 bits: x1:n− 1. nth^ bit is an indicator of an odd number of 1 bits in x1:n− 1. I.e., xn ← mod
n− 1 i=1 xi,^2
Thus a necessary condition for valid code word is: mod
n i=1 xi,^2
Any instance of an odd number of errors (bit swaps) won’t pass this condition, and such an error is hence detected. although an even number of errors will pass the condition (error goes undetected). can not correct all errors, and moreover only detects some of the kinds of errors (odd number of swaps). On the other hand, parity checks form the basis for many sophisticated coding schemes (e.g., low-density parity check (LDPC) codes, Hamming codes etc.). We study Hamming codes next.
(7, 4 , 3) Hamming Codes
Parity bits determined by the following equations:
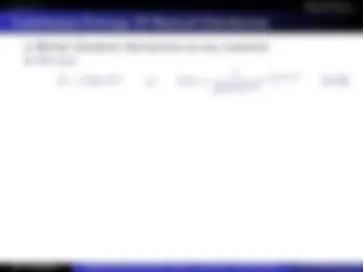
x 4 ≡ x 1 + x 2 + x 3 mod 2 (17.14) x 5 ≡ x 0 + x 2 + x 3 mod 2 (17.15) x 6 ≡ x 0 + x 1 + x 3 mod 2 (17.16)
I.e., if (x 0 , x 1 , x 2 , x 3 ) = (0110) then (x 4 , x 5 , x 6 ) = (011) and complete 7-bit codeword sent over channel would be (0110011). We can also describe this using linear equalities as follows (all mod 2).
x 1 + x 2 + x 3 + x 4 = 0 x 0 + x 2 + x 3 +x 5 = 0 x 0 + x 1 + x 3 + x 6 = 0 (17.17)
Hamming Codes
Or alternatively, as Hx = 0 where xᵀ^ = (x 1 , x 2 ,... , x 7 ) and
H =
Codewords lie in null-space of H Notice that H is a column permutation of all seven non-zero length-3 column vectors. Thus the code words are defined by the null-space of H. I.e., {x : Hx = 0}. Since the rank of H is 3, the null-space is 4, and we expect there to be 16 = 2^4 binary vectors in this null space.
Hamming Codes : weight
Thus, any valid codeword is in C = {x : Hx = 0}. Thus, if v 1 , v 2 ∈ C then H(v 1 + v 2 ) = Hv 1 + Hv 2 = 0 and thus v 1 + v 2 ∈ C. Also, v 1 − v 2 ∈ C due to linearity (codewords closed under addition and subtraction). Minimum number of ones in any non-zero codeword is 3. This is called the weight of a code. Why weight 3? Suppose there was a weight-two code word with non-zeros at position i and j. Thus, sum of columns i and j would be zero. But since columns of H are all different, sum of any two columns is non-zero. Hence, can’t have any weight-2 codeword. Q: why can’t we have a weight 1 code word? Can have weight 3 codeword, since sum of two columns will equal another column, and sum of two equal binary vectors is zero (mod 2).
Hamming Codes : Distance
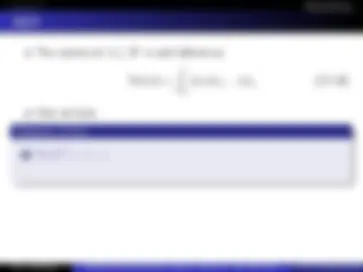
Thus, any codeword is in C = {x : Hx = 0}. minimum distance of a code is also 3, which is minimum number of differences between any two codewords. Another way of saying this: if v 1 , v 2 ∈ C then dH (v 1 , v 2 ) ≥ 3 where dH (x, y) =
i 1 {x(i)^6 =y(i)}^ is the Hamming distance. Why? Suppose v 1 , v 2 ∈ C differ in only two places. Then H(v 1 − v 2 ) will be a difference or sum of two columns of H (mod 2). But given v 1 , v 2 ∈ C ⇒ (v 1 − v 2 ) ∈ C. Can’t have difference or sum, (1+1 = 1-1 mod 2) of any two columns equaling zero H(v 1 − v 2 ) 6 = 0, contradiction. Hence, v 1 − v 2 can’t differ in only two places. In general, codes with large minimum distance is good because then it is possible to correct errors. I.e., if ˆv is received codeword, then we can find i ∈ argmini dH (ˆv, vi) as the decoding procedure.
Hamming Codes Differential Entropy
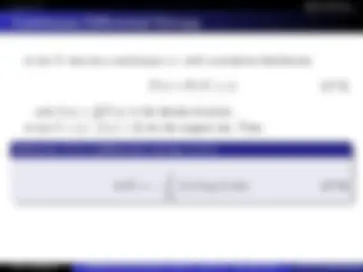
Hamming Codes : BSC
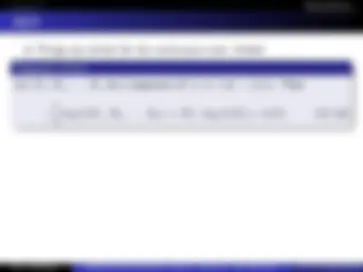
Moreover, we see that s is a linear combination of columns of H
s = z 0
(^) + z 1
(^) + z 2
(^) + · · · + z 6
Hamming Codes Differential Entropy
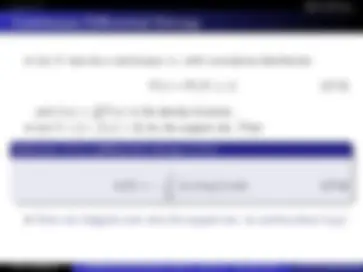
Hamming Codes : BSC
Moreover, we see that s is a linear combination of columns of H
s = z 0
(^) + z 1
(^) + z 2
(^) + · · · + z 6
Since y = x + z, we know y, so if we know z we know x.
Hamming Codes Differential Entropy
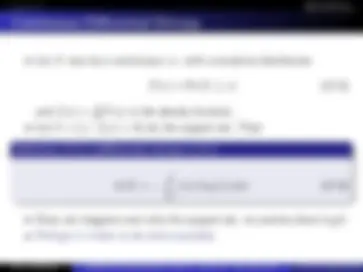
Hamming Codes : BSC
Moreover, we see that s is a linear combination of columns of H
s = z 0
(^) + z 1
(^) + z 2
(^) + · · · + z 6
Since y = x + z, we know y, so if we know z we know x. We only need to solve for z in s = Hz, 16 possible solutions. Ex: Suppose that yᵀ^ = 0111001 is received (which is not a codeword), then s = Hy = (101)ᵀ^ and the 16 solutions for z are:
0100000 0010011 0101111 1001001 1100011 0001010 1000110 1111010 0000101 0111001 1110101 0011100 0110110 1010000 1101100 1011111
Hamming Codes Differential Entropy
Hamming Codes : BSC
16 is better than 128 (possible z vectors) but still many.