Download Spatial Autocorrelation - GIS and Mapping - Lecture Notes and more Study notes Geology in PDF only on Docsity!
Fig. 1.8 An area (red line) and its approximation by a polygon (blue line).
To capture an area object in vector form, only the locations of the points that form the vertices of a polygon must be captured. This seems simple and also much more efficient than a raster representation, which would require us to list all the cells that form the area. To create a precise approximation to an area in raster, it would be necessary to resort to using very small cells and the number of cells would rise proportionately. But things are not quite as simple as they seem. The apparent precision of vector is often unreasonable, because many geographic phenomena simply cannot be located with high accuracy.
So, although raster data may look less attractive, they may be more honest to the inherent quality of the data. Also, various methods exist for compressing raster data that can greatly reduce the capacity needed to store a given data set. The choice between raster and vector is often complex, as shown in the table below.
Fig. 1.9 - Relative advantages of raster and vector
The nature of geographic data
5.2 Spatial Autocorrelation
The First Law of Geography, formulated by Waldo Tobler, states that everything is related to everything else, but near things are more related than distant things. Spatial autocorrelation is the formal property that measures the degree to which near and distant things are related.
Positive spatial autocorrelation occurs when features that are similar in location are also similar in attributes. Negative spatial autocorrelation occurs when features that are close together in space are dissimilar in attributes. Zero autocorrelation occurs when attributes are independent of location.
Fig. 1.11 Arrangements of dark and light colored cells exhibiting negative, zero, and positive spatial autocorrelation.
5.4 Spatial Sampling
Fig. 1.13 - a spatially systematic (stratified) sample
Spatially systematic sampling also has weaknesses. Imagine that the grid pattern above were to coincide with the grid plan of a city. In a survey of urban land use, it is extremely unlikely that the attributes of street intersections would be representative of land uses elsewhere in the block structure. A number of hybrid sample designs have been devised to get around the vulnerability of spatially systematic and random sampling. These include stratified random sampling to ensure evenness of coverage and periodic random changes in the grid width of a spatially systematic sample, perhaps subject to minimum spacing intervals.
Fig. 1.14 - a stratified random sample
Fig. 1.15 - a sampling scheme with periodic random changes in the grid width of a spatially systematic sample
Simple random or spatially systematic sampling presumes that each observation is of equal importance in building a representation. Many times this is not the case, and it may be more efficient and necessary to devise application-specific sample designs to improve quality of representation, while minimizing resource costs of collecting data.
5.5 Spatial Interpolation Spatial interpolation is the process of filling in the gaps between sample observations. It requires an understanding of the attenuating effect of distance between sample observations and selection of an appropriate interpolation function. This concept focuses on principles that are used to describe effects over distance. For an introduction to some of the mathematical functions used to describe these effects, refer to Section 5.5 in the Longley et al. text.
A literal interpretation of Tobler's Law implies a continuous, smooth, attenuating effect of distance upon the attribute values of adjacent or contiguous spatial objects, or incremental variation in attribute values as we traverse a field. For example, the polluting effect of a chemical or oil spill decreases in a predictable (and in still waters, uniform) fashion with distance from the source of the spill, aircraft noise pollution decreases with distance from the flight path, and the number of visits to a national park might decrease at a regular rate with distance from the park.
The literal interpretation of Tobler's Law may be appropriate for many applications. The notion of smooth and continuous variation underpins many of the representational traditions in cartography, such as the creation of maps showing contour lines. Contour lines connect points with equal elevation above sea level.
examine the attributes for the sample points.
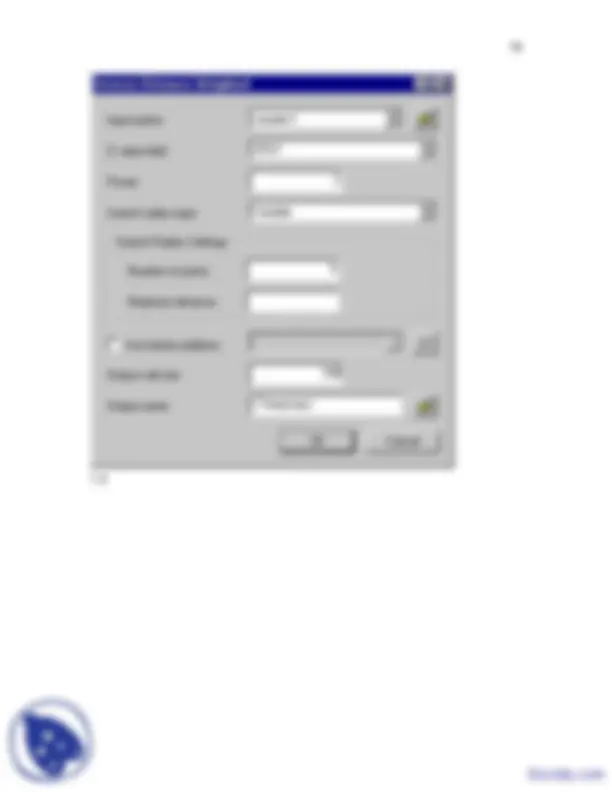
use the sample points to interpolate an elevation surface. You'll use the Inverse Distance Weighted (IDW) interpolation method. This method is a common method and follows Tobler's Law by interpolating values as weighted averages over the known measurements at nearby points, giving the greatest weight to the nearest points. Use Number of Points = 5, Output cell size = 100
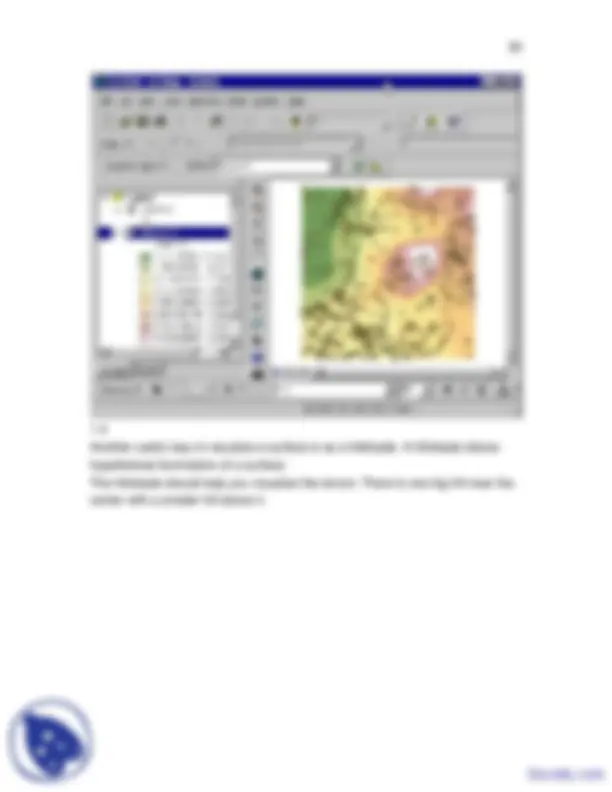
Another useful way to visualize a surface is as a hillshade. A hillshade shows hypothetical illumination of a surface. The hillshade should help you visualize the terrain. There is one big hill near the center with a smaller hill above it.