Download Distributed Query Processing: Client-Server Architectures and Query Optimization and more Slides Database Management Systems (DBMS) in PDF only on Docsity!
The State of the Art in
Distributed Query Processing
Introduction
- Distributed database technology is becoming
an increasingly attractive enhancement to
many database systems
- Cost and scalability
- Software integration
- New applications
- Market forces
Client-Server Database Systems
- Relationships between distributed nodes take
a client-server form
- Client: makes requests of the servers, usually
the source of queries
- Server: responds to client requests, usually
the source of data
- System architectures: peer-to-peer, strict
client-server, middleware/multitier
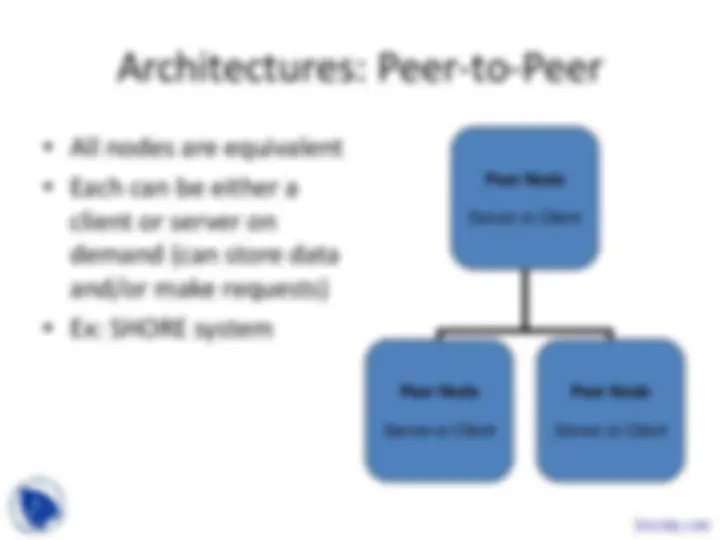
Architectures: Peer-to-Peer
- All nodes are equivalent
- Each can be either a client or server on demand (can store data and/or make requests)
- Ex: SHORE system
Peer Node Server or Client
Peer Node Server or Client
Peer Node Server or Client
Architectures: Middleware/Multitier
- Multiple levels of client- server interaction
- Nodes act as clients to those below them and servers to those above
- SAP R/3, web servers with DB backends
Node 1 Client to Node 2
Node 2 Server to Node 1, Client to Node 3
Node 3 Server to Node 2
Architectures: Evaluation
- Peer-to-Peer
- Simplest setup
- Equal load sharing
- Strict Client-Server
- Specialization
- Administration for servers only
- Middleware/Multitier
- Functionality integration
- Scalability
Query Shipping
- SQL query code is sent down to the server
- Server parses and evaluates query, returns result
- Used in DB2, Oracle, MS SQL Server
Data Shipping
- Client parses query and requests data from server
- Server provides data, then client executes query
- Data can be cached at client (main memory or disk)
Evaluation
- Query Shipping
- Reliant on server performance
- Scales poorly with increasing client load
- Data Shipping
- Good scalability
- High communication costs
- Hybrid
- Potential to outperform other options
- More complex optimizations
Hybrid Shipping Observations
- Some observations of optimal performance
using hybrid shipping
- Preference to not use a client cache
- If network transfer cost < client access cost
- Shipping down cached data
- If in main memory & execution at server
- Multiple small updates
- Maintain at client and post to server only when necessary
Distributed Query Plans
- Each operator is annotated with a logical site
of execution – plans are shareable
- client means an operator is executed from the
client where the query is issued
- server means:
- for scan operators, execute at a location that has the necessary data
- for updates, execute at all locations with the relevant data
Query Optimization: Where?
- Should optimization occur at the client or the
server?
- At client: less load on servers, better
scalability
- At server: more information about system
statistics, especially server loads
- Potential solution: primary parsing and query
rewriting at client, further optimization at
server
Query Optimization: When?
- Tradeoff of accuracy vs. cost
- Traditional-style: optimize once, store plan
- No support for changing DB conditions
- No incurred cost for query execution
- Plan sets: optimize for possible scenarios
- Generate a few query plans for diff. conditions
- Choose plans based on runtime statistics
- On-the-fly: observe intermediate results
- Re-optimize query if different from expectations
Query Optimization: Two-Step
- Compile-time: generate join order, etc.
- Runtime: perform site selection
- Reasonable cost at each end
- Responds well to changing server loads
- Fully utilizes client data caching