



111
Systems Programming
Fundamental Issues In Distributed Systems







Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Description about Systems Programming, Fundamental Issues In Distributed Systems, Heterogeneity, Fundamental Issues In Distributed Systems ,Location transparency , Replication transparency .
Typology: Study notes
1 / 20

This page cannot be seen from the preview
Don't miss anything!
111
2
Fundamental Issues In Distributed Systems – Heterogeneity 1
A homogenous system is one in which all computers are the same.
A heterogeneous system is one in which the computers differ.
There are several ways in which heterogeneity can arise:
Performance heterogeneity (configuration heterogeneity) Differences in: Processor speed, Memory size, Memory speed, Disk size, Disk speed etc.
These differences must be taken into account when scheduling tasks at the system level. For example, distributed schedulers and load sharing schemes decide where to place each task.
Performance heterogeneity is introduced: when new computers are added to existing systems, when upgrades occur (memory, disk etc.) when powerful computers are built specifically to host services.
4
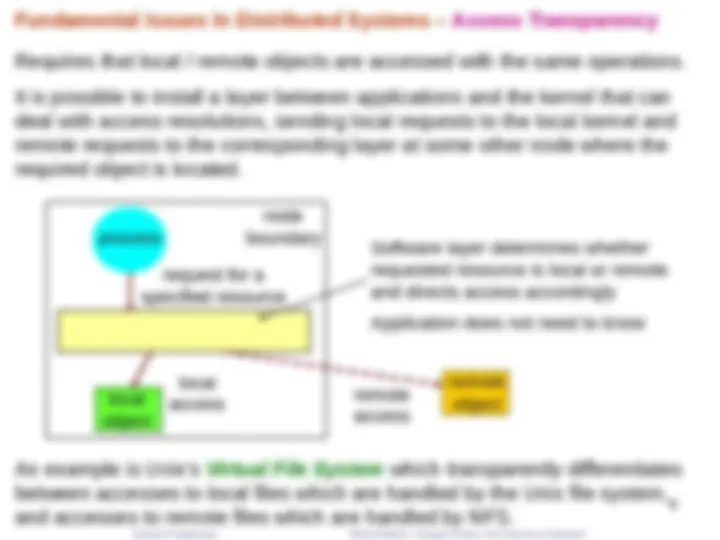
Fundamental Issues In Distributed Systems – Access Transparency
Requires that local / remote objects are accessed with the same operations.
It is possible to install a layer between applications and the kernel that can deal with access resolutions, sending local requests to the local kernel and remote requests to the corresponding layer at some other node where the required object is located.
An example is Unix's Virtual File System which transparently differentiates between accesses to local files which are handled by the Unix file system, and accesses to remote files which are handled by NFS.
Software layer determines whether requested resource is local or remote and directs access accordingly Application does not need to know
local object
remote object
process
request for a specified resource
local access remote access
node boundary
5
Fundamental Issues In Distributed Systems – Location transparency
Requires that objects can be accessed without knowledge of their location.
Remote Procedure Call (RPC) and Remote Method Invocation (RMI) require that the client know the location of the server object (usually supplied as a parameter to the local invocation). Thus RPC and RMI are not location transparent.
Object Request Brokers (ORB) automatically map object requests onto remote methods and are thus location transparent.
Multicast and broadcast communication is inherently location transparent. A group of peer processes can communicate without knowledge of location or group size.
A directory service such as the Domain Name System (DNS) can be used to find the location of a resource or service when such information is required.
7
It is vital to ensure the consistency of non-read-only copies of data resources – but this is also a significant challenge.
There are several different Update Strategies to propagate updates to multiple replicas.
The simplest being to only allow write access at one replica, the others are read-only access. The costs of updating the replicas must be weighed up against the benefits of having the (possibly read-write) replicas.
Fundamental Issues In Distributed Systems – Replication transparency 2
Primary
Read Write
Backup
Read Write
Update
Master
Read Write Read
Updates
Slave
Read
Slave
Read
Slave Peer
Read Write
Updates
Peer
Read Write
Peer
Read Write
Some alternative models for server replication
8
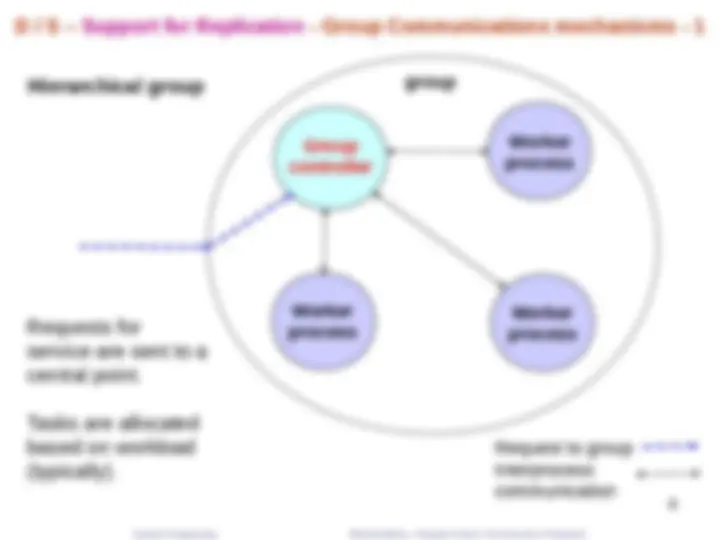
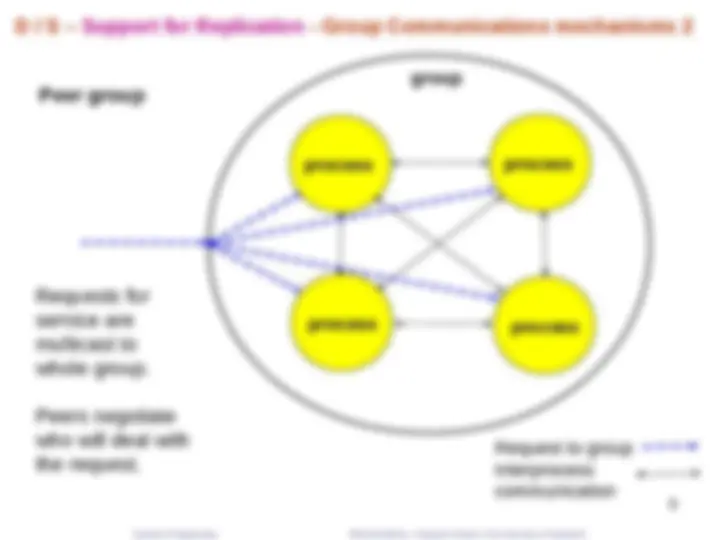
D / S – Support for Replication - Group Communications mechanisms - 1
Worker process
Group controller
Worker process
Worker process
Hierarchical group^ group
Request to group Interprocess communication
Requests for service are sent to a central point.
Tasks are allocated based on workload (typically).
10
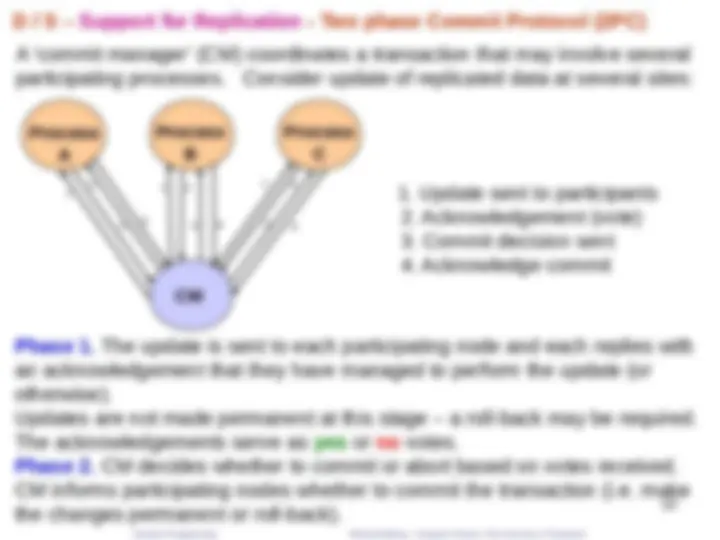
A ‘commit manager’ (CM) coordinates a transaction that may involve several participating processes. Consider update of replicated data at several sites:
Phase 1. The update is sent to each participating node and each replies with an acknowledgement that they have managed to perform the update (or otherwise). Updates are not made permanent at this stage – a roll-back may be required. The acknowledgements serve as yes or no votes. Phase 2. CM decides whether to commit or abort based on votes received. CM informs participating nodes whether to commit the transaction (i.e. make the changes permanent or roll-back).
CM
Process A
Process B
Process C
1 2 1 2 1 2 (^3 43 4 )
D / S – Support for Replication - Two phase Commit Protocol (2PC)
11
Fundamental Issues In Distributed Systems – Concurrency transparency
Requires that concurrent processes can share objects without interference.
Concurrent access to data objects raises the issue of data consistency.
Client/Server applications must ensure that multiple clients do not simultaneously attempt to update the same data item held at the server, thus avoiding the problem of lost updates.
►Demonstration of lost update with ‘notepad’◄
Some databases ensure consistency by locking entire tables during updates. Others provide row-level consistency, increasing transparency by allowing concurrent access at the table level.
Client 1 process Server process Client 2 process Local cache (^7) # seats available 7 Local cache 7 Book 2 seats 5 Book 3 seats (^4)
T I M E
The lost-update problem (in an airline seat booking scenario)
13
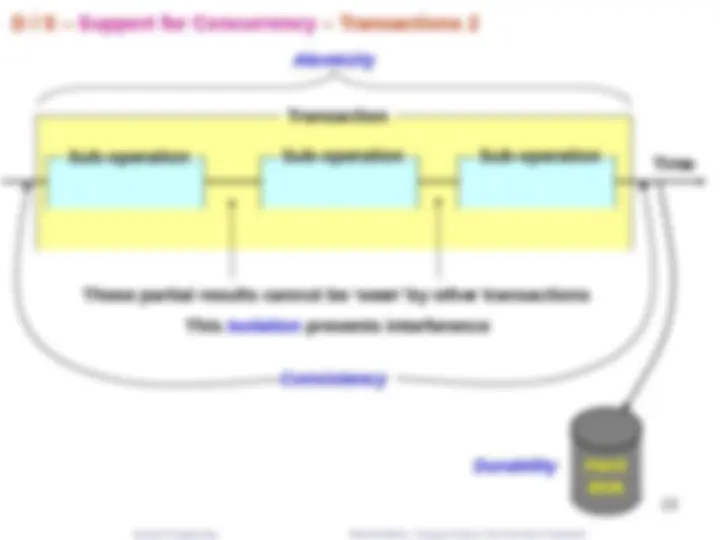
D / S – Support for Concurrency – Transactions 2
Time
These partial results cannot be ‘seen’ by other transactions This Isolation prevents interference
Transaction
Sub-operation^ Sub-operation^ Sub-operation
Consistency
Atomicity
Durability Hard disk
14
Fundamental Issues In Distributed Systems – Migration transparency
Requires that objects can be moved without affecting the operation of applications that use those objects, and that processes can be moved without affecting their operations or results.
In the case of data object or file migration, access requests from processes using the object must be transparently redirected to the object's new location.
Task transfers can be achieved preemptively or non preemptively.
Non preemptive transfers are done before the task starts to execute so the transfer is much simpler to achieve.
Preemptive transfers involve moving a process in mid-execution. Its execution state and environment must be preserved during the transfer.
Transparent process migration has been achieved in a number of distributed operating systems including Sprite, V and MOSIX, and load sharing schemes including the Process Migration Subsystem and ASLB.
16
RPC / RMI are high level protocols that provide communication abstraction. Low-level communication detail is hidden from the application by the RPC layer at each computer and certain communication faults are masked.
They automatically deal with errors associated with connection set up and teardown, and transient errors such as packet corruption or loss.
TCP is less transparent than RPC or RMI; the programmer must handle errors that occur at connection setup and teardown.
UDP provides no transparency; the application programmer must provide functionality to deal with all possible communication errors.
Fundamental Issues In Distributed Systems – Failure transparency 2
17
Fundamental Issues In D/S – Support for failure transparency
A popular technique to provide a high degree of failure transparency is to replicate processes at several nodes.
Election algorithms are used to mask the failure of centralised components. This approach is popular in services that need a co-ordinator. On failure of the co-ordinator, a service member process at a different site will take over the role.
The extent to which the original failure is masked is dependent on the internal design of the service, in particular the way in which state is managed.
Another approach is to periodically checkpoint remotely executing processes so that in the event of failure of the remote node the process can be re- started elsewhere, as for example in the Condor load sharing scheme.
Slave state (^) Master state
Elected as new leader
Demoted
Generic state transition diagram for 2-state Election Algorithm
19
Fundamental Issues In Distributed Systems – Scaling transparency
Requires that it should be possible to scale-up an application, service or system without changing the system structure or algorithms.
A system that exhibits performance transparency is much more likely to be extensible than one that does not.
Scaling transparency is largely dependent on efficient design, in terms of the use of resources, and especially in terms of communication.
Centralised components can become bottlenecks as the number of clients or service requests increases. Data tables grow causing scaling problems; the time taken to process each request will grow due to the increased time needed to search the larger table. A backlog of requests can build up.
Totally distributed applications avoid the scale pitfalls of centralised components but tend to have greater total communication requirements.
Partitioning nodes into groups or clusters can reduce communication and management overhead, thereby increasing extensibility.
Hierarchical design improves scalability – as with Domain Name Service.
20
D / S – Communication Complexity - Impact on scalability
Communication complexity is a measure of the ‘coupling’ of components – higher communication complexity reduces scalability.
Assume a system of N nodes: If each component communicates with one other, the communication complexity is said to be N.
If each component communicates with all other nodes, the communication complexity is N (N-1) = N^2 - N.
Low communication complexity
High communication complexity