



Statistics for the Behavioral
Sciences
Tests for Ranked Data, Choosing
Statistical Tests
Docsity.com













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of statistical tests for ranked data and non-normal distributions, including transformations and rank order tests. It covers the pros and cons of using nonparametric tests and discusses specific tests such as the mann-whitney u test and the wilcoxon t test. It also includes examples of calculating u and interpreting the results.
Typology: Slides
1 / 21

This page cannot be seen from the preview
Don't miss anything!
Tests for Ranked Data, Choosing Statistical Tests
Tranformations (pg 382):
The shape of the distribution can be changed by applying a math operation to all observations in the data set. Square roots, logs, normalization (standardization).
Rank order tests (pg 387):
Use a nonparametric statistic that has different assumptions about the shape of the underlying distribution.
A parameter is any descriptive measure of a population, such as a mean.
Nonparametric tests make no assumptions about the form of the underlying distribution.
Nonparametric tests are less sensitive and thus more susceptible to Type II error.
When the distribution is known to be non-normal. When a small sample (n < 10) contains extreme values. When two or more small samples have unequal variances.
When the original data consists of ranks instead of values.
Convert data in both samples to ranks. With ties, rank all values then give all equal values the mean rank.
Add the ranks for the two groups.
Substitute into the formula for U.
U is the smaller of U 1 and U 2.
Look up U in the U table.
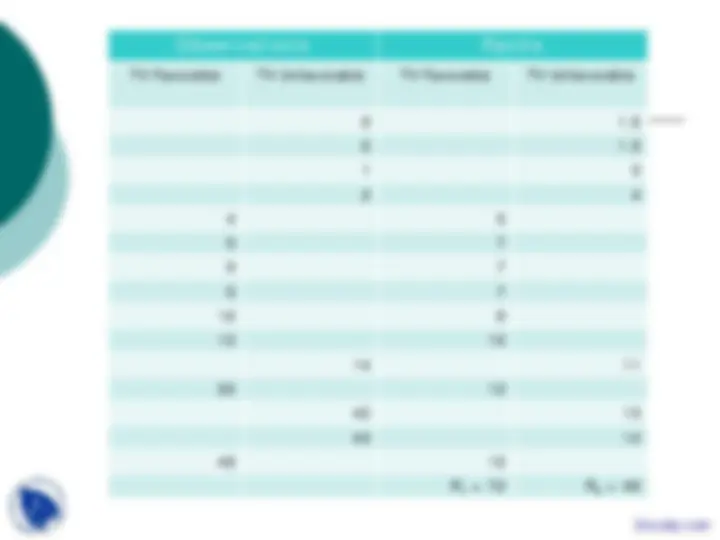
Observations Ranks TV Favorable TV Unfavorable TV Favorable TV Unfavorable
0 1. 0 1. 1 3 2 4 4 5 5 7 5 7 5 7 10 9 12 10 14 11 20 12 42 13 43 14 49 15 R 1 = 72 R 2 = 48
H 0 : Population distribution 1 = population distribution 2 H 1 : Population distribution 1 ≠ population distribution 2
Look up critical values in U Table.
Instead of degrees of freedom, use n’s for the two groups to find the cutoff.
Since 20 is larger than 10, retain the null (not reject).
U represents the number of times individual ranks in the lower group exceed those in the higher group.
When all values in one group exceed those in the other, U will be
Reject the null (equal groups) when U is less than the critical U in the table.
Equivalent to paired-sample t-test but used with non-normal distributions and ranked data.
Compute difference scores.
Rank order the difference scores.
Put plus ranks in one group, minus ranks in the other. Sum the ranks.
Smallest value is T. Look up in T table. Reject null if < than critical T.
Equivalent to one-way ANOVA for ranked data or non-normal distributions.
Hypotheses: H 0 : Pop A = Pop B = Pop C H 1 : H 0 is false.
Convert data to ranks and then use the H formula.
With n > 4, look up in χ^2 table.
How you write the null and alternative hypothesis varies with the design of the study – so does the type of statistic.
Which table you use to find the critical value depends on the test statistic (t, F, χ 2 , U, T, H).
t and z tests can be directional.
Is data qualitative or quantitative?
If qualitative use Chi-square.
How many groups are there?
If two, use t-tests, if more use ANOVA
Is the design within or between subjects?
How many independent variables (IVs or factors) are there?
One-way ANOVA – for one IV, independent samples
Repeated Measures ANOVA – for one or more IVs where samples are repeated, matched or paired.
Two-way (factorial) ANOVA – for two or more IVs, independent samples.
Mixed ANOVA – for two or more IVs, between and within subjects.
Two samples, independent groups – Mann-Whitney (U). Like an independent sample t-test.
Two samples, paired, matched or repeated measures – Wilcoxon (T). Like a paired sample t-test.
Three or more samples, independent groups – Kruskal-Wallis (H). Like a one-way ANOVA.