Download The Crawler-Computer Sciences and Applications-Project Presentation and more Slides Applications of Computer Sciences in PDF only on Docsity!
The Crawler
The Crawler
◦ Program that browses world wide web in methodical manner and
automatically download web pages.
◦ A crawler can visit many sites to gather information that can be
further analyzed
◦ Serves different applications such as search engine.
With respect to this project we will define it as follows
“Web crawler is a program that will move from page to page
on web and retrieve those pages for serving other modules of
our search engine“
The Crawler
Crawler concepts
◦ Starts with a seed URLS
◦ Provided either manually or through some
program
◦ Crawler extract URLs within them and add
them to a data structure called frontier.
◦ What is frontier?
There are two ways in which this main loop
can stop
- Either frontier becomes empty
This case rarely happens because of high average
number of outlinks.
- Certain number of pages have been crawled
For Example: We have 10 GB repository that can
have approx. 2 million pages (compressed).
The Crawler
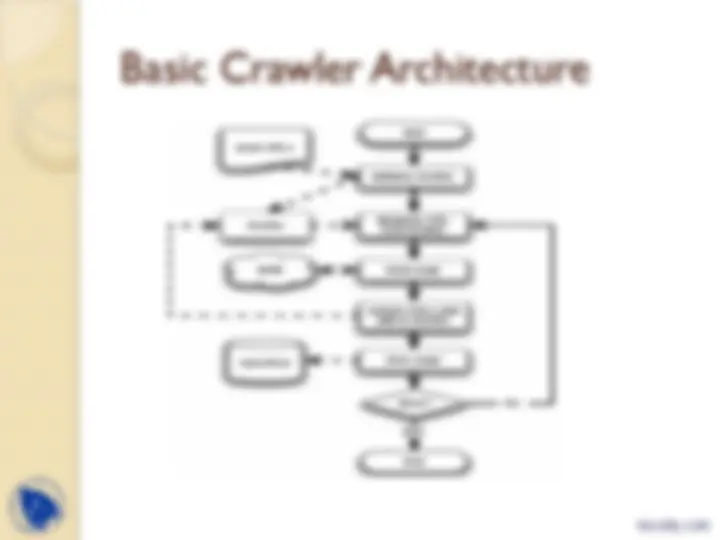
Basic Crawler Architecture
Crawler can be seen as a graph search
algorithm
◦ Pages representing nodes
◦ Links representing edges
Thus crawler starts with few of the nodes
(seeds)
And follow those edges to reach other nodes.
Thus the process of fetching page and
extracting links from it is analogous to
expanding a node in the graph search.
The Crawler
Basic Crawler Algorithm
Depending on the method of picking URL from the frontier we
present two crawler algorithms,
◦ Breadth first crawler ◦ Preferential crawler
Breadth first crawler
If frontier is implemented in FIFO (first in first out) then we have a
breadth first crawler.
URL to crawl comes from the head of the frontier queue
New URL is added to the tail of the queue
Preferential crawler
If frontier is maintained as a priority queue then we have a
preferential crawler.
Priority is based on the estimate of the value of the linkage page.
Design Issues
Is collection updated in batch-mode? Once our repository is filled we need to revisit those pages in order to maintain our local repository up-to-date. Depending on how crawler updates its collection, crawler can be classified as one of the following, Batch-mode crawler Steady crawler Batch-mode crawler This type of crawler runs periodically (say once a month) updating all pages in the collection in each crawl. Steady Crawler A steady crawler runs without any pause updating local collection continuously. In both type of crawler freshness averaged over time is same, if they visit pages at the same speed. Advantage of steady crawler over batch mode crawler is that it can gather pages at lower peek speed.
Design Issues
Is collection updated in-place? When crawler replace old version with the new one, it can adopt following two strategies
◦ In-place
◦ Shadowing
Shadowing
◦ New set of pages are collected from the web.
◦ Stored in a separate space from the current collection
◦ After all new pages are collected and processed, the current
collection is instantaneously replace by this new collection
In-place
◦ With in place update crawler collection is immediately available
to the user.
◦ Thus provides more freshness as compared to the the
shadowing.
Design Issues
Thus two possible crawlers and their advantage
Steady
In-place
Variable frequency ◦ High freshness ◦ Less load on the network/server. ◦ Known as incremental crawler. Batch-mode
Shadowing
Fixed frequency ◦ Easy to implement ◦ High availability of the collection to the user. ◦ Known as periodic crawler.
Implementation Issues
Fetching
◦ Crawler send HTTP request to the web servers and reads the response. ◦ The client parses response headers for status codes and redirections ◦ We may also need to store Last-modified header to determine the age of the document. ◦ We are going to fetch the page using cURL library.
Introduction to cURL
◦ cURL is command line tool for transferring files with URL syntax. ◦ libcurl is the corresponding library/API that users can incorporate into their programs. ◦ Strong point of cURL is that it supports number of protocols including. FTP, FTPS, HTTP, HTTPS, SCP, SFTP, TFTP, TELNET, DICT, LDAP, LDAPS and FILE. ◦ Binding to more than 30 different languages are available for libcurl.
Output
Implementation Issues
Robot Exclusion Protocol ◦ It is a convention used to stop crawlers from accessing particular parts of website. ◦ It is done by putting robot.txt file in the root folder. ◦ Next we will present format of robot.txt and also give some examples Format of Robot.txt ◦ consists of one or more records separated by one or more blank lines. Each record contains lines of the form ":”
◦ The record starts with one or more User-agent line, followed by one or more Disallow lines. ◦ User-agent: The value of this field is the name of the robot the record is describing access policy for. If more than one User-agent field is present the record describes an identical access policy for more than one robot. At least one field needs to be present per record. If the value is '*', the record describes the default access policy for any robot that has not matched any of the other records. ◦ Disallow: The value of this field specifies a partial URL that is not to be visited. This can be a full path, or a partial path; any URL that starts with this value will not be retrieved. Any empty value indicates that all URLs can be retrieved. The presence of an empty "/robots.txt" file has no explicit associated semantics, it will be treated as if it was not present, i.e. all robots will consider themselves welcome.
Implementation Issues
Parsing
◦ Once page have been downloaded we need to parse that page in order to extract URLs to be fed back into the crawler for further operation ◦ HTML parsers are freely available for many different languages. ◦ These parsers provide functionality to easily identify HTML tags and associated attribute-value pairs in a given HTML document. ◦ In order to extract hyperlinks from a web page, we can use these parsers to find anchor tags and grab the values of associated href attributes. ◦ Extracted URLs may either be relative or absolute. An Example of absolute URL is http://www.pieas.edu.pk/research , where as a relative URL may look like photo. jpg or /~soume n/. ◦ Relative URLs need to be interpreted with reference to an absolute base URL. For example, the absolute form of the second and third URLs with regard to the first are http://www.pieas.edu.pk/research/photo.jpg and http://www.pieas.edu.pk/~soumen/ (the starting “/” in /~soumen/ takes you back to the root of the Http server’s published file system).
Implementation Issues
Multithreading
Multi-threading, where each thread follows a crawling loop,
provides
◦ reasonable speed-up and ◦ efficient use of available bandwidth.
We need to lock the frontier in order to pick the next URL to
crawl.
After picking a URL it unlocks the frontier allowing other threads
to access it.
The frontier is again locked when new URLs are added to it.
The locking steps are necessary in order to synchronize the use of
the frontier that is now shared among many crawling loops
(threads).
For this purpose we can use mutex variable shared among all
threads of the crawler.