Download Function and Role of RNA Polymerase in Transcription and Protein Synthesis and more Schemes and Mind Maps Biology in PDF only on Docsity!
Ch 17 HW
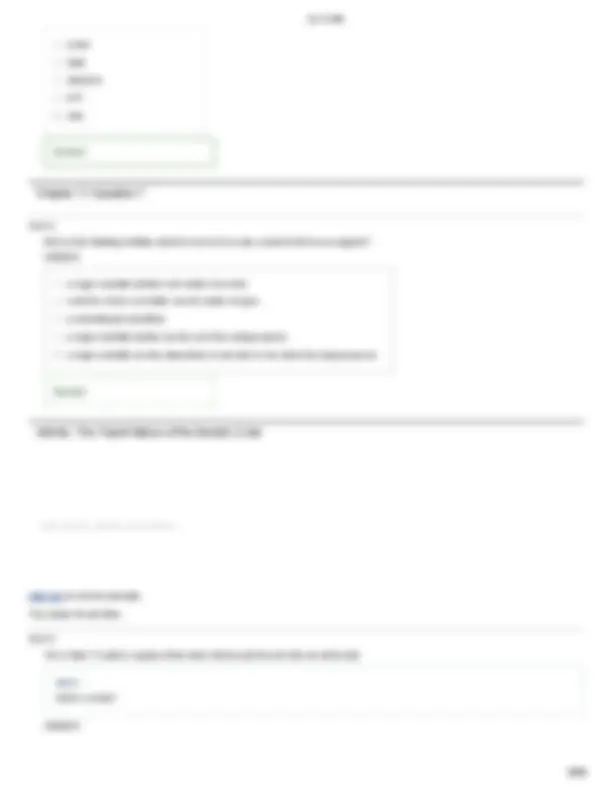
The Genetic Code
DNA is transcribed to messenger RNA (mRNA), and the mRNA is translated to proteins on the ribosomes. A sequence of three nucleotides on an mRNA molecule is called a codon. As you can see in the table, most codons specify a particular amino acid to be added to the growing protein chain. In addition, one codon (shown in blue) codes for the amino acid methionine and functions as a “start” signal. Three codons (shown in red) do not code for amino acids, but instead function as “stop” signals.
U C A G
U
UUU
Phe
UCU
Ser
UAU
Tyr
UGU
Cys
U
UUC UCC UAC UGC C
UUA
Leu
UCA UAA Stop UGA Stop A
UUG UCG UAG Stop UGG Trp G
C
CUU
Leu
CCU
Pro
CAU
His
CGU
Arg
U
CUC CCC CAC CGC C
CUA CCA CAA
Gln
CGA A
CUG CCG CAG CGG G
A
AUU
Ile
ACU
Thr
AAU
Asn
AGU
Ser
U
AUC ACC AAC AGC C
AUA ACA AAA
Lys
AGA
Arg
A
AUG Met orstart ACG AAG AGG G
G
GUU
Val
GCU
Ala
GAU
Asp
GGU
Gly
U
GUC GCC GAC GGC C
GUA GCA GAA
Glu
GGA A
GUG GCG GAG GGG G
Part A Understanding the genetic code
Use the table to sort the following ten codons into one of the three bins, according to whether they code for a start codon, an insequence amino acid, or a stop codon.
Drag each item to the appropriate bin.
Hint 1. How to interpret the table of codons
The table of codons shows the start codon in blue and the three stop codons in red. All other codons (shown in black) appear in the middle of the amino acid sequences that make up proteins. To read the table, locate the first letter in the codon on the left side of the table, then locate the second letter along the top, and the third letter down the right side of the table. Follow those letters across and down to identify the amino acid associated with that threeletter codon.
Hint 2. What is the start codon?
Identify the start codon.
ANSWER:
Hint 3. What are the stop codons?
Enter the three stop codons, separated by commas.
ANSWER:
ANSWER:
AUG
UAG, UGA, UAA
Correct
Nearly every mRNA gene that codes for a protein begins with the start codon, AUG, and thus begins with a methionine. Nearly every proteincoding sequence ends with one of the three stop codons (UAA, UAG, and UGA), which do not code for amino acids but signal the end of translation.
Part B Translation of mRNA
During translation, nucleotide base triplets (codons) in mRNA are read in sequence in the 5’ → 3’ direction along the mRNA. Amino acids are specified by the string of codons. What amino acid sequence does the following mRNA nucleotide sequence specify?
Express the sequence of amino acids using the threeletter abbreviations, separated by hyphens (e.g., MetSerThrLysGly).
Hint 1. How to approach the problem
First, subdivide the sequence into the individual threeletter codons. Then, refer to the table of codons to find the threeletter abbreviation for the amino acid that corresponds to each codon.
Hint 2. An example problem
This chart shows how to decode an example mRNA sequence. Labels indicating directionality (for example, 5’ → 3’) are not needed when writing amino acid sequences. Example mRNA sequence
Codon sequence
Amino acid sequence (threeletter abbreviation) Met^ Ser^ Thr^ Lys^ Gly
Hint 3. Can you identify the individual codons in the mRNA sequence?
To identify the amino acids specified by the mRNA sequence, you first need to subdivide the sequence into codons of three nucleotides each. This can be done by placing a space between each codon. Which of the following is the correct division of the codons for the sequence given? Look for the correct placement of spaces.
ANSWER:
Reset Help
5 ′^ − AUGGCAAGAAAA − 3 ′
5 ′^ − AUGUCGACUAAGGGA − 3 ′
AUG UCG ACU AAG GGA
AUG UGA UAG UAA
CAC AUC GCA AAA UGC
ACU
start/methionine stop codon amino acid
- Then, refer to the table of codons to identify the threeletter abbreviation for the amino acid that corresponds to each codon.
Hint 2. An example problem
This chart shows how to decode an example DNA sequence. Remember to first determine the mRNA sequence that is complementary to the DNA template strand’s sequence. Be sure to write the mRNA sequence in a 5’ to 3’ direction, and to use U to pair with A. Example DNA sequence (template strand)
Complementary DNA sequence
mRNA sequence
Codon sequence
Amino acid sequence (threeletter abbreviation) Met Leu Ser Arg His
Hint 3. What mRNA sequence is transcribed from the DNA sequence?
What mRNA nucleotide sequence would be transcribed from the DNA sequence in this problem?
ANSWER:
ANSWER:
Correct
Before mRNA can be translated into an amino acid sequence, the mRNA must first be synthesized from DNA through transcription. Base pairing in mRNA synthesis follows slightly different rules than in DNA synthesis: uracil (U) replaces thymine (T) in pairing with adenine (A). The codons specified by the mRNA are then translated into a string of amino acids.
Chapter 17 PreTest Question 4
Part A
What is the function of RNA polymerase?
Hint 1.
Compare RNA polymerase to DNA polymerase.
ANSWER:
3 ′^ − TACGAATCAGCTGTA − 5 ′
5 ′^ − ATGCTTAGTCGACAT − 3 ′
5 ′^ − AUGCUUAGUCGACAU − 3 ′
AUG CUU AGU CGA CAU
3 ′^ − TACAGAACGGTA − 5 ′
5 ′^ − ATGTCTTGCCAT − 3 ′
3 ′^ − TACAGAACGGTA − 5 ′
3 ′^ − AUGUCUUGCCAU − 5 ′
5 ′^ − AUGUCUUGCCAU − 3 ′
MetSerCysHis
It adds nucleotides to the 5' end of the growing mRNA molecule.
It relies on other enzymes to unwind the double helix.
It proceeds slowly along the DNA strand, requiring about a minute to add two nucleotides to the growing mRNA molecule.
It unwinds the double helix and adds nucleotides to a growing strand of RNA.
All of the above.
Correct
RNA polymerase has several functions in transcription, including unwinding the DNA double helix and adding RNA nucleotides.
Protein Synthesis (1 of 3): Overview (BioFlix tutorial)
In eukaryotic cells, the nuclear DNA codes for the synthesis of most of the cell’s proteins. Each step of protein synthesis occurs in a specific part of the cell. In addition, various forms of RNA play key roles in the processes of protein synthesis.
Before beginning this tutorial, watch the Protein Synthesis animation. Pay particular attention to the cellular locations where the various steps of protein synthesis occur in eukaryotic cells, as well as the different types of RNA and how they function.
Part A Locations of the processes involved in protein synthesis
In eukaryotic cells, the processes of protein synthesis occur in different cellular locations.
Drag the labels to the appropriate targets to identify where in the cell each process associated with protein synthesis takes place.
Hint 1. Some cellular components involved in protein synthesis move through the nuclear pores
The nuclear pores are holes in the nuclear envelope that permit many types of large molecules or aggregates of molecules to move between the nucleus and the cytoplasm. Two cellular components that pass through the nuclear pores are ribosomal subunits and fully processed RNA. What can you infer about where these cellular components are made?
Hint 2. What occurs during some key processes of protein synthesis?
Match these key processes involved in protein synthesis to descriptions of what occurs at each step.
ANSWER:
Reset Help
- The formation of a strand of RNA that is complementary to one strand of the nuclear DNA is called
transcription.
- The attachment of a free amino acid to a specific RNA molecule is the key step in
charging of tRNA.
- In translation , the nucleotide sequence of a piece of RNA is converted into a sequence of amino
acids in a polypeptide.
- The final RNA template for protein synthesis in eukaryotes is different from the RNA that was
produced from the DNA template because of RNA processing.
Drag the labels to the appropriate bins to identify the step in protein synthesis where each type of RNA first plays a role. If an RNA does not play a role in protein synthesis, drag it to the “not used in protein synthesis” bin.
Hint 1. The role of RNA primers
DNA synthesis (replication) and RNA synthesis differ in their needs for primer molecules.
In DNA replication, DNA polymerase cannot initiate the formation of a new strand of DNA directly from DNA nucleotides alone. Instead, the process requires an RNA primer to which the nucleotides of the new DNA strand attach. In RNA synthesis, in contrast, RNA polymerase can initiate the formation of a new strand of RNA without any primers.
This information should help you sort the “RNA primers” label in this problem.
Hint 2. How do tRNA and rRNA function in protein synthesis?
Both tRNA (transfer RNA) and rRNA (ribosomal RNA) play essential roles in protein synthesis.
Which two statements correctly describe the roles of tRNA and rRNA in protein synthesis?
ANSWER:
Hint 3. What is the role of mRNA in protein synthesis?
mRNA (messenger RNA) plays a key role in protein synthesis as the intermediate between the information encoded by a sequence of bases in DNA (a gene) and the sequence of amino acids that make up the protein product.
Which three statements correctly describe the role that mRNA plays in protein synthesis in eukaryotes?
ANSWER:
Hint 4. snRNAs and RNA processing
One stage of RNA processing in eukaryotes involves the removal of intronsnoncoding regions interspersed within the coding regions of the pre mRNA. In this RNA splicing process, the machinery that catalyzes the removal of introns (called the spliceosome) is composed of proteins and snRNAs (small nuclear RNAs). The snRNAs (and associated proteins) have two functions in the splicing process:
to bind to specific sequences of RNA that specify the location of the intron in the premRNA, and to catalyze the splicing process itself.
ANSWER:
rRNA is the major structural component of ribosomes and is involved in binding both mRNA and tRNAs.
tRNAs implement the genetic code, translating information from a sequence of nucleotides to the sequence of amino acids that make up a protein.
rRNA has many variations, each of which binds a specific amino acid.
tRNA transfers a nucleotide sequence from the DNA in the nucleus to the site of protein synthesis in the cytoplasm.
mRNA is the template for protein synthesis in translation.
mRNA carries genetic information from the nucleus to the cytoplasm.
mRNA links together amino acids, forming a polypeptide chain.
mRNA is the immediate product of transcription.
mRNA is produced only after the steps of RNA processing.
Correct
In eukaryotes, premRNA is produced by the direct transcription of the DNA sequence of a gene into a sequence of RNA nucleotides. Before this RNA transcript can be used as a template for protein synthesis, it is processed by modification of both the 5' and 3' ends. In addition, introns are removed from the premRNA by a splicing process that is catalyzed by snRNAs (small nuclear RNAs) complexed with proteins. The product of RNA processing, mRNA (messenger RNA), exits the nucleus. Outside the nucleus, the mRNA serves as a template for protein synthesis on the ribosomes, which consist of catalytic rRNA (ribosomal RNA) molecules bound to ribosomal proteins. During translation, tRNA (transfer RNA) molecules match a sequence of three nucleotides in the mRNA to a specific amino acid, which is added to the growing polypeptide chain.
RNA primers are not used in protein synthesis. RNA primers are only needed to initiate a new strand of DNA during DNA replication.
Part C Codon size and the genetic code
Life as we know it depends on the genetic code: a set of codons, each made up of three bases in a DNA sequence and corresponding mRNA sequence, that specifies which of the 20 amino acids will be added to the protein during translation. Imagine that a prokaryotelike organism has been discovered in the polar ice on Mars. Interestingly, these Martian organisms use the same DNA → RNA → protein system as life on Earth, except that
there are only 2 bases (A and T) in the Martian DNA, and there are only 17 amino acids found in Martian proteins.
Based on this information, what is the minimum size of a codon for these hypothetical Martian lifeforms?
Hint 1. What mathematical equation can you use to solve this problem?
A simple mathematical equation can correctly express the maximum number of codons that can be constructed from x different bases, with a codon length of y bases. Recall that for life on Earth,
there are 4 different bases (A, T, G, and C), a codon is 3 bases long, and there are a total of 64 possible codons that specify the 20 different amino acids (some amino acids are specified by more than one amino acid). This chart shows this redundancy in the genetic code for life on Earth.
U C A G
U
UUU
Phe
UCU
Ser
UAU
Tyr
UGU
Cys
U
UUC UCC UAC UGC C
UUA
Leu
UCA UAA Stop UGA Stop A
UUG UCG UAG Stop UGG Trp G
C CUU Leu CCU Pro CAU His
CGU Arg U
CUC CCC CAC CGC C
CUA CCA CAA Gln CGA A
Reset Help
premRNA snRNA mRNA tRNA rRNA RNA primers
transcription/RNA processing translation not used in protein synthesis
Correct
In the most general case of x bases and y bases per codon, the total number of possible codons is equal to xy^.
In the case of the hypothetical Martian lifeforms, is the minimum codon length needed to specify 17 amino acids is 5 (2 5 = 32), with some redundancy (meaning that more than one codon could code for the same amino acid).
For life on Earth, x = 4 and y = 3; thus the number of codons is 4^3 , or 64. Because there are only 20 amino acids, there is a lot of redundancy in the code (there are several codons for each amino acid).
Protein Synthesis (2 of 3): Transcription and RNA Processing (BioFlix tutorial)
In the process of transcription, the genetic information encoded in the sequence of bases that makes up a gene is “transcribed,” or copied in the same language, into a strand of RNA bases. The enzyme that catalyzes this reaction is called an RNA polymerase.
In eukaryotes, before the resulting strand (called pre mRNA) leaves the nucleus, it is processed in several ways. The product of this processing is the mRNA that functions as the template for protein synthesis outside the nucleus.
Before beginning this tutorial, watch the Transcription and RNA Processing animations. Pay particular attention to the base pairing that occurs during transcription and the various steps involved in RNA processing.
Transcription.
RNA Processing.
Part A Transcription of the DNA base sequence to RNA
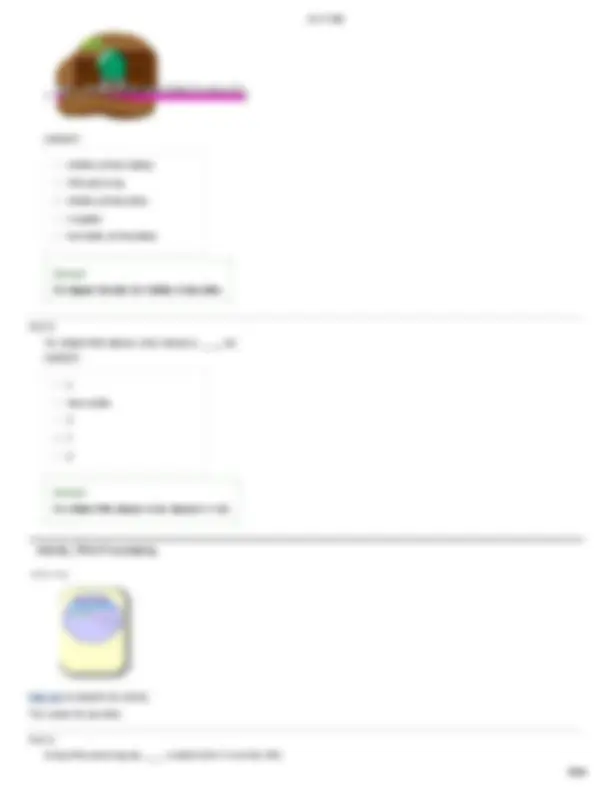
Suppose that a portion of doublestranded DNA in the middle of a large gene is being transcribed by an RNA polymerase. As the polymerase moves through the sequence of six bases shown in the diagram below, what is the corresponding sequence of bases in the RNA that is produced?
Enter the sequence of bases as capital letters with no spaces and no punctuation. Begin with the first base added to the growing RNA strand, and end with the last base added.
Hint 1. DNAtoRNA basepairing rules
Though the four nucleotide bases used to construct DNA are adenine (A), thymine (T), guanine (G), and cytosine (C), in RNA, the base uracil (U) is substituted for thymine. Thus, the basepairing rules in transcription are A→U, T→A, C→G, and G→C, where the first base is the coding base in the template strand of the DNA and the second base is the base that is added to the growing mRNA strand.
Hint 2. What are the coding strand and the template strand?
Doublestranded DNA is composed of two complementary strands of DNA. “Complementary” means that the bases on one strand pair in a specific way with the bases on the other strand: A with T and G with C. In a given gene, one strand of the DNA functions as the template strand, and the other is the coding strand.
Which two statements correctly describe the template and/or coding strands?
ANSWER:
Hint 3. Does RNA polymerase move in a set direction along the DNA during transcription?
RNA polymerase produces an RNA molecule from one of the two strands of DNA by transcribing the DNA base sequence to a complementary RNA base sequence.
Does RNA polymerase move in a set direction along a strand of DNA during transcription?
ANSWER:
Hint 4. The 3' and 5' ends of DNA and RNA
DNA and RNA molecules are very similar in structure. Both nucleic acids have a backbone composed of sugar molecules (deoxyribose in DNA; ribose in RNA) alternating with phosphate groups. A single base is attached to each sugar. The 3' end of each molecule has an exposed hydroxyl group (OH) from the sugar; the 5' end has a phosphate group.
ANSWER:
The four types of bases that are used in the coding strand are different from the types that are used in the template strand.
As the RNA polymerase moves along the DNA, the DNA bases on the coding strand are copied, producing the identical sequence of bases in the RNA transcript.
The template and coding strands are always antiparallel; that is, if one strand has its 3' end on the left and its 5' end on the right, the other strand has the opposite orientation.
During transcription, the DNA bases on the template strand are paired with their complementary RNA bases to form the RNA transcript.
Yes, the RNA polymerase moves in a direction that reads the bases of the DNA sequence from the 3' end toward the 5' end.
No; the RNA polymerase can move in either direction along the DNA strand because the same sequence of bases in the RNA will be produced regardless of direction.
Yes, the RNA polymerase moves in a direction that reads the bases of the DNA sequence from the 5' end toward the 3' end.
UGAGCC
Correct
In eukaryotes, binding of RNA polymerase II to DNA involves several other proteins known as transcription factors. Many of these transcription factors bind to the DNA in the promoter region (shown below in green), located at the 3' end of the sequence on the template strand. Although some transcription factors bind to both strands of the DNA, others bind specifically to only one of the strands. Transcription factors do not bind randomly to the DNA. Information about where each transcription factor binds originates in the base sequence to which each transcription factor binds. The positioning of the transcription factors in the promoter region determines how the RNA polymerase II binds to the DNA and in which direction transcription will occur.
Part C RNA processing
After transcription begins, several steps must be completed before the fully processed mRNA is ready to be used as a template for protein synthesis on the ribosomes.
Which three statements correctly describe the processing that takes place before a mature mRNA exits the nucleus?
Hint 1. What happens during RNA splicing?
Transcription of a typical eukaryotic gene initially produces a premRNA molecule that contains more than 25,000 nucleotides. In contrast, the final mRNA for the same gene contains only about 1,200 nucleotides. Production of the final mRNA that is used in translation involves removing these “extra” nucleotides.
Drag the terms on the left to the appropriate blanks on the right to complete the sentences. Not all terms will be used.
ANSWER:
ANSWER:
Reset Help
ribosomes
- Regions of the RNA transcript that contain noncoding bases are called introns. These regions
are not present in the mRNA that leaves the nucleus.
- In a process called splicing , noncoding regions of the RNA transcript are removed.
- Molecular complexes called spliceosomes carry out RNA splicing in the nucleus.
- The completed mRNA contains the gene's exons joined together in the correct order.
Correct
Once RNA polymerase II is bound to the promoter region of a gene, transcription of the template strand begins. As transcription proceeds, three key steps occur on the RNA transcript:
Early in transcription, when the growing transcript is about 20 to 40 nucleotides long, a modified guanine nucleotide is added to the 5' end of the transcript, creating a 5' cap. Introns are spliced out of the RNA transcript by spliceosomes, and the exons are joined together, producing a continuous coding region. A polyA tail (between 50 and 250 adenine nucleotides) is added to the 3' end of the RNA transcript.
Only after all these steps have taken place is the mRNA complete and capable of exiting the nucleus. Once in the cytoplasm, the mRNA can participate in translation.
Protein Synthesis (3 of 3): Translation and Protein Targeting Pathways (BioFlix tutorial)
Translation is the mRNAdirected synthesis of polypeptides. In translation, the information encoded in a sequence of RNA nucleotides is converted into a sequence of amino acids according to the genetic code. Translation also includes the first stage of targeting proteins to their eventual cellular location.
Before beginning this tutorial, watch the Translation and Protein Processing animations. You may refer back to these animations at any time during the tutorial.
Translation.
Protein Processing.
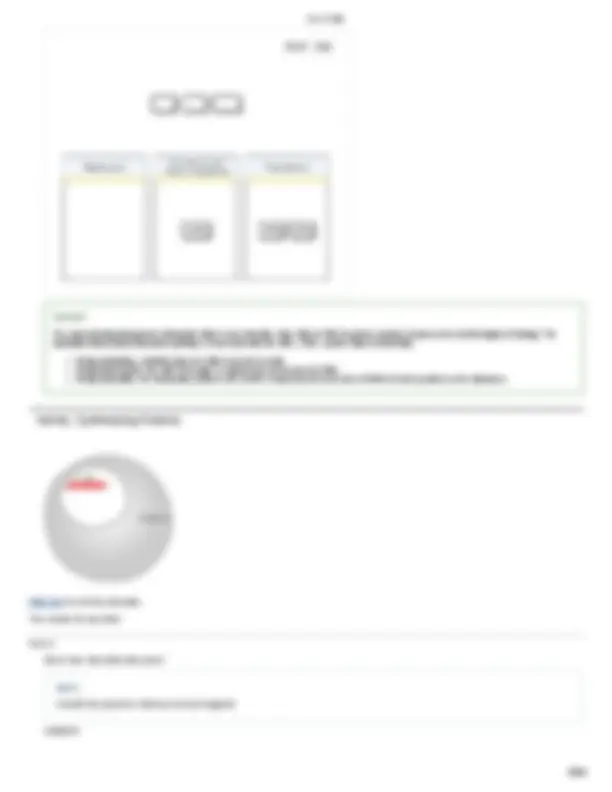
Part A tRNA interactions with mRNA and the ribosome
Ribosomes provide the scaffolding on which tRNAs interact with mRNA during translation of an mRNA sequence to a chain of amino acids. A ribosome has three binding sites, each of which has a distinct function in the tRNAmRNA interactions.
Drag the appropriate tRNAs to the binding sites on the ribosome to show the configuration immediately before a new peptide bond forms. Note that one of the binding sites should be left empty.
Hint 1. Binding of tRNAs to mRNA
A polyA tail (50250 adenine nucleotides) is added to the 3' end of the premRNA.
Noncoding sequences called introns are spliced out by molecular complexes called spliceosomes.
Coding sequences called exons are spliced out by ribosomes.
A cap consisting of a modified guanine nucleotide is added to the 5' end of the premRNA.
A translation stop codon is added at the 3' end of the premRNA.
Correct
During translation, new amino acids are added one at a time to the growing polypeptide chain. The addition of each new amino acid involves three steps:
- Binding of the charged tRNA to the A site. This step requires correct basepairing between the codon on the mRNA and the anticodon on the tRNA.
- Formation of the new peptide bond. In the process, the polypeptide chain is transferred from the tRNA in the P site to the amino acid on the tRNA in the A site.
- Movement of the mRNA through the ribosome. In this step, the discharged tRNA shifts to the E site (where it is released) and the tRNA carrying the growing polypeptide shifts to the P site.
Part B Predicting the effect of a point mutation
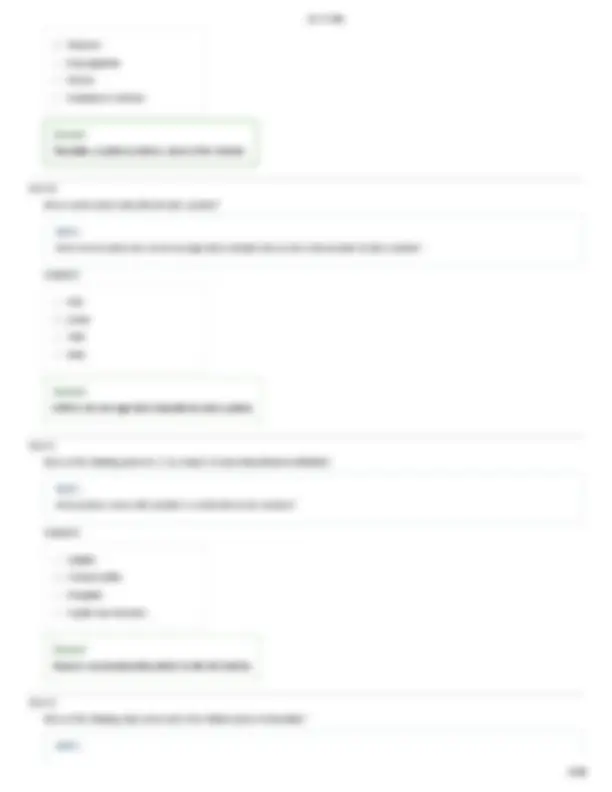
The diagram below shows an mRNA molecule that encodes a protein with 202 amino acids. The start and stop codons are highlighted, and a portion of the nucleotide sequence in the early part of the molecule is shown in detail. At position 35, a single basepair substitution in the DNA has changed what would have been a uracil (U) in the mRNA to an adenine (A).
U C A G
U
UUU
Phe
UCU
Ser
UAU
Tyr
UGU
Cys
U
UUC UCC UAC UGC C
UUA
Leu
UCA UAA Stop UGA Stop A
UUG UCG UAG Stop UGG Trp G
C
CUU
Leu
CCU
Pro
CAU
His
CGU
Arg
U
CUC CCC CAC CGC C
CUA CCA CAA
Gln
CGA A
CUG CCG CAG CGG G
A
AUU
Ile
ACU
Thr
AAU
Asn
AGU
Ser
U
AUC ACC AAC AGC C
AUA ACA AAA
Lys
AGA
Arg
A
AUG Met orstart ACG AAG AGG G
G
GUU
Val
GCU
Ala
GAU
Asp
GGU
Gly
U
GUC GCC GAC GGC C
GUA GCA GAA
Glu
GGA A
GUG GCG GAG GGG G
Based on the genetic code chart above, which of the following would be the result of this single basepair substitution?
Hint 1. Identifying the codons in an mRNA sequence
The genetic code, which converts a sequence of bases in mRNA to the sequence of amino acids in a protein, is written in codons, each consisting of three bases. These codons are read sequentially beginning at the start codon (AUG), which establishes the proper “reading frame,” or sets of three bases. The codons do not overlap, and there are no unused bases between the codons.
Hint 2. What is a frameshift mutation?
Frameshift mutations alter the reading frame of the genetic message encoded in the mRNA and typically have disastrous effects on the resulting protein.
Which of the following mutations would result in a frameshift mutation? Select all that apply.
ANSWER:
Hint 3. What are nonsense, missense, and silent mutations?
Nonsense, missense, and silent mutations can all be caused by a single basepair substitution in the coding region of a gene.
Drag the terms on the left to the appropriate blanks on the right to complete the sentences.
deletion of two sequential nucleotides in the coding region of the gene
insertion of a single nucleotide in the coding region of a gene
substitution of a single nucleotide in the coding region of a gene
insertion of a single nucleotide in the 5' UTR (untranslated region) of the gene
deletion of three sequential nucleotides in the coding region of a gene
Hint 2. How do proteins that will function in a cell’s endomembrane system and proteins that are secreted from the cell compare?
Proteins that are secreted from the cell and proteins that function in compartments of the endomembrane system (such as lysosomes or vacuoles) share some common features in their synthesis and/or targeting to their final destinations.
Which of the following statements are true about these two types of proteins? Select all that apply.
ANSWER:
Hint 3. What is the eventual (final) cellular location of proteins translated on free ribosomes?
Proteins may either be translated on free ribosomes or on ribosomes bound to the ER.
What is the cellular destination of the majority of proteins that are translated on free ribosomes?
ANSWER:
Hint 4. Review the animation showing the translation and secretion of insulin
Both types of proteins are translated on ribosomes that are bound to the ER.
The Golgi apparatus modifies and sorts proteins to be delivered to the endomembrane system, but does not modify and sort proteins to be secreted from the cell.
Proteins to be secreted are released from the cell when the vesicles containing them fuse with the plasma membrane.
Transport between the membranes and compartments of the endomembrane system, including the plasma membrane, is via small vesicles that bud from one compartment and fuse with the next.
any membrane of the endomembrane system
outside the cell (secreted)
any compartment of the endomembrane system
the cytoplasm
anywhere in the cell
ANSWER:
Correct
There are two general targeting pathways for nuclearencoded proteins in eukaryotic cells.
Proteins that will ultimately function in the cytoplasm (PFK, for example) are translated on free cytoplasmic ribosomes and released directly into the cytoplasm. Proteins that are destined for the membranes or compartments of the endomembrane system, as well as proteins that will be secreted from the cell (insulin, for example), are translated on ribosomes that are bound to the rough ER.
For proteins translated on rough ER, the proteins are found in one of two places at the end of translation. If a protein is targeted to a membrane of the endomembrane system, it will be in the ER membrane. If a protein is targeted to the interior of an organelle in the endomembrane system or to the exterior of the cell, it will be in the lumen of the rough ER. From the rough ER (membrane or lumen), these noncytoplasmic proteins move to the Golgi apparatus for processing and sorting before being sent to their final destinations.
AP Exam Prep Question 33
Part A
SECOND BASE
U C A G
[ ] ⎡^
UCU ⎤
[ ] [ ]