


Lecture 11: Mean-shift and
Normalized Cuts
Segmentation
CAP 5415
Fall 2009


































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An in-depth exploration of mean-shift and normalized cuts, two popular methods for image segmentation. The basics of kernel density estimation, mean-shift algorithm, and its relation to normalized cuts. Additionally, it discusses the concept of graphs, minimum cuts, and normalized cuts in the context of image segmentation. The document also includes examples and results.
Typology: Study notes
1 / 42

This page cannot be seen from the preview
Don't miss anything!
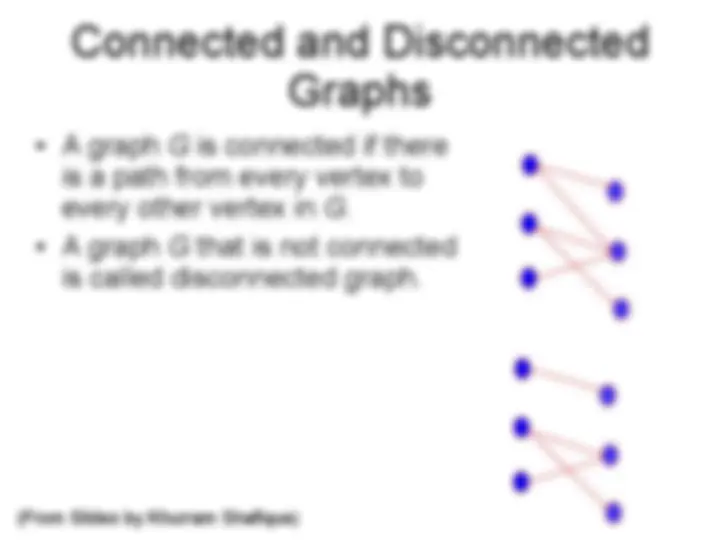
(From Slides by Khurram Shafique)
a e d c b
Adjacency Matrix: W One Row Per Node (Based on Slides by Khurram Shafique)
[ 0 1 3 ∞ ∞ 1 0 4 ∞ 2 3 4 0 6 7 ∞ ∞ 6 0 1 ∞ 2 7 1 0 ] Weight Matrix: W (Based on Slides by Khurram Shafique)
(Images from Khurram Shafique)