



1
Stochastic Methods
Topic:
The Metropolis Algorithm
Dr. Nasir M Mirza
Computational Physics
Computational Physics
Email: [email protected]
Docsity.com








Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Dr. Nasir M Mirza discussed following points in this lecture at Pakistan Institute of Engineering and Applied Sciences, Islamabad (PIEAS): Metropolis, Algorithm, Dimensions, Results, Error, Estimations, Direct, Error, Estimation
Typology: Slides
1 / 16

This page cannot be seen from the preview
Don't miss anything!
Dr. Nasir M Mirza
Computational Physics^ Computational Physics
Email: [email protected]
Docsity.com
Docsity.com
4
}. 1 , 1 {
}; 1 , 1 {
}; 1 , 1 { − Δ
= ′
− Δ
= ′
− Δ
= ′
i
i
i
i
i
i
z
z
y
y
x
x
The Metropolis Algorithm^ 4.
Docsity.com
The Metropolis Algorithm^ It is equivalent to finding an equilibrium most quickly and efficiently.
Docsity.com
Results of Program for a pdf
Example: As a simple example wehave sampled the following pdf: nwalk
= 5000 = number of walkers
max_bins
= 40 = number of bins
Loops = 200 = for repeated iterations
The results are shown above for bothMC simulations and theoreticalvalues.
Docsity.com
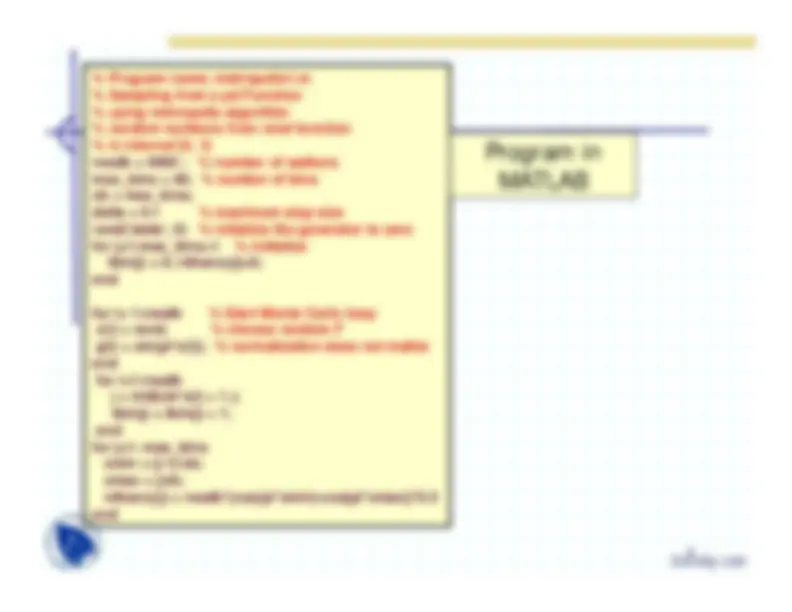
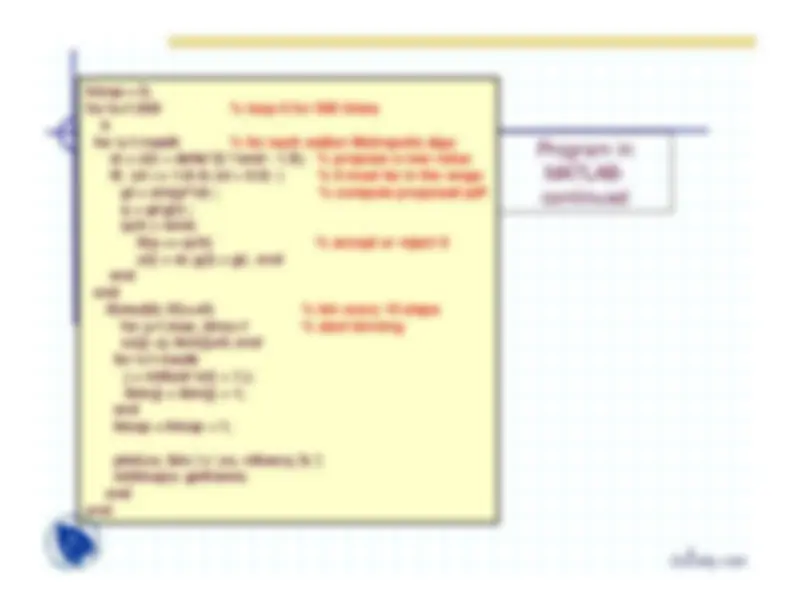
% Program name; metropolis1.m % Sampling from a pd Function % using metropolis algorithm % random numbers from rand function % in interval [0, 1] nwalk = 5000 ;
% number of walkers
max_bins = 40; % number of bins xb = max_bins; delta = 0.
% maximum step size
rand('state', 0)
% initialize the generator to zero
for j=1:max_bins+
% initialize
ibin(j) = 0; ntheory(j)=0; end for i= 1:nwalk
% Start Monte Carlo loop
x(i) = rand;
% choose random F
g(i) = sin(pix(i)); % normalization does not matter end for i=1:nwalk*
j = int8(xbx(i) + 1.); ibin(j) = ibin(j) + 1; end for j=1: max_bins^ xmin = (j-1)/xb;^ xmax = j/xb;^ ntheory(j) = nwalk(cos(pixmin)-cos(pixmax))0.5 end*
Program in
MATLAB
Docsity.com
Docsity.com
Direct error estimation
Assume that the calculation calls for the simulation of
particle
histories.
Assign and accumulate the value
the
Assign as well the square of the
score
for i’th history.
Calculate the mean value of
Assume that
x
is a quantity we calculate during the course of a Monte
Carlo simulation,
i.e.
a scoring variable or simply a “score" or a \tally".
The output of a Monte Carlo calculation is usually useless unless wecan ascribe a probable error to it. The conventional approach to calculating the estimated error is as follows:
=
N i
i x
N
x^
1
1
Docsity.com
x
's i
and
x
In many cases, the estimation of means and variances using the methodsdescribed in the previous section is not feasible.feasible, then an alternative that is nearly as good is “batch statistics errorestimation". We present a procedure here^ Split the
histories into
n
statistical batches of w=
N/n
histories each. Note
that
n
must be “large enough". A standard choice is
n
= 30. The
accumulated quantity for each of these batches is called
sum
as a sum forj
the j’th batch. The sum
isj
w i
i
j^
x
sum
1
Then compute the mean value of x
∑=
n j
j
1
Docsity.com
Estimate the variance associated with the distribution of the
x
: j
∑
∑
=
=
− − = − − =
n j
j
n j
j
x^
x x n x x n
s^
1
2
2
1
2
2
) ( 1 1 ) ( 1 1
The estimated variance of
x
is the standard variance of the mean:
Report the final result as
x
x> ± s()
s^ n
x
s^
2 x
2
)
(^
= > <
Remarks: We use above equations with
n
fixed (at say, 30) because it gives a
reasonable estimate of the error in
x
Any large number will do, as long as we are within the range of applicability ofthe Central limit theorem. There is some evidence that the calculated statisticdepends weakly on the choice of
n
. Therefore, it is important to report how
your statistics were done when you publish your Monte Carlo results.
Docsity.com
az
n
n
− −
1
This method of combining errors effectively increases the value of
number of statistical batches used in the calculation. In view of the fact thatthe calculated statistics are thought to depend weakly on
(but only marginally so for the sake of consistency) to combine the
raw data) into the standard number of statistical batches.^ This is easy to do by initializing the data arrays to the results of theprevious run before the start of a new run.
Docsity.com