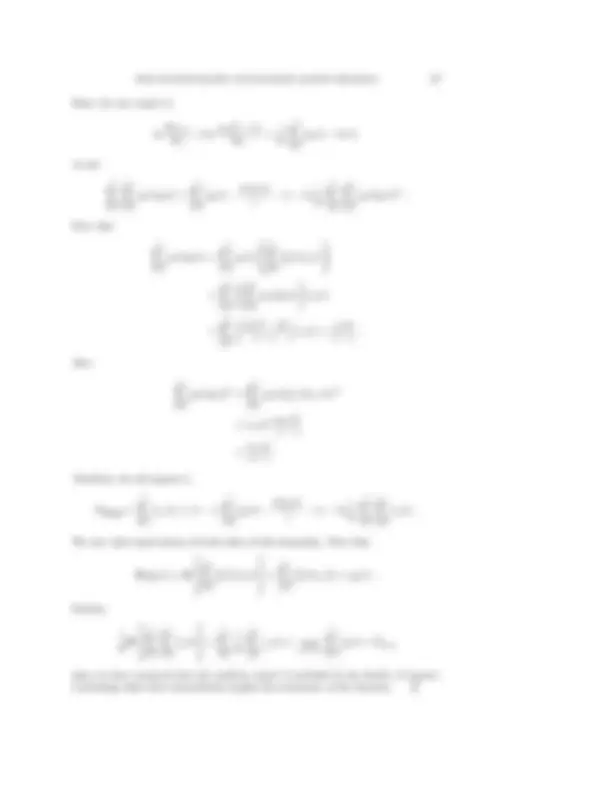Download Multiarmed Bandit Problem: Regret Analysis and Algorithms and more Papers Computer Graphics in PDF only on Docsity!
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM∗
PETER AUER†^ , NICOL O CESA-BIANCHI` ‡^ , YOAV FREUND§^ , AND ROBERT E. SCHAPIRE¶
SIAM J. COMPUT. ©c 2002 Society for Industrial and Applied Mathematics Vol. 32, No. 1, pp. 48–
Abstract. In the multiarmed bandit problem, a gambler must decide which arm of K non- identical slot machines to play in a sequence of trials so as to maximize his reward. This classical problem has received much attention because of the simple model it provides of the trade-off between exploration (trying out each arm to find the best one) and exploitation (playing the arm believed to give the best payoff). Past solutions for the bandit problem have almost always relied on assumptions about the statistics of the slot machines. In this work, we make no statistical assumptions whatsoever about the nature of the process generating the payoffs of the slot machines. We give a solution to the bandit problem in which an adversary, rather than a well-behaved stochastic process, has complete control over the payoffs. In a sequence of T plays, we prove that the per-round payoff of our algorithm approaches that of the best arm at the rate O(T −^1 /^2 ). We show by a matching lower bound that this is the best possible. We also prove that our algorithm approaches the per-round payoff of any set of strategies at a similar rate: if the best strategy is chosen from a pool of N strategies, then our algorithm approaches the per-round payoff of the strategy at the rate O((log N )^1 /^2 T −^1 /^2 ). Finally, we apply our results to the problem of playing an unknown repeated matrix game. We show that our algorithm approaches the minimax payoff of the unknown game at the rate O(T −^1 /^2 ).
Key words. adversarial bandit problem, unknown matrix games
AMS subject classifications. 68Q32, 68T05, 91A
PII. S
- Introduction. In the multiarmed bandit problem, originally proposed by Robbins [17], a gambler must choose which of K slot machines to play. At each time step, he pulls the arm of one of the machines and receives a reward or payoff (possibly zero or negative). The gambler’s purpose is to maximize his return, i.e., the sum of the rewards he receives over a sequence of pulls. In this model, each arm is assumed to deliver rewards that are independently drawn from a fixed and unknown distribution. As reward distributions differ from arm to arm, the goal is to find the arm with the highest expected payoff as early as possible and then to keep gambling using that best arm. The problem is a paradigmatic example of the trade-off between exploration and exploitation. On the one hand, if the gambler plays exclusively on the machine that he thinks is best (“exploitation”), he may fail to discover that one of the other arms actually has a higher expected payoff. On the other hand, if he spends too much time
∗Received by the editors November 18, 2001; accepted for publication (in revised form) July 7, 2002; published electronically November 19, 2002. An early extended abstract of this paper appeared in Proceedings of the 36 th Annual Symposium on Foundations of Computer Science, 1995, IEEE Computer Society, pp. 322–331. http://www.siam.org/journals/sicomp/32-1/39837.html †Institute for Theoretical Computer Science, Graz University of Technology, A-8010 Graz, Austria ([email protected]). This author gratefully acknowledges the support of ESPRIT Working Group EP 27150, Neural and Computational Learning II (NeuroCOLT II). ‡Department of Information Technology, University of Milan, I-26013 Crema, Italy (cesa-bianchi@ dti.unimi.it). This author gratefully acknowledges the support of ESPRIT Working Group EP 27150, Neural and Computational Learning II (NeuroCOLT II). §Banter Inc. and Hebrew University, Jerusalem, Israel ([email protected]). ¶AT&T Labs – Research, Shannon Laboratory, Florham Park, NJ 07932-0971 (schapire@research. att.com).
48
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 49
trying out all the machines and gathering statistics (“exploration”), he may fail to play the best arm often enough to get a high return. The gambler’s performance is typically measured in terms of “regret.” This is the difference between the expected return of the optimal strategy (pulling consistently the best arm) and the gambler’s expected return. Lai and Robbins proved that the gambler’s regret over T pulls can be made, for T → ∞, as small as O(ln T ). Furthermore, they prove that this bound is optimal in the following sense: there is no strategy for the gambler with a better asymptotic performance. Though this formulation of the bandit problem allows an elegant statistical treat- ment of the exploration-exploitation trade-off, it may not be adequate to model certain environments. As a motivating example, consider the task of repeatedly choosing a route for transmitting packets between two points in a communication network. To cast this scenario within the bandit problem, suppose there is a only a fixed number of possible routes and the transmission cost is reported back to the sender. Now, it is likely that the costs associated with each route cannot be modeled by a stationary distribution, so a more sophisticated set of statistical assumptions would be required. In general, it may be difficult or impossible to determine the right statistical assump- tions for a given domain, and some domains may exhibit dependencies to an extent that no such assumptions are appropriate. To provide a framework where one could model scenarios like the one sketched above, we present the adversarial bandit problem, a variant of the bandit problem in which no statistical assumptions are made about the generation of rewards. We assume only that each slot machine is initially assigned an arbitrary and unknown sequence of rewards, one for each time step, chosen from a bounded real interval. Each time the gambler pulls the arm of a slot machine, he receives the corresponding reward from the sequence assigned to that slot machine. To measure the gambler’s performance in this setting we replace the notion of (statistical) regret with that of worst-case regret. Given any sequence (j 1 ,... , jT ) of pulls, where T > 0 is an arbitrary time horizon and each jt is the index of an arm, the worst-case regret of a gambler for this sequence of pulls is the difference between the return the gambler would have had by pulling arms j 1 ,... , jT and the actual gambler’s return, where both returns are determined by the initial assignment of rewards. It is easy to see that, in this model, the gambler cannot keep his regret small (say, sublinear in T ) for all sequences of pulls and with respect to the worst-case assignment of rewards to the arms. Thus, to make the problem feasible, we allow the regret to depend on the “hardness” of the sequence of pulls for which it is measured, where the hardness of a sequence is roughly the number of times one has to change the slot machine currently being played in order to pull the arms in the order given by the sequence. This trick allows us to effectively control the worst-case regret simultaneously for all sequences of pulls, even though (as one should expect) our regret bounds become trivial when the hardness of the sequence (j 1 ,... , jT ) we compete against gets too close to T. As a remark, note that a deterministic bandit problem was also considered by Gittins [9] and Ishikida and Varaiya [13]. However, their version of the bandit problem is very different from ours: they assume that the player can compute ahead of time exactly what payoffs will be received from each arm, and their problem is thus one of optimization, rather than exploration and exploitation. Our most general result is a very efficient, randomized player algorithm whose ex- pected regret for any sequence of pulls is^1 O(S
KT ln(KT )), where S is the hardness (^1) Though in this introduction we use the compact asymptotic notation, our bounds are proven for each finite T and almost always with explicit constants.
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 51
play an unknown N -person finite game, where the same game is played repeatedly by N players. A desirable property for a player is Hannan-consistency, which is similar to saying (in our bandit framework) that the weak regret per time step of the player converges to 0 with probability 1. Examples of Hannan-consistent player strategies have been provided by several authors in the past (see [5] for a survey of these results). By applying (slight extensions of) Theorems 6.3 and 6.4, we can provide an example of a simple Hannan-consistent player whose convergence rate is optimal up to logarithmic factors. Our player algorithms are based in part on an algorithm presented by Freund and Schapire [6, 7], which in turn is a variant of Littlestone and Warmuth’s [15] weighted majority algorithm and Vovk’s [18] aggregating strategies. In the setting analyzed by Freund and Schapire, the player scores on each pull the reward of the chosen arm but gains access to the rewards associated with all of the arms (not just the one that was chosen).
- Notation and terminology. An adversarial bandit problem is specified by the number K of possible actions, where each action is denoted by an integer 1 ≤ i ≤ K, and by an assignment of rewards, i.e., an infinite sequence x(1), x(2),... of vectors x(t) = (x 1 (t),... , xK (t)), where xi(t) ∈ [0, 1] denotes the reward obtained if action i is chosen at time step (also called “trial”) t. (Even though throughout the paper we will assume that all rewards belong to the [0, 1] interval, the generalization of our results to rewards in [a, b] for arbitrary a < b is straightforward.) We assume that the player knows the number K of actions. Furthermore, after each trial t, we assume the player knows only the rewards xi 1 (1),... , xit (t) of the previously chosen actions i 1 ,... , it. In this respect, we can view the player algorithm as a sequence I 1 , I 2 ,... , where each It is a mapping from the set ({ 1 ,... , K} × [0, 1])t−^1 of action indices and previous rewards to the set of action indices. For any reward assignment and for any T > 0, let
GA(T )
def
∑^ T
t=
xit (t)
be the return at time horizon T of algorithm A choosing actions i 1 , i 2 ,.... In what follows, we will write GA instead of GA(T ) whenever the value of T is clear from the context. Our measure of performance for a player algorithm is the worst-case regret, and in this paper we explore variants of the notion of regret. Given any time horizon T > 0 and any sequence of actions (j 1 ,... , jT ), the (worst-case) regret of algorithm A for (j 1 ,... , jT ) is the difference
(1) G(j 1 ,...,jT ) − GA(T ),
where
G(j 1 ,...,jT )def =
∑^ T
t=
xjt (t)
is the return, at time horizon T , obtained by choosing actions j 1 ,... , jT. Hence, the regret (1) measures how much the player lost (or gained, depending on the sign of the difference) by following strategy A instead of choosing actions j 1 ,... , jT. A special
52 AUER, CESA-BIANCHI, FREUND, AND SCHAPIRE
case of this is the regret of A for the best single action (which we will call weak regret for short), defined by
Gmax(T ) − GA(T ),
where
Gmax(T ) def = max j
∑T
t=
xj (t)
is the return of the single globally best action at time horizon T. As before, we will write Gmax instead of Gmax(T ) whenever the value of T is clear from the context. As our player algorithms will be randomized, fixing a player algorithm defines a probability distribution over the set of all sequences of actions. All the probabili- ties P{·} and expectations E[·] considered in this paper will be taken with respect to this distribution. In what follows, we will prove two kinds of bounds on the performance of a (randomized) player A. The first is a bound on the expected regret
G(j 1 ,...,jT ) − E [GA(T )]
of A for an arbitrary sequence (j 1 ,... , jT ) of actions. The second is a confidence bound on the weak regret. This has the form
P {Gmax(T ) > GA(T ) + ε} ≤ δ
and states that, with high probability, the return of A up to time T is not much smaller than that of the globally best action. Finally, we remark that all of our bounds hold for any sequence x(1), x(2),... of reward assignments, and most of them hold uniformly over the time horizon T (i.e., they hold for all T without requiring T as input parameter).
- Upper bounds on the weak regret. In this section we present and analyze our simplest player algorithm, Exp3 (which stands for “exponential-weight algorithm for exploration and exploitation”). We will show a bound on the expected regret of Exp3 with respect to the single best action. In the next sections, we will greatly strengthen this result. The algorithm Exp3, described in Figure 1, is a variant of the algorithm Hedge introduced by Freund and Schapire [6] for solving a different worst-case sequential allocation problem. On each time step t, Exp3 draws an action it according to the distribution p 1 (t),... , pK (t). This distribution is a mixture of the uniform distribution and a distribution which assigns to each action a probability mass exponential in the estimated cumulative reward for that action. Intuitively, mixing in the uniform distribution is done to make sure that the algorithm tries out all K actions and gets good estimates of the rewards for each. Otherwise, the algorithm might miss a good action because the initial rewards it observes for this action are low and large rewards that occur later are not observed because the action is not selected. For the drawn action it, Exp3 sets the estimated reward ˆxit (t) to xit (t)/pit (t). Dividing the actual gain by the probability that the action was chosen compensates the reward of actions that are unlikely to be chosen. This choice of estimated rewards guarantees that their expectations are equal to the actual rewards for each action; that is, E[ˆxj (t) | i 1 ,... , it− 1 ] = xj (t), where the expectation is taken with respect to
54 AUER, CESA-BIANCHI, FREUND, AND SCHAPIRE
as desired. To apply Corollary 3.2, it is necessary that an upper bound g on Gmax(T ) be available for tuning γ. For example, if the time horizon T is known, then, since no action can have payoff greater than 1 on any trial, we can use g = T as an upper bound. In section 4, we give a technique that does not require prior knowledge of such an upper bound, yielding a result which uniformly holds over T. If the rewards xi(t) are in the range [a, b], a < b, then Exp3 can be used after the rewards have been translated and rescaled to the range [0, 1]. Applying Corollary 3. with g = T gives the bound (b − a)
e − 1
T K ln K on the regret. For instance, this is applicable to a standard loss model where the “rewards” fall in the range [− 1 , 0]. Proof of Theorem 3.1. The theorem is clearly true for γ = 1, so assume 0 < γ < 1. Here (and also throughout the paper without explicit mention) we use the following simple facts, which are immediately derived from the definitions:
(2) ˆxi(t) ≤ 1 /pi(t) ≤ K/γ,
∑^ K
i=
pi(t)ˆxi(t) = pit (t) xit (t) pit (t)
(3) = xit (t),
∑^ K
i=
pi(t)ˆxi(t)^2 = pit (t) xit (t) pit (t)
xˆit (t) ≤ xˆit (t) =
∑^ K
i=
(4) x ˆi(t).
Let Wt = w 1 (t) + · · · + wK (t). For all sequences i 1 ,... , iT of actions drawn by Exp3,
Wt+ Wt
∑^ K
i=
wi(t + 1) Wt
∑^ K
i=
wi(t) Wt
exp
( (^) γ K
xˆi(t)
∑^ K
i=
pi(t) − (^) Kγ 1 − γ
exp
( (^) γ K
ˆxi(t)
∑^ K
i=
pi(t) − (^) Kγ 1 − γ
[
γ K
xˆi(t) + (e − 2)
( (^) γ K
xˆi(t)
) 2 ]
γ K 1 − γ
∑^ K
i=
pi(t)ˆxi(t) +
(e − 2)( (^) Kγ )^2 1 − γ
∑^ K
i=
(7) pi(t)ˆxi(t)^2
γ K 1 − γ
xit (t) +
(e − 2)( (^) Kγ )^2 1 − γ
∑^ K
i=
(8) x ˆi(t).
Equation (5) uses the definition of pi(t) in Figure 1. Equation (6) uses the fact that ex^ ≤ 1 + x + (e − 2)x^2 for x ≤ 1; the expression in the preceding line is at most 1 by (2). Equation (8) uses (3) and (4). Taking logarithms and using 1 + x ≤ ex^ gives
ln
Wt+ Wt
γ K 1 − γ
xit (t) +
(e − 2)( (^) Kγ )^2 1 − γ
∑^ K
i=
ˆxi(t).
Summing over t we then get
ln
WT +
W 1
γ K 1 − γ GExp3 +
(e − 2)( (^) Kγ )^2 1 − γ
∑^ T
t=
∑^ K
i=
(9) ˆxi(t).
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 55
For any action j,
ln
WT +
W 1
≥ ln
wj (T + 1) W 1
γ K
∑^ T
t=
x ˆj (t) − ln K.
Combining this with (9), we get
GExp3 ≥ (1 − γ)
∑^ T
t=
x ˆj (t) −
K ln K γ
− (e − 2)
γ K
∑^ T
t=
∑^ K
i=
(10) ˆxi(t).
We next take the expectation of both sides of (10) with respect to the distribution of 〈i 1 ,... , iT 〉. For the expected value of each ˆxi(t), we have
E[ˆxi(t) | i 1 ,... , it− 1 ] = E
[
pi(t) ·
xi(t) pi(t)
]
(11) = xi(t).
Combining (10) and (11), we find that
E[GExp3] ≥ (1 − γ)
∑^ T
t=
xj (t) −
K ln K γ
− (e − 2)
γ K
∑^ T
t=
∑^ K
i=
xi(t).
Since j was chosen arbitrarily and
∑^ T
t=
∑^ K
i=
xi(t) ≤ K Gmax,
we obtain the inequality in the statement of the theorem. Additional notation. As our other player algorithms will be variants of Exp3, we find it convenient to define some further notation based on the quantities used in the analysis of Exp3. For each 1 ≤ i ≤ K and for each t ≥ 1, define
Gi(t + 1) def =
∑^ t
s=
xi(s),
G^ ˆi(t + 1) def =
∑^ t
s=
x ˆi(s),
G^ ˆmax(t + 1) def = max 1 ≤i≤K G^ ˆi(t + 1).
- Bounds on the weak regret that uniformly hold over time. In sec- tion 3, we showed that Exp3 yields an expected regret of O(
Kg ln K) whenever an upper bound g on the return Gmax of the best action is known in advance. A bound of O(
KT ln K), which holds uniformly over T , could be easily proven via the “guess- ing techniques” which will be used to prove Corollaries 8.4 and 8.5 in section 8. In this section, instead, we describe an algorithm, called Exp3. 1 , whose expected weak regret is O(
KGmax ln K) uniformly over T. As Gmax = Gmax(T ) ≤ T , this bound is never worse than O(
KT ln K) and is substantially better whenever the return of the best arm is small compared to T.
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 57
Proof. If Sr > Tr (so that no trials occur on epoch r), then the lemma holds trivially since both summations will be equal to zero. Assume then that Sr ≤ Tr. Let g = gr and γ = γr. We use (10) from the proof of Theorem 3.1:
∑^ Tr
t=Sr
xit (t) ≥
∑^ Tr
t=Sr
ˆxj (t) − γ
∑^ Tr
t=
ˆxj (t) − K ln K γ
− (e − 2) γ K
∑^ Tr
t=Sr
∑^ K
i=
x ˆi(t).
From the definition of the termination condition we know that Gˆi(Tr ) ≤ g − K/γ. Using (2), we get ˆxi(t) ≤ K/γ. This implies that Gˆi(Tr + 1) ≤ g for all i. Thus,
∑^ Tr
t=Sr
xit (t) ≥
∑^ Tr
t=Sr
ˆxj (t) − g (γ + γ(e − 2)) − K ln K γ
By our choice for γ, we get the statement of the lemma. The next lemma gives an implicit upper bound on the number of epochs R. Let c = (K ln K)/(e − 1). Lemma 4.3. The number of epochs R satisfies
2 R−^1 ≤
K
c
G^ ˆmax c
Proof. If R = 0, then the bound holds trivially. So assume R ≥ 1. Let z = 2R−^1. Because epoch R − 1 was completed, by the termination condition,
Gˆmax ≥ Gˆmax(TR− 1 + 1) > gR− 1 − K γR− 1
(12) = c 4 R−^1 − K 2 R−^1 = cz^2 − Kz.
Suppose the claim of the lemma is false. Then z > K/c +
G^ ˆmax/c. Since the
function cx^2 − Kx is increasing for x > K/(2c), this implies that
cz^2 − Kz > c
K
c
G^ ˆmax c
2
− K
K
c
G^ ˆmax c
= K
G^ ˆmax c
contradicting (12). Proof of Theorem 4.1. Using the lemmas, we have that
GExp3. 1 =
∑^ T
t=
xit (t) =
∑^ R
r=
∑^ Tr
t=Sr
xit (t)
≥ max j
∑R
r=
( T
∑r
t=Sr
x ˆj (t) − 2
e − 1
gr K ln K
= max j G^ ˆj (T + 1) − 2 K ln K
∑^ R
r=
2 r
= Gˆmax − 2 K ln K(2R+1^ − 1)
≥ Gˆmax + 2K ln K − 8 K ln K
K
c
G^ ˆmax c
= Gˆmax − 2 K ln K − 8(e − 1)K − 8
e − 1
(13) G^ ˆmaxK ln K.
58 AUER, CESA-BIANCHI, FREUND, AND SCHAPIRE
Here, we used Lemma 4.2 for the first inequality and Lemma 4.3 for the second inequality. The other steps follow from definitions and simple algebra. Let f (x) = x − a
x − b for x ≥ 0, where a = 8
e − 1
K ln K and b = 2K ln K + 8(e − 1)K. Taking expectations of both sides of (13) gives
(14) E[GExp3. 1 ] ≥ E[f ( Gˆmax)].
Since the second derivative of f is positive for x > 0, f is convex so that, by Jensen’s inequality,
(15) E[f ( Gˆmax)] ≥ f (E[ Gˆmax]).
Note that
E[ Gˆmax] = E
[
max j
G^ ˆj (T + 1)
]
≥ max j
E[ Gˆj (T + 1)] = max j
∑T
t=
xj (t) = Gmax.
The function f is increasing if and only if x > a^2 /4. Therefore, if Gmax > a^2 /4, then f (E[ Gˆmax]) ≥ f (Gmax). Combined with (14) and (15), this gives that E[GExp3. 1 ] ≥ f (Gmax), which is equivalent to the statement of the theorem. On the other hand, if Gmax ≤ a^2 /4, then, because f is nonincreasing on [0, a^2 /4],
f (Gmax) ≤ f (0) = −b ≤ 0 ≤ E[GExp3. 1 ],
so the theorem trivially follows in this case as well.
- Lower bounds on the weak regret. In this section, we state a lower bound on the expected weak regret of any player. More precisely, for any choice of the time horizon T we show that there exists a strategy for assigning the rewards to the actions such that the expected weak regret of any player algorithm is Ω(
KT ). Observe that this does not match the upper bound for our algorithms Exp3 and Exp3. 1 (see Corollary 3.2 and Theorem 4.1); it is an open problem to close this gap. Our lower bound is proven using the classical (statistical) bandit model with a crucial difference: the reward distribution depends on the number K of actions and on the time horizon T. This dependence is the reason why our lower bound does not contradict the upper bounds of the form O(ln T ) for the classical bandit model [14]. There, the distribution over the rewards is fixed as T → ∞. Note that our lower bound has a considerably stronger dependence on the num- ber K of action than the lower bound Θ(
T ln K), which could have been directly proven from the results in [3, 6]. Specifically, our lower bound implies that no upper bound is possible of the form O(T α(ln K)β^ ), where 0 ≤ α < 1, β > 0. Theorem 5.1. For any number of actions K ≥ 2 and for any time horizon T , there exists a distribution over the assignment of rewards such that the expected weak regret of any algorithm (where the expectation is taken with respect to both the ran- domization over rewards and the algorithm’s internal randomization) is at least
1 20
min{
KT , T }.
The proof is given in Appendix A. The lower bound implies, of course, that for any algorithm there is a particular choice of rewards that will cause the expected weak regret (where the expectation is now with respect to the algorithm’s internal randomization only) to be larger than this value.
60 AUER, CESA-BIANCHI, FREUND, AND SCHAPIRE
lemma shows that, for appropriate α, these are indeed upper confidence bounds. Fix some time horizon T. In what follows, we will use ˆσi to denote ˆσi(T + 1) and Gˆi to denote Gˆi(T + 1). Lemma 6.1. If 2
ln(KT /δ) ≤ α ≤ 2
KT , then
P
∃i : Gˆi + αˆσi < Gi
≤ δ.
Proof. Fix some i and set
st def =
α 2ˆσi(t + 1)
Since α ≤ 2
KT and ˆσi(t + 1) ≥
KT , we have st ≤ 1. Now
P
Gˆi + αˆσi < Gi
= P
{ T
t=
(xi(t) − xˆi(t)) −
α 2
σˆi >
α 2
σˆi
≤ P
sT
∑T
t=
xi(t) − xˆi(t) −
α 2 pi(t)
KT
α^2 4
= P
exp
sT
∑T
t=
xi(t) − xˆi(t) − α 2 pi(t)
KT
> exp
α^2 4
≤ e−α
(^2) / 4 E
[
exp
sT
∑T
t=
xi(t) − xˆi(t) −
α 2 pi(t)
KT
))]
where in step (16) we multiplied both sides by sT and used ˆσi ≥
∑T
t=1 1 /(pi(t)
KT ),
while in step (17) we used Markov’s inequality. For t = 1,... , T set
Zt^ def = exp
st
∑t
τ =
xi(τ ) − ˆxi(τ ) − α 2 pi(τ )
KT
Then, for t = 2,... , T
Zt = exp
st
xi(t) − ˆxi(t) −
α 2 pi(t)
KT
· (Zt− 1 )
st st− (^1).
Denote by Et [Zt] = E [Zt | i 1 ,... , it− 1 ] the expectation of Zt with respect to the random choice in trial t and conditioned on the past t − 1 trials. Note that when the past t − 1 trials are fixed the only random quantities in Zt are the ˆxi(t)’s. Note also that xi(t) − xˆi(t) ≤ 1 and that
Et
[
(xi(t) − ˆxi(t))^2
]
= Et
[
ˆxi(t)^2
]
− xi(t)^2 ≤ Et
[
ˆxi(t)^2
]
xi(t)^2 pi(t)
pi(t)
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 61
Hence, for each t = 2,... , T
Et [Zt] ≤ Et
[
exp st
xi(t) − ˆxi(t) −
st pi(t)
)]
(Zt− 1 )
st (19)^ st−^1
≤ Et
[
1 + st(xi(t) − ˆxi(t)) + s^2 t (xi(t) − ˆxi(t))^2
]
exp
s^2 t pi(t)
(Zt− 1 )
st (20)^ st−^1
1 + s^2 t /pi(t)
exp
s^2 t pi(t)
(Zt− 1 )
st (21)^ st−^1
≤ (Zt− 1 )
st (22)^ st−^1
(23) ≤ 1 + Zt− 1.
Equation (19) uses
α 2 pi(t)
KT
α 2 pi(t)ˆσi(t + 1)
st pi(t)
since ˆσi(t + 1) ≥
KT. Equation (20) uses ea^ ≤ 1 + a + a^2 for a ≤ 1. Equation (21) uses Et [ˆxi(t)] = xi(t). Equation (22) uses 1 + x ≤ ex^ for any real x. Equation (23) uses st ≤ st− 1 and zu^ ≤ 1 + z for any z > 0 and u ∈ [0, 1]. Observing that E [Z 1 ] ≤ 1, we get by induction that E[ZT ] ≤ T , and the lemma follows by our choice of α. The next lemma shows that the return achieved by algorithm Exp3.P is close to its upper confidence bounds. Let
Uˆ def = max 1 ≤i≤K
Gˆi + αˆσi
Lemma 6.2. If α ≤ 2
KT , then
GExp3.P ≥
5 γ 3
U^ ˆ − 3
γ
K ln K − 2 α
KT − 2 α^2.
Proof. We proceed as in the analysis of algorithm Exp3. Set η = γ/(3K) and consider any sequence i 1 ,... , iT of actions chosen by Exp3.P. As ˆxi(t) ≤ K/γ, pi(t) ≥ γ/K, and α ≤ 2
KT , we have
ηxˆi(t) + αη pi(t)
KT
Therefore,
Wt+ Wt
∑^ K
i=
wi(t + 1) Wt
∑^ K
i=
wi(t) Wt
exp
ηxˆi(t) +
αη pi(t)
KT
∑^ K
i=
pi(t) − γ/K 1 − γ exp
ηxˆi(t) +
αη pi(t)
KT
∑^ K
i=
pi(t) − γ/K 1 − γ
[
1 + ηxˆi(t) +
αη pi(t)
KT
2 α^2 η^2 pi(t)^2 KT
]
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 63
Algorithm Exp3.P. 1 Parameters: Real 0 < δ < 1. Initialization: For each r ≥ 1 let Tr = 2r^ , δr = (^) (r+1)(δr+2) , and set
(24) r∗^ = min{r ∈ N : δr ≥ KTr e−KTr^ }.
Repeat for r = r∗, r∗^ + 1,... Run Exp3.P for Tr trials choosing α and γ as in Theorem 6.3 with T = Tr and δ = δr.
Fig. 4. Pseudocode of algorithm Exp3.P. 1 (see Theorem 6.4).
implies α ≤ 2
KT for our choice of α. So we can apply Lemmas 6.1 and 6.2. By Lemma 6.2 we have
GExp3.P ≥
5 γ 3
U^ ˆ − 3
γ
K ln K − 2 α
KT − 2 α^2.
By Lemma 6.1 we have Uˆ ≥ Gmax with probability at least 1 − δ. Collecting terms and using Gmax ≤ T gives the theorem. It is not difficult to obtain an algorithm that does not need the time horizon T as input parameter and whose regret is only slightly worse than that proven for the algorithm Exp3.P in Theorem 6.3. This new algorithm, called Exp3.P. 1 and shown in Figure 4, simply restarts Exp3.P doubling its guess for T each time. The only crucial issue is the choice of the confidence parameter δ and of the minimum length of the runs to ensure that Lemma 6.1 holds for all the runs of Exp3.P. Theorem 6.4. Let r∗^ be as in (24). Let K ≥ 2 , δ ∈ (0, 1), and T ≥ 2 r
∗
. Let cT = 2 ln(2 + log 2 T ). Then
Gmax − GExp3.P. 1 ≤
2 KT
ln
KT
δ
ln
KT
δ
holds with probability at least 1 − δ. Proof. Choose the time horizon T arbitrarily and call epoch the sequence of trials between two successive restarts of algorithm Exp3.P. For each r > r∗, where r∗^ is defined in (24), let
Gi(r) def =
(^2) ∑r+
t=2r^ +
xi(t) , Gˆi(r) def =
(^2) ∑r+
t=2r^ +
ˆxi(t) , σˆi(r) def =
KTr +
(^2) ∑r+
t=2r^ +
pi(t)
KTr
and similarly define the quantities Gi(r∗) and Gˆi(r∗) with sums that go from t = 1 to t = 2r
∗+ . For each r ≥ r∗, we have δr ≥ KTr e−KTr^. Thus we can find numbers αr such that, by Lemma 6.1,
P
(∃r ≥ r∗)(∃i) : Gˆi(r) + αr σˆi(r) < Gi(r)
∑^ ∞
r=r∗
P
∃i : Gˆi(r) + αr σˆi(r) < Gi(r)
64 AUER, CESA-BIANCHI, FREUND, AND SCHAPIRE
∑^ ∞
r=
δ (r + 1)(r + 2) = δ.
We now apply Theorem 6.3 to each epoch. Since T ≥ 2 r ∗ , there is an ℓ ≥ 1 such that
2 r
∗+ℓ− 1 ≤ T =
r=
2 r
∗+r < 2 r
∗+ℓ .
With probability at least 1−δ over the random draw of Exp3.P. 1 ’s actions i 1 ,... , iT ,
Gmax − GExp3.P. 1
∑^ ℓ−^1
r=
[√
KTr∗+r ln
KTr∗+r δr∗+r
KTr∗+r δr∗+r
]
[√
K ln
KTr∗+ℓ− 1 δr∗+ℓ− 1
r=
Tr∗+r + ℓ ln
KTr∗+ℓ− 1 δr∗+ℓ− 1
]
[√
K ln KTr∗+ℓ− 1 δr∗+ℓ− 1
2 (r
∗+ℓ)/ 2 √ 2 − 1
]
2 KT
ln
KT
δ
ln
KT
δ
where cT = 2 ln(2 + log 2 T ). From the above theorem we get, as a simple corollary, a statement about the almost sure convergence of the return of algorithm Exp3.P. The rate of convergence is almost optimal, as one can see from our lower bound in section 5. Corollary 6.5. For any K ≥ 2 and for any function f : R → R with limT →∞ f (T ) = ∞,
lim T →∞
Gmax − GExp3.P. 1 √ T (ln T )f (T )
holds for any assignment of rewards with probability 1. Proof. Let δ = 1/T 2. Then, by Theorem 6.4, there exists a constant C such that for all T large enough
Gmax − GExp3.P. 1 ≤ C
KT ln T
with probability at least 1 − 1 /T 2. This implies that
P
Gmax − GExp3.P. 1 √ (T ln T )f (T )
> C
K
f (T )
T 2
and the theorem follows from the Borel–Cantelli lemma.
- The regret against the best strategy from a pool. Consider a setting where the player has preliminarily fixed a set of strategies that could be used for choosing actions. These strategies might select different actions at different itera- tions. The strategies can be computations performed by the player or they can be
66 AUER, CESA-BIANCHI, FREUND, AND SCHAPIRE
Algorithm Exp Parameters: Real γ ∈ (0, 1]. Initialization: wi(1) = 1 for i = 1,... , N.
For each t = 1, 2 ,...
- Get advice vectors ξ^1 (t),... , ξN^ (t).
- Set Wt =
∑N
i=1 wi(t) and for^ j^ = 1,... , K^ set
pj (t) = (1 − γ)
∑^ N
i=
wi(t)ξij (t) Wt
γ K
- Draw action it randomly according to the probabilities p 1 (t),... , pK (t).
- Receive reward xit (t) ∈ [0, 1].
- For j = 1,... , K set
ˆxj (t) =
xj (t)/pj (t) if j = it, 0 otherwise.
- For i = 1,... , N set
yˆi(t) = ξi(t) · xˆ(t), wi(t + 1) = wi(t) exp (γ ˆyi(t)/K).
Fig. 5. Pseudocode of algorithm Exp4 for using expert advice.
Proof. We prove this theorem along the lines of the proof of Theorem 3.1. Let qi(t) = wi(t)/Wt. Then
Wt+ Wt
∑^ N
i=
wi(t + 1) Wt
∑^ N
i=
qi(t) exp
( (^) γ K
yˆi(t)
∑^ N
i=
qi(t)
[
γ K
yˆi(t) + (e − 2)
( (^) γ K
yˆi(t)
) 2 ]
( (^) γ K
) ∑N
i=
qi(t)ˆyi(t) + (e − 2)
( (^) γ K
) 2 ∑N
i=
qi(t)ˆyi(t)^2.
Taking logarithms and summing over t we get
ln
WT +
W 1
( (^) γ K
) ∑T
t=
∑^ N
i=
qi(t)ˆyi(t) + (e − 2)
( (^) γ K
) 2 ∑T
t=
∑^ N
i=
qi(t)ˆyi(t)^2.
THE NONSTOCHASTIC MULTIARMED BANDIT PROBLEM 67
Since, for any expert k,
ln
WT +
W 1
≥ ln wk(T + 1) W 1
γ K
∑^ T
t=
y ˆk(t) − ln N,
we get
∑^ T
t=
∑^ N
i=
qi(t)ˆyi(t) ≥
∑^ T
t=
ˆyk(t) − K ln N γ
− (e − 2) γ K
∑^ T
t=
∑^ N
i=
qi(t)ˆyi(t)^2.
Note that
∑^ N
i=
qi(t)ˆyi(t) =
∑^ N
i=
qi(t)
∑^ K
j=
ξij (t)ˆxj (t)
∑^ K
j=
( N
i=
qi(t)ξji (t)
ˆxj (t)
∑^ K
j=
pj (t) − (^) Kγ 1 − γ
x ˆj (t) ≤ xj (t) 1 − γ
Also,
∑^ N
i=
qi(t)ˆyi(t)^2 =
∑^ N
i=
qi(t)(ξiit (t)ˆxit (t))^2
≤ xˆit (t)^2 pit (t) 1 − γ
≤ xˆit (t) 1 − γ
Therefore, for all experts k,
GExp4 =
∑^ T
t=
ˆxit (t) ≥ (1 − γ)
∑^ T
t=
y ˆk(t) −
K ln N γ
− (e − 2)
γ K
∑^ T
t=
∑^ K
j=
ˆxj (t).
We now take expectations of both sides of this inequality. Note that
E[ˆyk(t)] = E
∑^ K
j=
ξkj (t)ˆxj (t)
∑^ K
j=
ξjk (t)xj (t) = yk(t).
Further,
K
E
∑^ T
t=
∑^ K
j=
ˆxj (t)
∑^ T
t=
K
∑^ K
j=
xj (t) ≤ max 1 ≤i≤N
∑T
t=
yi(t) = G˜max
since we have assumed that the uniform expert is included in the family of experts. Combining these facts immediately implies the statement of the theorem.