



ztests
The χ2-distribution
The t-distribution
Summary
The t-distribution
Patrick Breheny
October 13
Patrick Breheny Biostatistical Methods I (BIOS 5710) 1/25














Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
So far we've (thoroughly!) discussed how to carry out hypothesis tests and construct confidence intervals for categorical outcomes: success versus failure, ...
Typology: Exams
1 / 25

This page cannot be seen from the preview
Don't miss anything!
The χ^2 -distributionz^ tests The t-distributionSummary
Patrick Breheny
October 13
The χ^2 -distributionz^ tests The t-distributionSummary
Introduction z tests What’s wrong with z-tests?
So far we’ve (thoroughly!) discussed how to carry out hypothesis tests and construct confidence intervals for categorical outcomes: success versus failure, life versus death This week we’ll turn our attention to continuous outcomes like blood pressure, cholesterol, etc. We’ve seen how continuous data must be summarized and plotted differently, and how continuous probability distributions work very differently from discrete ones It should come as no surprise, then, that there are also big differences in how these data must be analyzed
The χ^2 -distributionz^ tests The t-distributionSummary
Introduction z tests What’s wrong with z-tests?
We’ve already used the central limit theorem to construct confidence intervals and perform hypothesis tests for categorical data The same logic can be applied to continuous data as well, with one wrinkle For categorical data, the parameter we were interested in (p) also determined the standard deviation:
p(1 − p) For continuous data, the mean tells us nothing about the standard deviation
The χ^2 -distributionz^ tests The t-distributionSummary
Introduction z tests What’s wrong with z-tests?
In order to perform any inference using the CLT, we need a standard error We know that SE = SD/
n, so it seems reasonable to estimate the standard error using the sample standard deviation as a stand-in for the population standard deviation This turns out to work decently well for large n, but as we will see, has problems when n is small
The χ^2 -distributionz^ tests The t-distributionSummary
Introduction z tests What’s wrong with z-tests?
In the study, the mean difference in reduction in FVC (placebo − drug) was 137, with standard deviation 223 Performing the z-test of H 0 : μ = 0: #1 SE = 223/
√ 14 = 60
z =
137 − 0 60 = 2. 28
#3 The area outside ± 2. 28 is 2Φ(− 2 .28) = 2(0.011) = 0. 022 This is fairly substantial evidence that the drug helps prevent deterioration in lung function
The χ^2 -distributionz^ tests The t-distributionSummary
Introduction z tests What’s wrong with z-tests?
However, as I mentioned before, these procedures are flawed when n is small This is a completely separate flaw than the issue of “how accurate is the normal approximation?” in using the central limit theorem Indeed, this is a problem even when the sampling distribution is perfectly normal This flaw can be witnessed by repeatedly drawing random samples from the normal distribution, then carrying out this test and recording the type I error rate
The χ^2 -distributionz^ tests The t-distributionSummary
Introduction z tests What’s wrong with z-tests?
The flaw with the z-test is that it is ignoring one of the sources of the variability in the test statistic We’re acting as if we know the standard error, but we’re really just estimating it from the data In doing so, we underestimate the amount of uncertainty we have about the population based on the data
The χ^2 -distributionz^ tests The t-distributionSummary
Before we get into the business of fixing the z-test, we need to discuss a more basic issue: what does the sampling distribution of the variance look like? We have this beautiful central limit theorem describing what the sampling distribution of the mean looks like for any underlying distribution Unfortunately, there is no corresponding theorem for the sample variance
The χ^2 -distributionz^ tests The t-distributionSummary
An important distribution highly related to the normal distribution is the χ^2 -distribution Suppose Z ∼ N(0, 1); then Z^2 is said to follow a χ^21 distribution, with pdf:
f (x) =
2 π
x−^1 /^2 e−x/^2
0 1 2 3 4
x
Density
The χ^2 -distributionz^ tests The t-distributionSummary
An important generalization is to consider sums of squared observations from the normal distribution Suppose Z 1 , Z 2 ,... , Zp ∼ N(0, 1) and are mutually independent; then
∑p i=1 Z
2 i is said to follow a chi-squared distribution with p degrees of freedom, denoted χ^2 p:
f (x) =
Γ(p/2)2p/^2
xp/^2 −^1 e−x/^2
0 5 10 15 20 25 30
x
Density (10 df)
The χ^2 -distributionz^ tests The t-distributionSummary
By working out the joint distribution of X¯ and X 2 − X, X¯ 3 − X,... , X¯ n − X¯, we also arrive at the useful conclusion that the sampling distributions of X¯ and S^2 are independent In other words, for normally distributed variables, the mean and variance have no relationship whatsoever This is obviously not true for other distributions – for example, we saw that the binomial distribution has Var(X) = nE(X)(1 − E(X))
The χ^2 -distributionz^ tests The t-distributionSummary
Finally, it is worth mentioning that when a random variable follows a normal distribution, the distribution of its sample mean is exactly normal (i.e., the central limit theorem is an exact result, not an approximation) More formally, suppose X 1 , X 2 ,... , Xn ∼ N(μ, σ^2 ) are mutually independent; then
√ n
X¯ − μ σ
The χ^2 -distributionz^ tests The t-distributionSummary
The problem of “What is the resulting distribution when you divide one random variable by another?” was studied by a statistician named W. S. Gosset, who showed the following Suppose that Z ∼ N(0, 1), X^2 ∼ χ^2 n, and that Z and X^2 are independent; then
Z √ X^2 /n
∼ tn,
the t-distribution with n degrees of freedom
The χ^2 -distributionz^ tests The t-distributionSummary
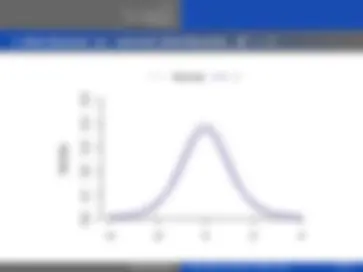
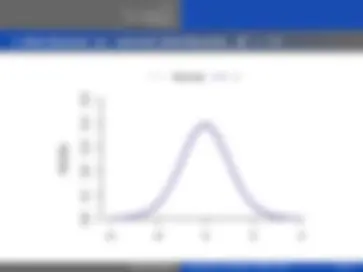
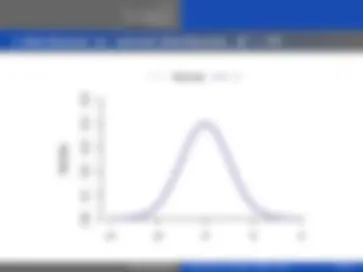
−4 −2 0 2 4
Density
Normal t