



Tries and String Matching
















































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Fundamental data structures such as red/black trees, B-trees, RMQ, etc. and amortized analysis. It also covers string processing, which is used in computational biology, NLP, and computer security. the concept of tries, formally defining it and discussing how to insert and remove from it. It also covers space concerns and the naive solution for string searching. The document then goes on to discuss multi-string searching and the algorithm for it.
Typology: Lecture notes
1 / 65

This page cannot be seen from the preview
Don't miss anything!
●
●
●
●
●
●
●
●
●
●
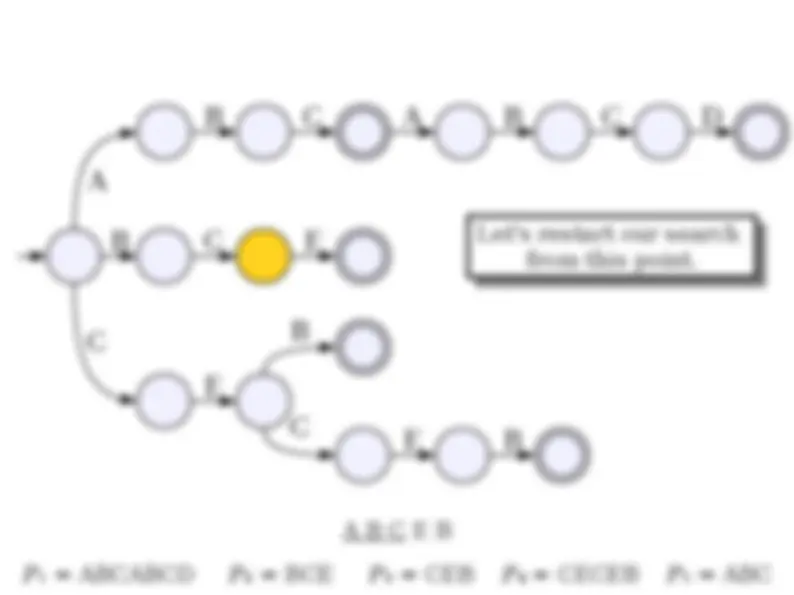
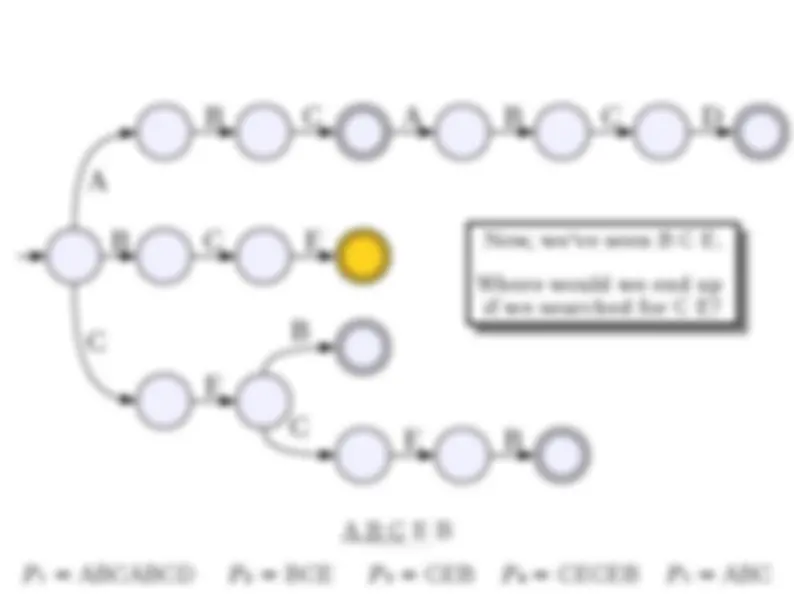
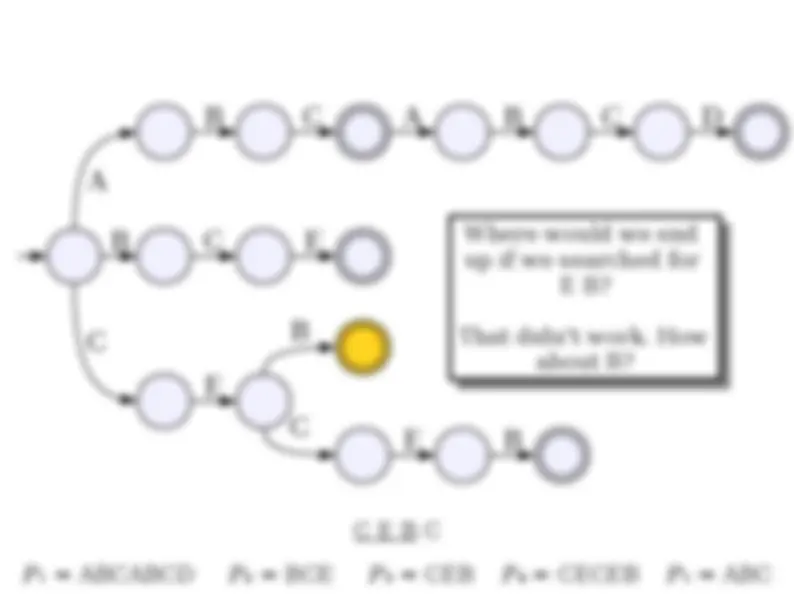
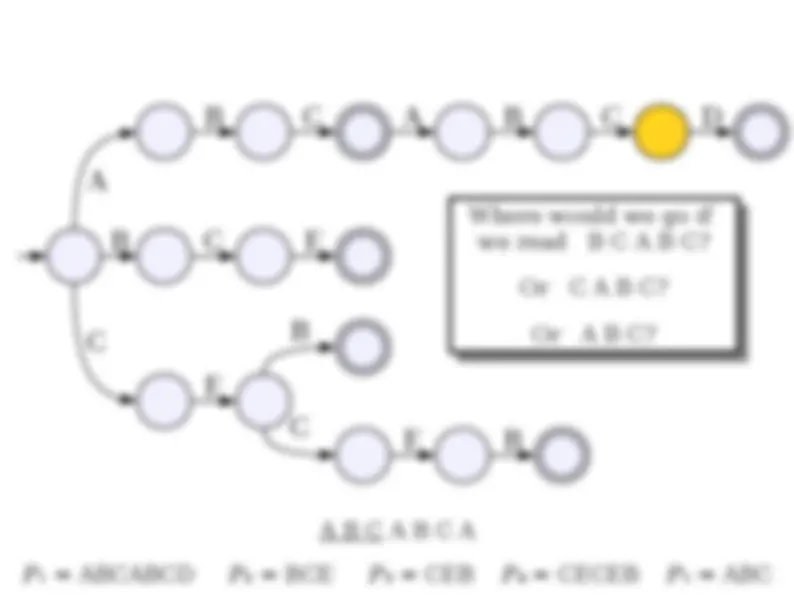
● Suppose we want to store a set of elements supporting the following operations: ● Insertion of new elements. ● (^) Deletion of old elements. ● Membership queries. ● (^) Successor queries. ● (^) Predecessor queries. ● Min/max queries. ● Can use a standard red/black tree or splay tree to get (worst-case or expected) O(log n ) implementations of each.
B D O U T G E A I O A E R D N D T A A I D I K T A T N T E K B C A D
●
●
●
●
●
●
●
●
●
B D O U T G E A I O A E R D N D T A A I D I K T A T N T E K B C A D
●
●
●
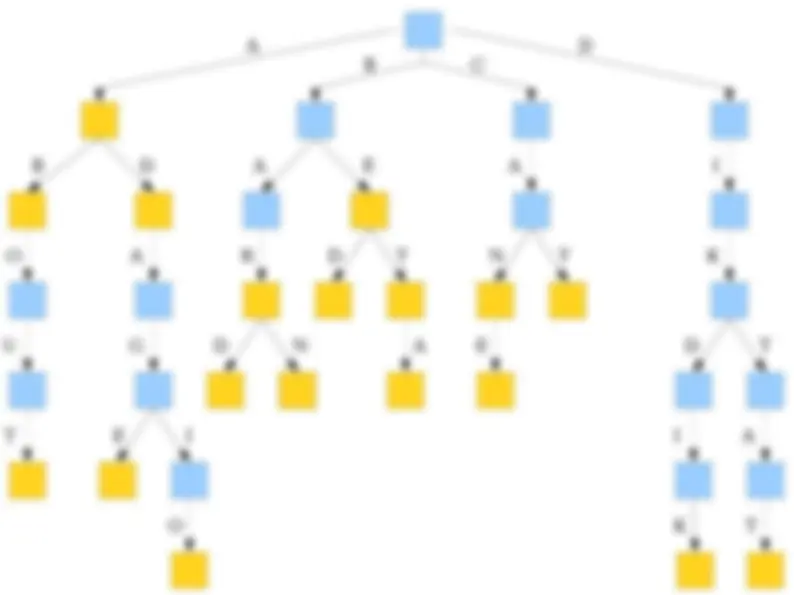
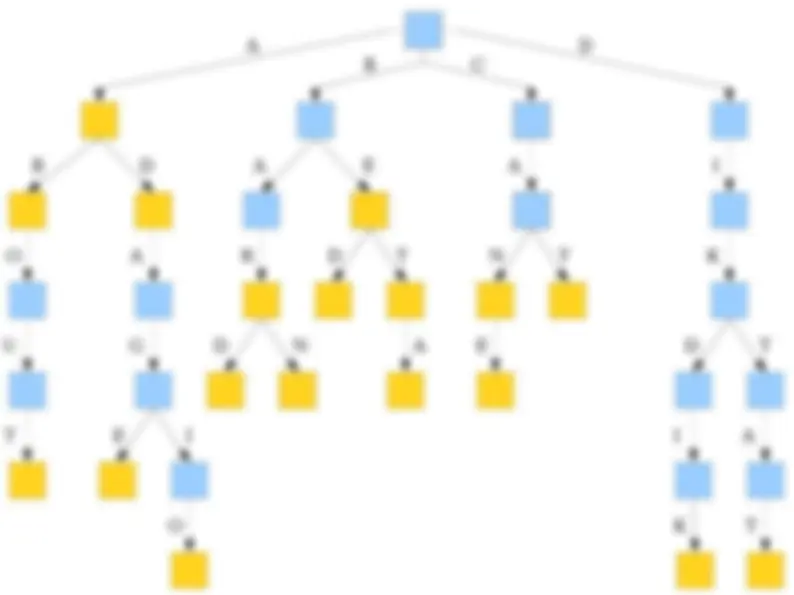
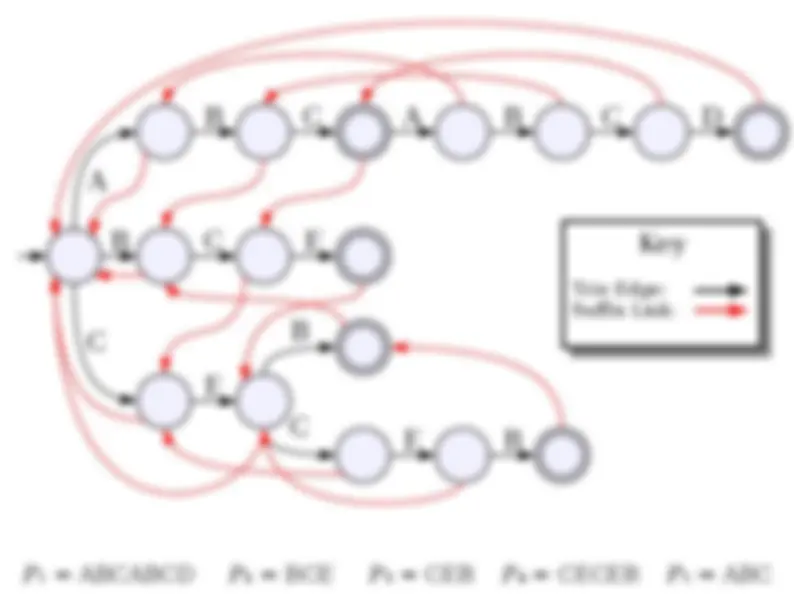
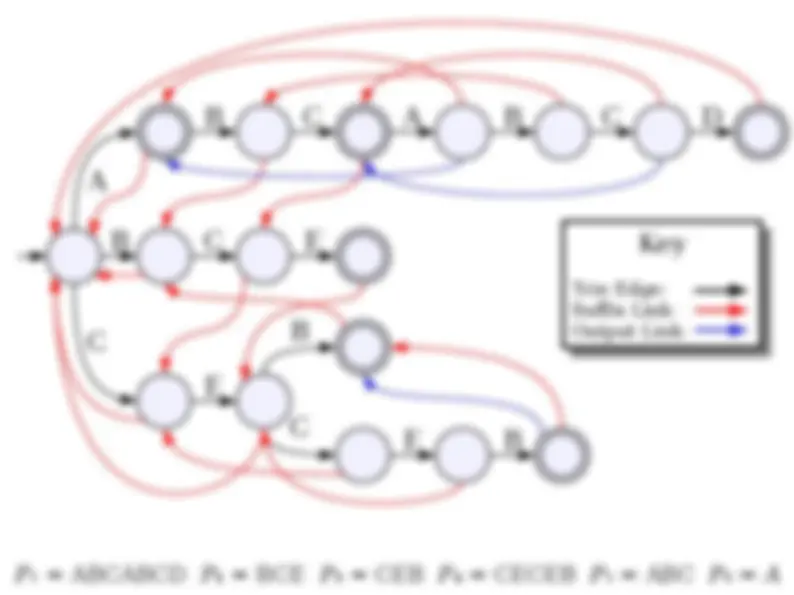
● Although time-efficient, tries can be extremely space-inefficient. ● A trie with N nodes will need space Θ( N · |Σ|) due to the pointers in each node. ● There are many ways of addressing this: ● Change the data structure for holding the pointers (as you'll see in the problem set). ● Eliminate unnecessary trie nodes (we'll see this next time).
●
●
●
●
●
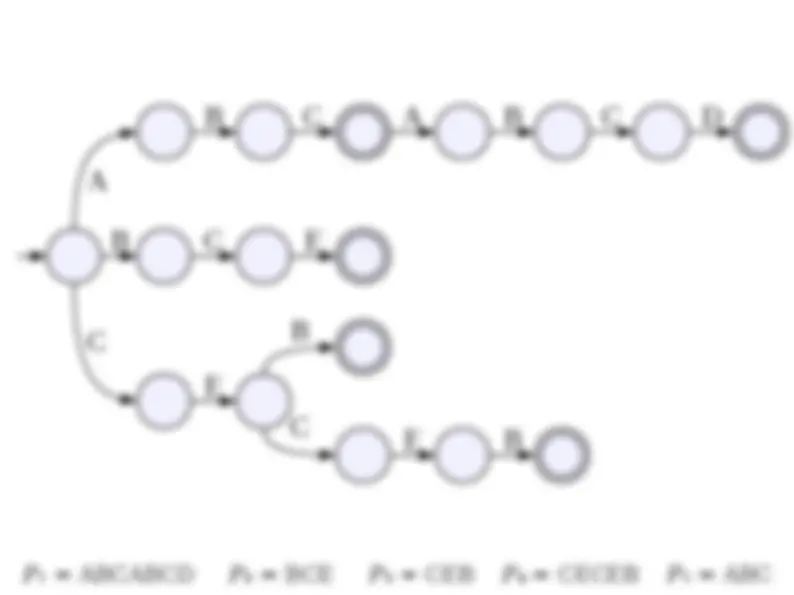
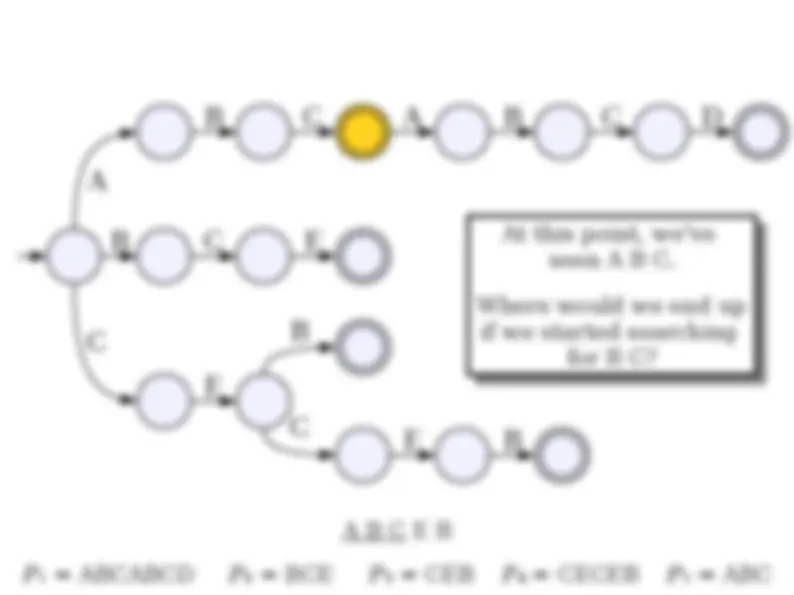
● Consider the following naïve solution: for every possible starting position for P in T , check whether the | P | characters starting at that point exactly match P. ● Work per check: O(| P |) ● Number of starting locations: O(| T |) ● Total runtime: O(| P| · | T |). ● Is this a tight bound?