



Compiler
Construction
Lecture 2












Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of the two-pass compiler architecture, which is a common approach used in compiler design. The two-pass compiler consists of a front-end and a back-end, where the front-end maps the legal source code into an intermediate representation (ir), and the back-end then maps the ir into the target machine code. The key modules of the front-end, including the scanner and the parser, and how they work together to recognize legal and illegal programs, report errors, and produce the ir. It also discusses the complexity of the front-end and back-end, with the front-end being o(n) or o(n log n) and the back-end being np-complete (npc). The context-free grammars used to specify the syntax of the programming language and how the parser uses these grammars to build the parse tree or syntax tree. Overall, this document provides a comprehensive introduction to the two-pass compiler architecture and the key components involved in the compilation process.
Typology: Cheat Sheet
1 / 20

This page cannot be seen from the preview
Don't miss anything!
Front End Back End source code IR (^) machine code errors
Modules
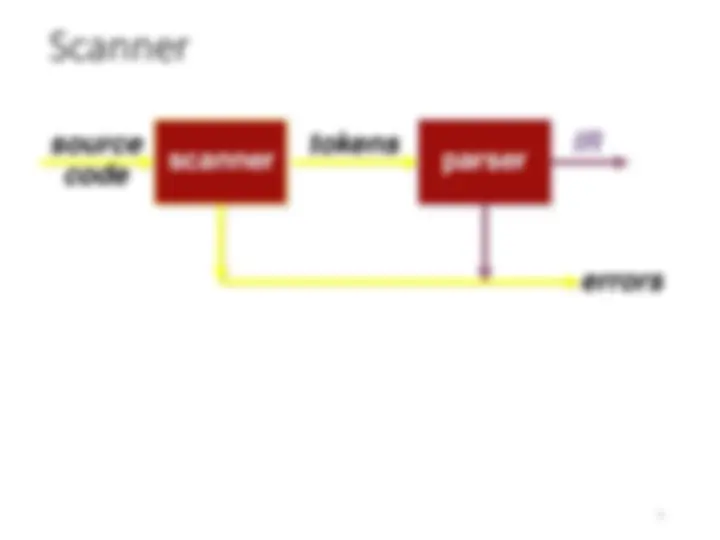
scanner parser source code tokens IR errors
Production Result goal 1 expr 2 expr op term 5 expr op y 7 expr – y 2 expr op term – y 4 expr op 2 – y 6 expr + 2 – y 3 term + 2 – y 5 x + 2^ –^ y^