Download Variable Selection and Model Building - Applied Regression Analysis - Lecture Notes and more Study notes Mathematical Statistics in PDF only on Docsity!
Chapter 9: Variable Selection and Model Building
In this chapter, we will talk about:
- Variable selection and model building problem,
- Several criteria for the evaluation of subset regression models,
- All possible regressions procedure,
- Backward Elimination Procedure
- Forward selection procedure,
- Stepwise regression procedure.
In most practical problems, the analyst has a rather large pool of possible candidate regressors, of which only a few are likely to be important. Finding an appropriate subset of regressors for the model is often called the variable selection problem.
Building a regression model that includes only a subset of the available regressors involves two conflicting objectives:
(a) We would like the model to include as many regressors as possible so that information content in these factors can influence the predicted value of y.
(b) We want the model to include as few regressors as possible because the variance of the prediction y
increases as the number of regressors increases.
By deleting variables from the model, we may improve the precision of the parameter estimates of the retained variables even though some of the deleted variables are not negligible. This is also true for the variance of a predicted response.
Deleting variables potentially introduces bias into the estimates of the coefficient of retained variables and the response. Over-fitting a model (including variables in the model with truly zero regression coefficients in the population) will not introduce bias when population regression coefficient estimated, if the usual regression assumptions are met. We must, however, to ensure that over-fitting does not introduce harmful collinearity.
The basic steps for variable selection are as follows:
(a) Specify the maximum model to be considered.
(b) Specify a criterion for selection a model.
(c) Specify a strategy for selecting variables.
(d) Conduct the specified analysis.
(e) Evaluate the Validity of the model chosen. (Validity of a model is discussed in Chapter 10.)
(b) Coefficient of Determination: A measure of the adequacy of a regression model that has been widely used is the coefficient of determination (^) R. 2
Let (^) R (^) p denote the coefficient of determination for a 2 p -term subset model. Then
SS
SS SS
SS R T
s T
R p
p ( p ) 1 2 (^ ) Re = = −
R (^) p
2 increases as p increases and is maximum when p = k + 1. Therefore, the analyst
uses this criterion by adding regressors to the model up to the point where an additional
variable only provides a small increase in (^) R (^) p.
2
Let (^) R (^ Rk )(^ d , n , k )
2 1
2 0 =^1 −^1 − + 1 + α where^1
,, 1 , , =^ − −
−− n k
k (^) F d
knk nk
α α and^ is the value of
for the full model. Any subset of regressor variables producing an greater than is called -adequate (
R k
2
R
2 R
2
R
2 0 R
2
α ) subset (That is, its is not significantly different
from ).
R
2
R (^) k
2
Example 1: Suppose that we want to investigate how weight (WGT) varies with height (HGT) and age (AGE) for children with a particular kind of nutritional deficiency. The dependent variable here is Y = WGT , and two basic independent variables are
X (^) 1 =^ HGT and^ X (^) 2 = AGE
The WGT, HGT, and AGE for a random sample consists of 12 children who attend a certain clinic are given in the example 3 of chapter 3..
0. 05 , 13 , 4 =^ = =
F d
R^20 =^1 −^ (^1 −^0.^7803 )(^1 +^1.^5626 )^ =^0.^4370
(c) Residual Mean Square: A third criterion to consider in selecting the best model is the estimated error variance for the ( p − 1 )variable model-namely,
n p
p MS s p^ SS s −
Re(^ ) Re
Because (^) SS Re s ( p ) always decreases as p increases, MS Re s ( p ) initially decreases,
then stabilizes, and eventually may increases. Advocates of the (^) MS (^) Re s ( p ) criterion will
plot (^) MS (^) Re s ( p )versus p and base the choice of p on the following:
1. The minimum (^) MS (^) Re s ( p ) 2. The value of (^) p such that MS (^) Re s ( p ) is approximately equal to (^) MS (^) Re s for the full model, or 3. A value of p near the point where the smallest (^) MS (^) Re s ( p )turns upward.
Note that the subset regression model that minimizes (^) MS (^) Re s ( p )will also
maximize (^) R (^) Adjp. 2 ,
(d) Mallow's (^) CP Statistic: Another candidate for a selection criterion involving is
SS (^) Re s ( p )Mallow's CP :
n p k
p
MS
SS C s
s p (^) ( )^2
Re
= Re^ − +
CP criterion helps us to decide how many variables to put in the best model, since it
achieves a value of approximately p if MS (^) Re s ( p )is roughly equal to (^) MS (^) Re s ( k ).
(e) PRESS: One can select the subset regression model based on a small value of PRESS. While PRESS has intuitive appeal, particularly for the prediction problem, it is not a simple function of the residual sum of squares, and developing an algorithm for variable selection based on this criterion is not straightforward. This statistics is, however, potentially useful, for discriminating between alternative models.
SAS Output:
Hald Cement Data Y on X1,X2,X3 and X The REG Procedure Number of Observations Read 13 Number of Observations Used 13
Number in Adjusted Model R-Square R-Square C(p) MSE Variables in Model 1 0.6745 0.6450 138.7308 80.35154 x 1 0.6663 0.6359 142.4864 82.39421 x 1 0.5339 0.4916 202.5488 115.06243 x 1 0.2859 0.2210 315.1543 176.30913 x
2 0.9787 0.9744 2.6782 5.79045 x1 x 2 0.9725 0.9670 5.4959 7.47621 x1 x 2 0.9353 0.9223 22.3731 17.57380 x3 x 2 0.8470 0.8164 62.4377 41.54427 x2 x 2 0.6801 0.6161 138.2259 86.88801 x2 x 2 0.5482 0.4578 198.0947 122.70721 x1 x
3 0.9823 0.9764 3.0182 5.33030 x1 x2 x 3 0.9823 0.9764 3.0413 5.34562 x1 x2 x 3 0.9813 0.9750 3.4968 5.64846 x1 x3 x 3 0.9728 0.9638 7.3375 8.20162 x2 x3 x
4 0.9824 0.9736 5.0000 5.98295 x1 x2 x3 x
If we assume that the intercept term β 0 is included in all equations, then if there are
candidate regressors, there are 2 total equations to be estimated and examined.
Therefore, the number of equations to be examined increases rapidly as the number of candidate regressors increases
k k
(b) Backward Elimination Procedure: We begin with a model that includes all candidate regressors. Then the partial -statistic is computed for each regressors as if it were the last variable to enter the model. The smallest of these partial -statistics is compared with a pre-selected value,
k F
F (^) FOUT , for example, and if the smallest partial F value is less than FOUT , that regressor is removed from the model. Now a regression model with k − 1 regressors is fit, the partial -statistics for this new model calculated, and the procedure repeated. The backward elimination algorithm terminates when the smallest partial value is not less than the pre-selected cutoff value
F
F
FOUT.
Example 1 (Cont.):
Backward Elimination: Step 0 All Variables Entered: R-Square = 0.7803 and C(p) = 4.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 3 693.06046 231.02015 9.47 0.
Error 8 195.18954 24.
Corrected Total 11 888.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 3.43843 33.61082 0.25535 0.01 0.
HGT 0.72369 0.27696 166.58195 6.83 0.
AGE 2.77687 7.42728 3.41051 0.14 0.
AGE2 -0.04171 0.42241 0.23786 0.01 0.
(c) Forward Selection Procedure: The procedure begins with the assumption that there are no regressors in the model other than the intercept. An effort is made to find an optimal subset by inserting into model one at a time. At each step the regressor having the highest partial correlation with (or equivalently the largest -statistic given the other regressors already in the model) is added to the model if its partial -statistic exceeds the pre-selected entry level
y F F (^) F (^) IN.
Example (Cont.):
Variable R
(^2) F-value P-value
HGT 0.6630 19.67 0. WGT 0.5926 14.55 0. AGE2 0.5876 14.25 0.
SAS Outpu Forward Selection: Step 1 Variable HGT Entered: R-Square = 0.6630 and C(p) = 4.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 1 588.92252 588.92252 19.67 0.
Error 10 299.32748 29.
Corrected Total 11 888.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 6.18985 12.84875 6.94681 0.23 0.
HGT 1.07223 0.24173 588.92252 19.67 0.
Forward Selection: Step 2 Variable AGE Entered: R-Square = 0.7800 and C(p) = 2.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 2 692.82261 346.41130 15.95 0.
Error 9 195.42739 21.
Corrected Total 11 888.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 6.55305 10.94483 7.78416 0.36 0.
HGT 0.72204 0.26081 166.42975 7.66 0.
AGE 2.05013 0.93723 103.90008 4.78 0.
No other variable met the 0.1000 significance level for entry into the model.
Summary of Forward Selection
Step Variable Entered
Number Vars In
Partial R-Square
Model R-Square
C(p) F Value Pr > F
1 HGT 1 0.6630 0.6630 4.2682 19.67 0.
2 AGE 2 0.1170 0.7800 2.0097 4.78 0.
Backward Elimination: Step 1 Variable x3 Removed: R-Square = 0.9823 and C(p) = 3.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 3 2667.79035 889.26345 166.83 <.
Error 9 47.97273 5.
Corrected Total 12 2715.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 71.64831 14.14239 136.81003 25.67 0.
x1 1.45194 0.11700 820.90740 154.01 <.
x2 0.41611 0.18561 26.78938 5.03 0.
x4 -0.23654^ 0.17329^ 9.93175^ 1.86^ 0.
Backward Elimination: Step 2 Variable x4 Removed: R-Square = 0.9787 and C(p) = 2.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 2 2657.85859 1328.92930 229.50 <.
Error 10 57.90448 5.
Corrected Total 12 2715.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 52.57735 2.28617 3062.60416 528.91 <.
X1 1.46831 0.12130 848.43186 146.52 <.
X2 0.66225 0.04585 1207.78227 208.58 <.
All variables left in the model are significant at the 0.1000 level.
Summary of Backward Elimination
Step Variable Removed
Number Vars In
Partial R- Square
Model R- Square
C(p) F Value
Pr > F
1 x3 3 0.0000 0.9823 3.0182 0.02 0.
2 x4 2 0.0037 0.9787 2.6782 1.86 0.
Forward Selection: Step 3 Variable x2 Entered: R-Square = 0.9823 and C(p) = 3.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 3 2667.79035 889.26345 166.83 <.
Error 9 47.97273 5.
Corrected Total 12 2715.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 71.64831 14.14239 136.81003 25.67 0.
x1 1.45194 0.11700 820.90740 154.01 <.
x2 0.41611 0.18561 26.78938 5.03 0.
x4 -0.23654 0.17329 9.93175 1.86 0.
No other variable met the 0.1000 significance level for entry into the model.
Summary of Forward Selection
Step Variable Entered
Number Vars In
Partial R- Square
Model R- Square
C(p) F Value
Pr > F
1 x4 1 0.6745 0.6745 138.731 22.80 0.
2 x1 2 0.2979 0.9725 5.4959 108.22 <.
3 x2 3 0.0099 0.9823 3.0182 5.03 0.
Stepwise Selection: Step 1 Variable x4 Entered: R-Square = 0.6745 and C(p) = 138.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 1 1831.89616 1831.89616 22.80 0.
Error 11 883.86692 80.
Corrected Total 12 2715.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 117.56793 5.26221 40108 499.16 <.
x4 -0.73816 0.15460 1831.89616 22.80 0. Stepwise Selection: Step 2 Variable x1 Entered: R-Square = 0.9725 and C(p) = 5.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 2 2641.00096 1320.50048 176.63 <.
Error 10 74.76211^ 7.
Corrected Total 12 2715.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 103.09738 2.12398 17615 2356.10 <.
x1 1.43996 0.13842 809.10480 108.22 <.
x4 -0.61395 0.04864 1190.92464 159.30 <.
Stepwise Selection: Step 4 Variable x4 Removed: R-Square = 0.9787 and C(p) = 2.
Analysis of Variance
Source DF Sum of Squares
Mean Square
F Value Pr > F
Model 2 2657.85859 1328.92930 229.50 <.
Error 10 57.90448 5.
Corrected Total 12 2715.
Variable Parameter Estimate
Standard Error
Type II SS F Value Pr > F
Intercept 52.57735 2.28617 3062.60416 528.91 <.
x1 1.46831 0.12130 848.43186 146.52 <.
x2 0.66225 0.04585 1207.78227 208.58 <. All variables left in the model are significant at the 0.1000 level. No other variable met the 0.1000 significance level for entry into the model.
Summary of Stepwise Selection
Step Variable Entered
Variable Removed
Number Vars In
Partial R- Square
Model R- Square
C(p) F Value
Pr > F
1 x4 1 0.6745 0.6745 138.731 22.80 0.
2 x1 2 0.2979 0.9725 5.4959 108.22 <.
3 x2 3 0.0099 0.9823 3.0182 5.03 0.
4 x4 2 0.0037 0.9787 2.6782 1.86 0.
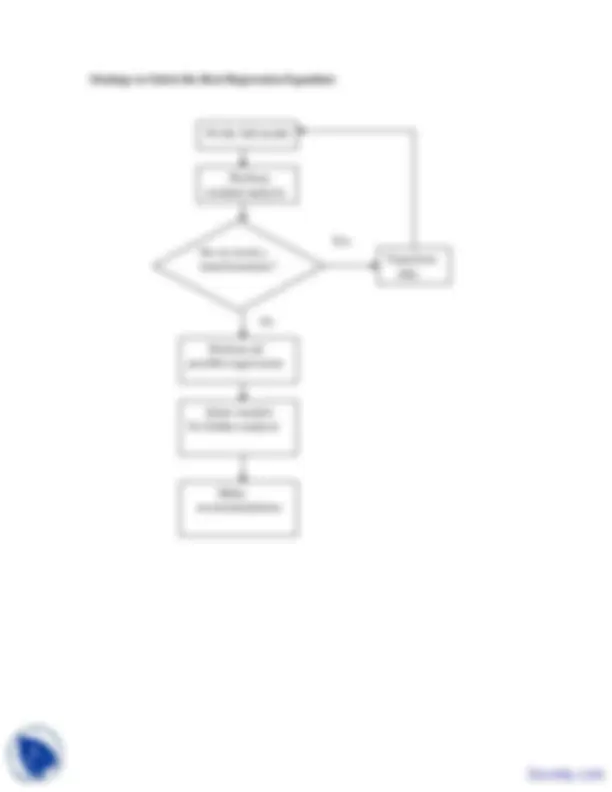
Strategy to Select the Best Regression Equation:
Fit the full model
Perform residual analysis
Transform data
Do we need a transformation?
Yes
No
Select models for further analysis
Perform all possible regressions
Make recommendations