



FEM – p.1/13







Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
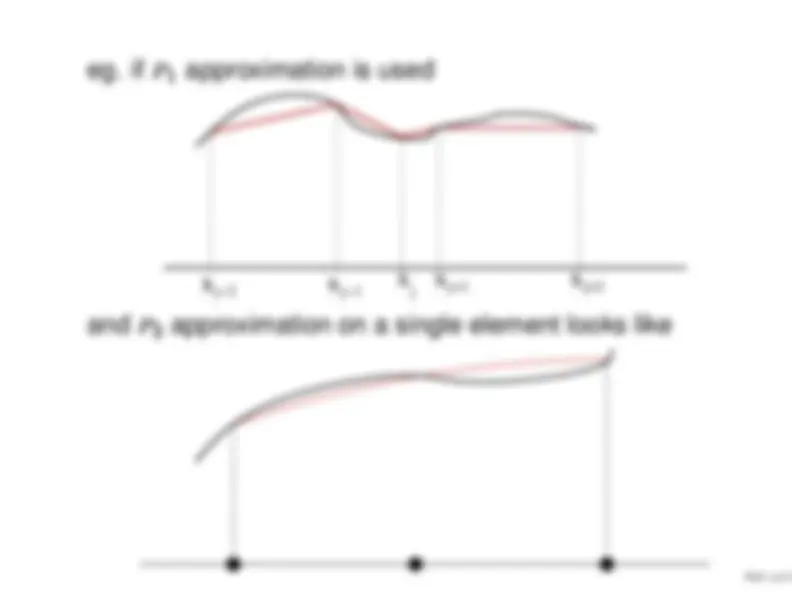
Prior error estimations
Typology: Study notes
1 / 13

This page cannot be seen from the preview
Don't miss anything!
u h ‖∇
u
u h
u
v h
v h
E
u
v h
v h
E
v h
u
u
1 E
a, b
1
0
u
1 E
v h
E
v h
j
u
j
for all
j
x 0 < x 1 < x 2 <... < x n
b ‖∇
u
u h
2
u
v h
2
n ∑ j =
x j x j − 1
u ′
x
v ′ h
x
2 d x
e I
u
v h
u
v h FEM – p.4/
P 1
j−
j^ j+
j+
j−
P 2
h j
x j
x j − 1
s
x j − 1 , x j
e ′ I
s
s ξ e ′′ I
t ) d t
e ′ I
s
2
s ξ
e ′′ I
t ) d t
2 ≤
s ξ
2 d t
s ξ
e ′′ I
t
2 d t
h j
x j x j − 1
u ′′
t
2 d t
e ′′ I
u ′′
v ′′ h
u ′′
v h
x j − 1 , x j
e ′ I
s
2
h j
x j x j − 1
u ′′
t
2 d t
x j x j − 1
e ′ I
s
2 d s
x j x j − 1 h j
x j x j − 1
u ′′
t
2 d t d s = h 2 j
x j x j − 1
u ′′
t
2 d t
j
,... , n
h = max j
h j
b a
e ′ I
s
2 d s
h 2
b a
u ′′
t
2 d t
e ′ I
h
u ′′
h
f
e I
h
e ′ I
v h
u
P 1
e I
h
e ′ I
h 2
u ′′
h 2
f
2
a, b
P 2
a, b
e I
u
v h
v h
u
x j
1 2
x j
x j − 1
u ′′′
x j − 1 , x j
ξ
x j − 1 , x j
e ′′ I
ξ
b a
e ′′ I
s
2 d s
h 2
b a
u ′′′
t
2 d t
b a
e ′ I
s
2 d s
h 2
b a
e ′′ I
s
2 d s ≤ h 4
b a
u ′′′
t
2 d t