



Machine Learning with WEKA
WEKA Explorer Tutorial
for WEKA Version 3.4.3
Svetlana S. Aksenova
School of Engineering and Computer Science
Department of Computer Science
California State University, Sacramento
California, 95819
2004


























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
jkjkjuiu - jkjkjuiu
Typology: Exercises
1 / 45

This page cannot be seen from the preview
Don't miss anything!
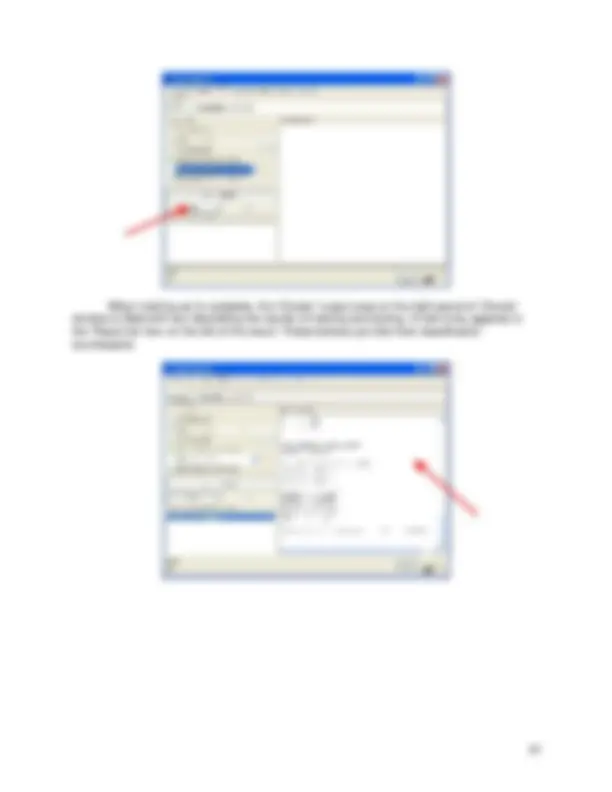
For the exercises in this tutorial you will use ‘Explorer’. Click on ‘Explorer’ button in the ‘WEKA GUI Chooser’ window.
‘WEKA Explorer’ window appears on a screen.
At the very top of the window, just below the title bar there is a row of tabs. Only the first tab, ‘Preprocess’, is active at the moment because there is no dataset open. The first three
buttons at the top of the preprocess section enable you to load data into WEKA. Data can be imported from a file in various formats: ARFF, CSV, C4.5, binary, it can also be read from a URL or from an SQL database (using JDBC) [4]. The easiest and the most common way of getting the data into WEKA is to store it as Attribute-Relation File Format (ARFF) file. You’ve already been given “weather.arff” file for this exercise; therefore, you can skip section 3.1 that will guide you through the file conversion.
We assume that all your data stored in a Microsoft Excel spreadsheet “weather.xls”.
WEKA expects the data file to be in Attribute-Relation File Format (ARFF) file. Before you apply the algorithm to your data, you need to convert your data into comma-separated file into ARFF format (into the file with .arff extension) [1]. To save you data in comma-separated format, select the ‘Save As…’ menu item from Excel ‘File’ pull-down menu. In the ensuing dialog box select ‘CSV (Comma Delimited) ’ from the file type pop-up menu, enter a name of the file, and click ‘Save ’ button. Ignore all messages that appear by clicking ‘OK’. Open this file with Microsoft Word. Your screen will look like the screen below.
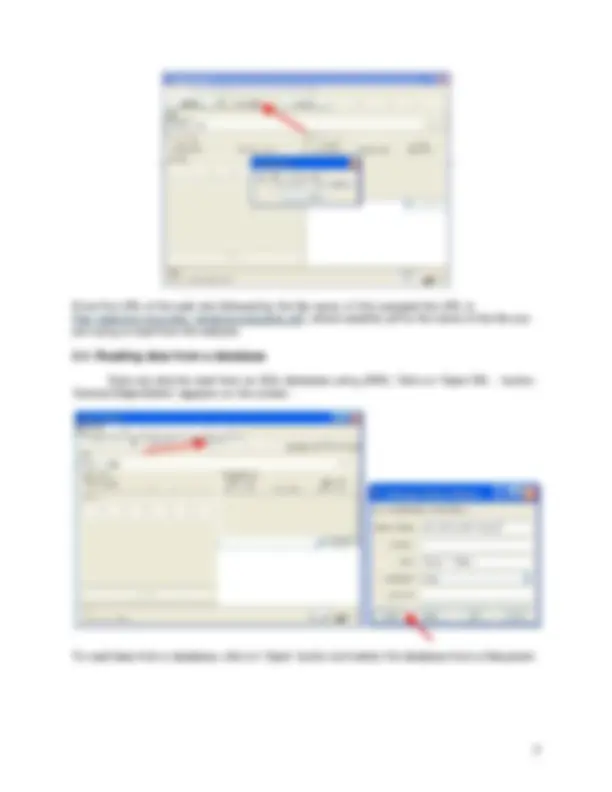
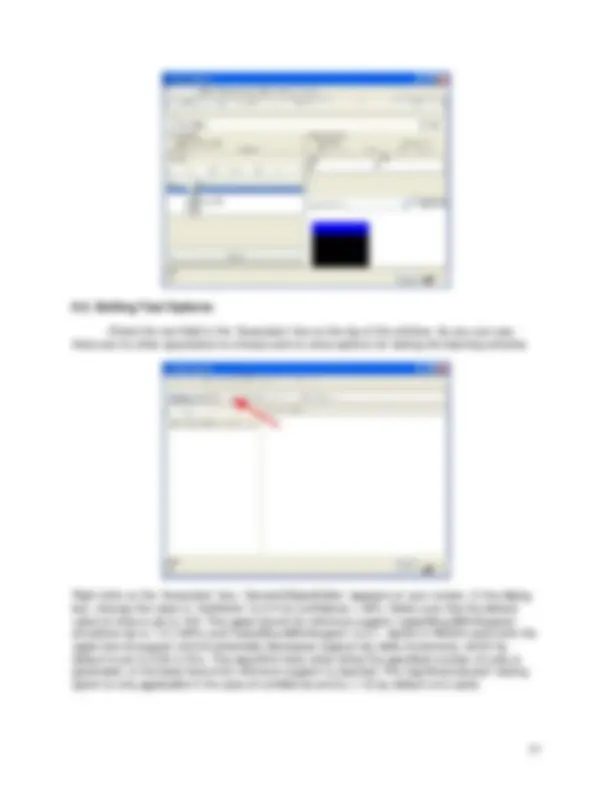
It brings up a dialog box allowing you to browse for the data file on the local file system, choose “weather.arff” file.
Some databases have the ability to save data in CSV format. In this case, you can select CSV file from the local filesystem. If you would like to convert this file into ARFF format, you can click on ‘Save’ button. WEKA automatically creates ARFF file from your CSV file.
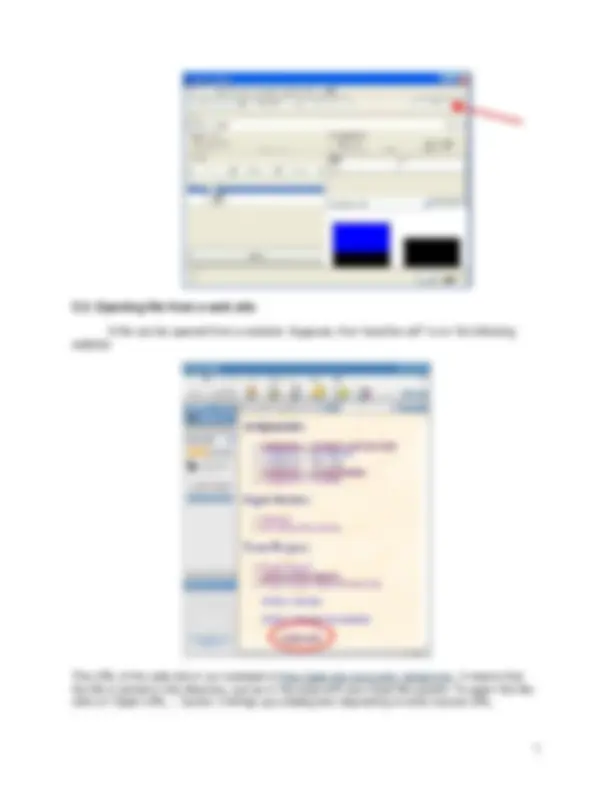
A file can be opened from a website. Suppose, that “weather.arff” is on the following website:
The URL of the web site in our example is http://gaia.ecs.csus.edu/~aksenovs/. It means that the file is stored in this directory, just as in the case with your local file system. To open this file, click on ‘Open URL…’ button, it brings up a dialog box requesting to enter source URL.
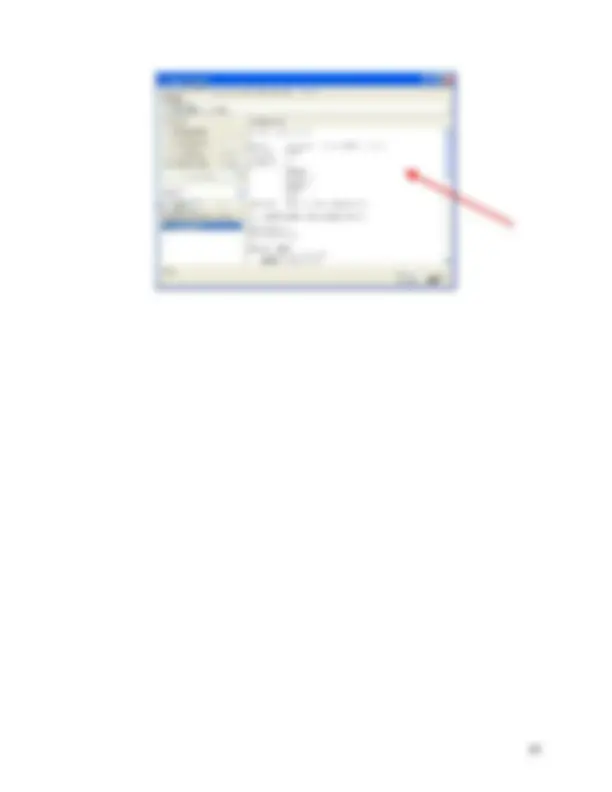
At the bottom of the window there is ‘Status’ box. The ‘Status’ box displays messages that keep you informed about what is going on. For example, when you first opened the ‘Explorer’, the message says, “Welcome to the Weka Explorer”. When you loading “weather.arff” file, the ‘Status’ box displays the message “Reading from file…”. Once the file is loaded, the message in the ‘Status’ box changes to say “OK”. Right-click anywhere in ‘Status box’, it brings up a menu with two options:
To the right of ‘Status box’ there is a ‘Log’ button that opens up the log. The log records every action in WEKA and keeps a record of what has happened. Each line of text in the log contains time of entry. For example, if the file you tried to open is not loaded, the log will have record of the problem that occurred during opening. To the right of the ‘Log’ button there is an image of a bird. The bird is WEKA status icon. The number next to ‘X’ symbol indicates a number of concurrently running processes. When you loading a file, the bird sits down that means that there are no processes running. The number of processes besides symbol ‘X’ is zero that means that the system is idle. Later, in classification problem, when generating result look at the bird, it gets up and start moving that indicates that a process started. The number next to ‘X’ becomes 1 that means that there is one process running, in this case calculation.
If the bird is standing and not moving for a long time, it means that something has gone wrong. In this case you should restart WEKA Explorer.
Loading data Lets load the data and look what is happening in the ‘Preprocess’ window.
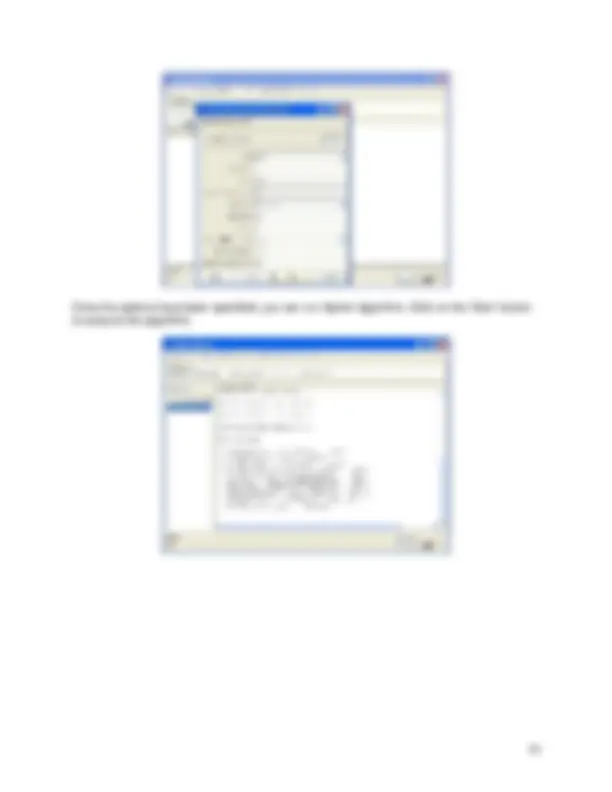
The most common and easiest way of loading data into WEKA is from ARFF file, using ‘Open file…’ button (section 3.2). Click on ‘Open file…’ button and choose “weather.arff” file from your local filesystem. Note, the data can be loaded from CSV file as well because some databases have the ability to convert data only into CSV format.
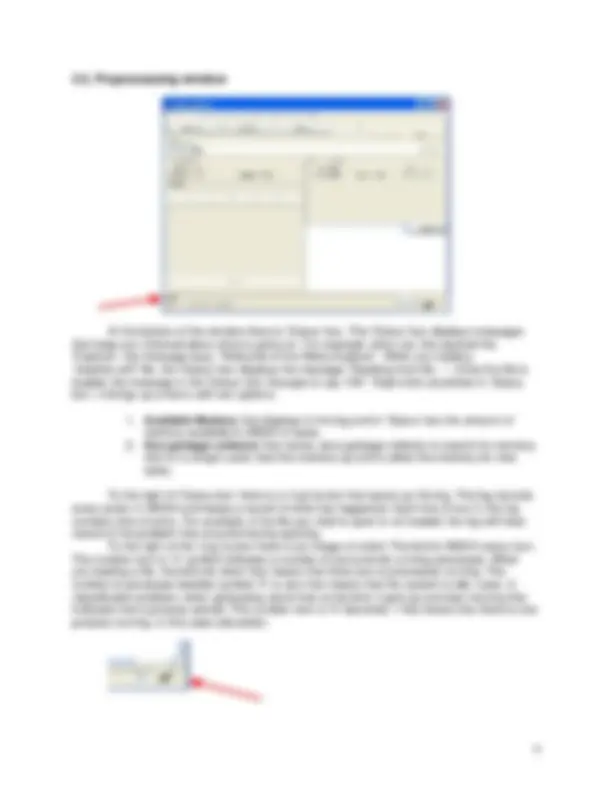
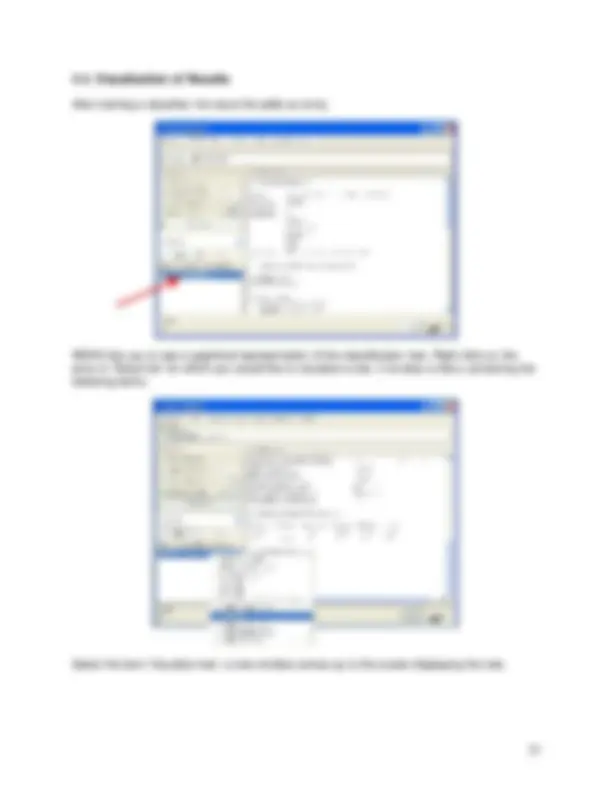
Once the data is loaded, WEKA recognizes attributes that are shown in the ‘Attribute’ window. Left panel of ‘Preprocess’ window shows the list of recognized attributes:
No. is a number that identifies the order of the attribute as they are in data file, Selection tick boxes allow you to select the attributes for working relation, Name is a name of an attribute as it was declared in the data file.
The ‘Current relation’ box above ‘Attribute’ box displays the base relation (table) name and the current working relation (which are initially the same) - “weather”, the number of instances - 14 and the number of attributes - 5.
During the scan of the data, WEKA computes some basic statistics on each attribute. The following statistics are shown in ‘Selected attribute’ box on the right panel of ‘Preprocess’ window:
Name is the name of an attribute, Type is most commonly Nominal or Numeric, and Missing is the number (percentage) of instances in the data for which this attribute is unspecified, Distinct is the number of different values that the data contains for this attribute, and Unique is the number (percentage) of instances in the data having a value for this attribute that no other instances have.
Temperature is a numeric value; therefore, you can see min, max, means, and standard deviation in ‘Selected Attribute’ window. Missing = 0 means that the attribute is specified for all instances (no missing values), Distinct = 12 means that Temperature has twelve different values, and Unique = 10 means that other attributes or instances have the same 10 value as Temperature has. Temperature is a Numeric value; therefore, you can see the statistics describing the distribution of values in the data - Minimum, Maximum, Mean and Standard Deviation. Minimum = 64 is the lowest temperature, Maximum = 85 is the highest temperature, mean and standard deviation. Compare the result with the attribute table “weather.xls”; the numbers in WEKA match the numbers in the table.
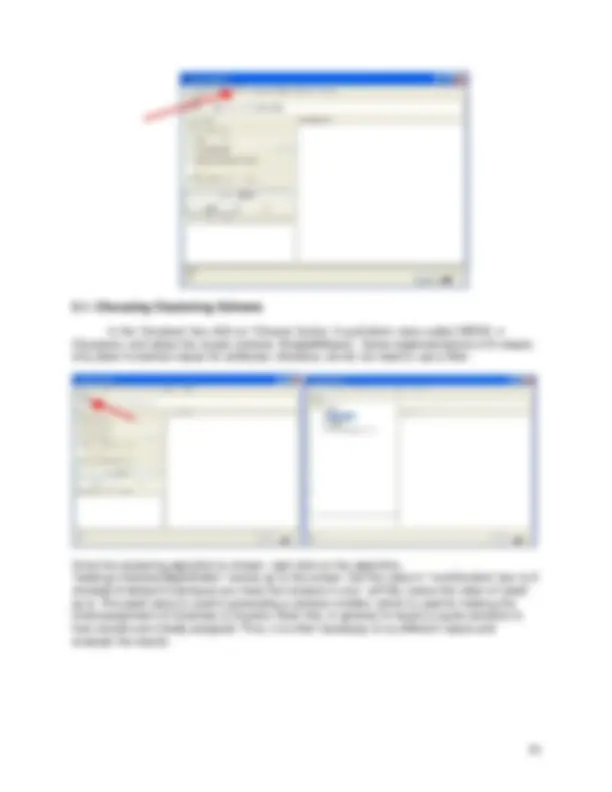
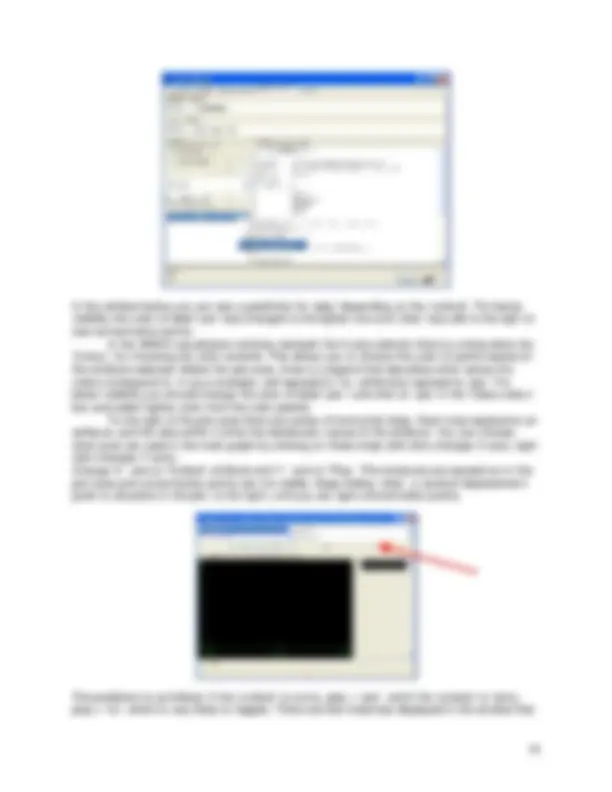
You can select a class in the ‘Class’ pull-down box. The last attribute in the ‘Attributes’ window is the default class selected in the ‘Class’ pull-down box.
You can Visualize the attributes based on selected class. One way is to visualize selected attribute based on class selected in the ‘Class’ pull-down window, or visualize all attributes by clicking on ‘Visualize All’ button.
Pre-processing tools in WEKA are called “filters”. WEKA contains filters for discretization, normalization, resampling, attribute selection, transformation and combination of attributes [4]. Some techniques, such as association rule mining, can only be performed on categorical data. This requires performing discretization on numeric or continuous attributes [5]. For classification example you do not need to transform the data. For you practice, suppose you need to perform a test on categorical data. There are two attributes that need to be converted: ‘temperature’ and ‘humidity’. In other words, you will keep all of the values for these attributes in the data. This means you can discretize by removing the keyword "numeric" as the type for the
As you can see, there is no change in the value Outlook. Select value Temperature, look at the ‘Selected attribute’ box, the ‘Type’ field shows that the attribute type has changed from Numeric to Nominal. The list has changed as well: instead of statistical values there is count of instances, and the count of it is 14 that means that there are 14 instances of the value Temperature.
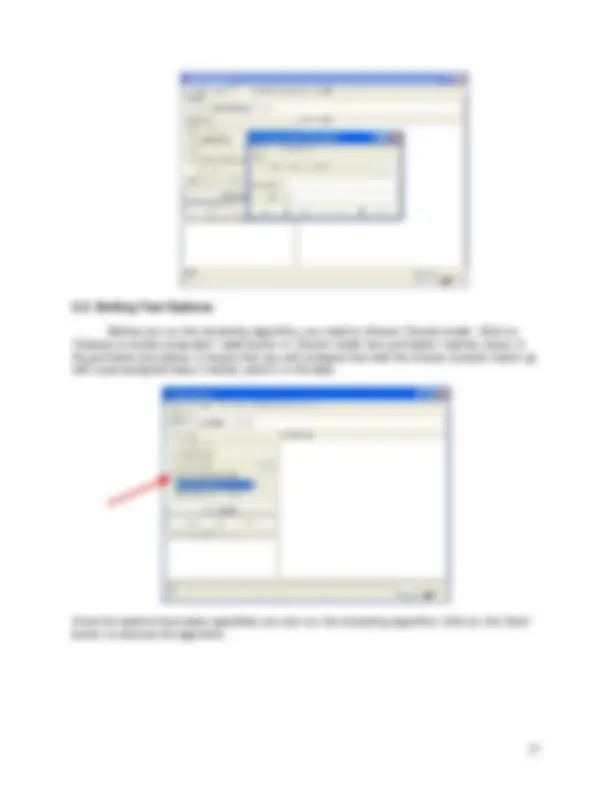
Note, when you right-click on filter, a ‘GenericObjectEditor’ dialog box comes up on your screen. The box lets you to choose the filter configuration options. The same box can be used for classifiers, clusterers and association rules. Clicking on ‘More’ button brings up an ‘Information’ window describing what the different options can do.
At the bottom of the editor window there are four buttons. ‘Open’ and ‘Save’ buttons allow you to save object configurations for future use. ‘Cancel’ button allows you to exit without saving changes. Once you have made changes, click ‘OK’ to apply them.
Classifiers in WEKA are the models for predicting nominal or numeric quantities. The learning schemes available in WEKA include decision trees and lists, instance-based classifiers, support vector machines, multi-layer perceptrons, logistic regression, and bayes’ nets. “Meta”- classifiers include bagging, boosting, stacking, error-correcting output codes, and locally weighted learning [4].
Once you have your data set loaded, all the tabs are available to you. Click on the ‘Classify’ tab.
‘Classify’ window comes up on the screen.
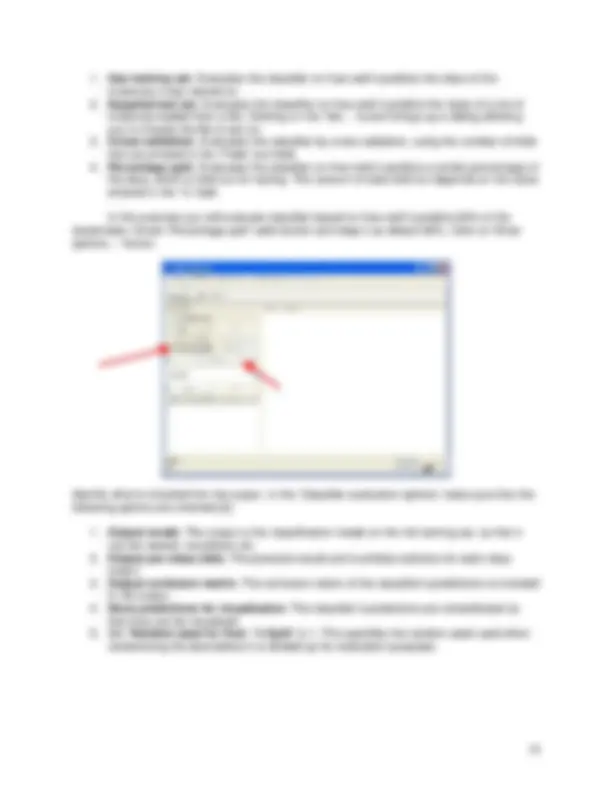
In this exercise you will evaluate classifier based on how well it predicts 66% of the tested data. Check ‘Percentage split’ radio-button and keep it as default 66%. Click on ‘More options…’ button.
Identify what is included into the output. In the ‘Classifier evaluation options’ make sure that the following options are checked [2]:
The remaining options that you do not use in this exercise but that available to you are:
Once the options have been specified, you can run the classification algorithm. Click on ‘Start’ button to start the learning process. You can stop learning process at any time by clicking on ‘Stop’ button.
When training set is complete, the ‘Classifier’ output area on the right panel of ‘Classify’ window is filled with text describing the results of training and testing. A new entry appears in the ‘Result list’ box on the left panel of ‘Classify’ window.