



CS181 Lecture 6:
Neural-Networks II: Multilayer
Networks
Prof. David C. Parkes













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Prof. David C Parkes, Computer Science, Neural-Networks, Multilayer Networks, Minsky and Papert’s Argument, Harvard, Lecture Notes
Typology: Study notes
1 / 21

This page cannot be seen from the preview
Don't miss anything!
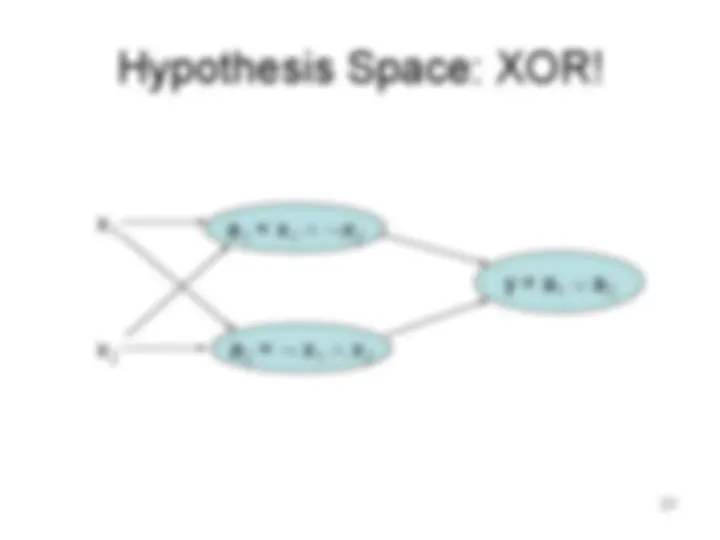
Minsky and Papert‟s Argument
Minsky and Papert‟s Argument
x 1
x 1000
Á 1 ( x )
perceptron output
Á 100 ( x )
Layered Networks
x 1
x 2
Weights and Activations
x 1
x 2
w 11
w 21
w 12
w 22
w 31
w 32
Forward Propagation
Challenge: Learning Weights
Properties of Sigmoid
in e
g in
1
1 ( )