Scarica Alberi binari di ricerca: implementazione ed analisi della complessità - Prof. Acciaro e più Appunti in PDF di Algoritmi E Strutture Di Dati solo su Docsity!
Problema della Ricerca
Un dizionario rappresenta un insieme di informazioni suddiviso per elementi ad ognuno dei quali è associata una chiave. Esempio di dizionario è l’elenco telefonico dove la chiave è costituita dalla coppia cognome, nome e gli elementi dalle informazioni quali numero telefonico ed indirizzo. Altro esempio classico di dizionario è rappresentato dal vocabolario della lingua italiana dove ad ogni parola, chiave del dizionario, è associato un significato. L’insieme minimo di operazioni attuabili su un dizionario è costituito dalle operazioni di ricerca, inserimento e cancellazione dove, la ricerca restituisce un elemento associato ad una chiave, l’inserimento inserisce all’interno del dizionario una nuova coppia, chiave ed elemento, e la cancellazione cancella la coppia, chiave ed elemento. Tratteremo in questa sezione alcune possibili implementazioni di un dizionario che si distinguono nell’organizzazione delle informazioni e quindi nella complessità delle tre operazioni. Vedremo ad esempio che una possibile soluzione di implementazione di un dizionario è la lista ordinata e che in tal caso l’operazione di ricerca ha una complessità O(log n) mentre le operazioni di inserimento e cancellazione hanno una complessità O(n). Così come vedremo che gli alberi AVL costituiscono anch’essi una valida alternativa di implementazione di un dizionario e che in tal caso, invece, le tre operazioni hanno tutte complessità O(log n). E’ bene evidenziare, sin da ora, che non esiste in assoluto la migliore soluzione per l’implementazione di un dizionario. La scelta della struttura dati dipende infatti da molteplici fattori ed emerge solo a seguito di un analisi volta ad individuare sia le operazioni maggiormente ricorrenti che il grado di complessità che si vuol affrontare in fase di realizzazione. Ad esempio, se a seguito di un analisi emergesse che durante il proprio ciclo di vita il dizionario non sarà particolarmente dinamico nelle sue componenti, potrebbe risultare preferibile penalizzare le operazioni di cancellazione ed
inserimento a scapito di una maggiore semplicità di realizzazione e quindi magari ricorrere alla implementazione tramite lista ordinata. Caso opposto, invece, è quello in cui ricerca, cancellazione ed inserimento hanno simile grado di ricorrenza. Potrebbe in tal caso risultare opportuno ricorrere ad una implementazione mediante alberi AVL, affrontando quindi una fase di realizzazione più laboriosa ma assicurandosi nel contempo per tutte e tre le operazioni una complessità logaritmica nel numero degli elementi. Prima di introdurre le possibili implementazioni descriviamo l’ADT Dizionario.
Tipo di dati: Dizionario Insieme di coppie (Chiave, Elemento)
Operazioni: Inserisci( Chiave k, Elemento e ) Aggiunge una coppia (Chiave, Elemento) al dizionario Cancella( Chiave k ) Cancella dal dizionario la coppia (Chiave, Elemento) individuata dalla chiave k Cerca( Chiave k )ÆElemento Restituisce l’elemento del dizionario al quale è associata la chiave k
Avremo quindi che per:
- ricercare l’elemento i , valutiamo semplicemente se lo i -esimo elemento del bit vector è true o false;
- inserire l’elemento i : poniamo lo i -esimo elemento del bit vector uguale a true;
- cancellare l’elemento i , poniamo lo i -esimo elemento del bit vector uguale a false. Considerando che l’accesso allo i -esimo elemento di un array ha tempo costante rispetto al numero di elementi in esso contenuti, abbiamo che le operazioni di ricerca, inserimento e cancellazione hanno tutte complessità costante.
Esempio Si prendi in considerazione la gestione delle prenotazioni delle camere di un albergo. Ad ogni camera è associato un valore intero rappresentante il numero di stanza. E’ possibile creare, quindi, un vettore di bit avente dimensione pari al numero di stanze dell’albergo e:
- quando inseriamo una prenotazione per la stanza i poniamo lo i-esimo elemento del vettore uguale a true;
- quando cancelliamo una prenotazione per la stanza i poniamo lo i-esimo elemento del vettore uguale a false;
- quando si deve verificare se la stanza i è prenotata valutiamo il valore assunto dallo i-esimo elemento del vettore booleno.
2. Alberi Binari di Ricerca (BST)
Vedremo in questo paragrafo come organizzare le informazione del dizionario mediante la struttura dati Albero Binario di Ricerca. Crediamo opportuno sottolineare che, anche se all’interno del corso tratteremo gli alberi binari di ricerca solamente nello studio dell’ADT Dizionario, non bisogna ad ogni modo commettere l’errore di confinare il loro utilizzo esclusivamente all’interno di tale ambito. Gli alberi binari di ricerca sono strutture dati valide oltre che per la realizzazione degli operatori base dell’ADT Dizionario, ricerca, inserimento e cancellazione, anche per l’implementazione di altri operatori quali la ricerca del successivo, la ricerca del predecessore, la ricerca del massimo o la ricerca del minimo, operatori applicabili ad ADT di altro tipo quali ad esempio l’ADT Coda a Priorità.
Definizione: un albero binario di ricerca è un albero binario che soddisfa le seguenti proprietà:
- in ogni nodo dell’albero è contenuta la coppia (chiave, elemento);
- le chiavi sono estratte da un insieme totalmente ordinato;
- ogni chiave del sottoalbero sinistro del nodo v è minore o al massimo uguale alla chiave contenuta nel nodo v ;
- ogni chiave del sottoalbero destro del nodo v è maggiore o al massimo uguale alla chiave contenuta nel nodo v.
Esempio Solo la prima raffigurazione rappresenta un albero binario di ricerca.
40
20 60
10 30 55 80
5 15
40
20 60
10 50 55 80
5 15
Violazione dellaterza proprietà
Inserimento In un albero binario, inseriamo un nuovo nodo sempre come foglia. Diamo luogo ad un inserimento in considerazione dei seguenti macro passi:
Ricerca del giusto padre , individuiamo il nodo v che possiede le proprietà adatte per essere genitore del nuovo nodo. La ricerca del giusto padre avviene scendendo lungo l’albero, con la stessa metodologia utilizzata per l’operazione di ricerca, fin quando non si incontra un nodo v che non ha figlio sinistro ed ha la chiave maggiore di quella dell’elemento da inserire oppure un nodo v che non ha figlio destro ed ha la chiave minore di quella dell’elemento da inserire. Inserimento nodo: trovato il giusto padre inseriamo il nuovo nodo come figlio destro o sinistro nel rispetto delle proprietà di ricerca
Analizziamo la complessità. Poiché l’algoritmo scorre lungo un intero verso l’albero binario di ricerca, si ha che la complessità anche in questo caso è lineare rispetto all’altezza dell’albero: O(h).
Esempio Inserimento elemento con chiave 14.
Cancellazione Prima di procedere nella cancellazione di un nodo all’interno di un albero binario di ricerca vediamo le seguenti due procedure poste al servizio dell’operazione di cancellazione.
Ricerca del massimo Le proprietà di ricerca garantiscono che per l’individuazione della chiave più grande presente in un albero binario di ricerca dobbiamo scendere, quanto più possibile, lungo il verso destro dell’albero.
Alberi binari di Ricerca- Ricerca del massimo _ max( Nodo u ) Æ Nodo { Nodo v v = u while( v.destro != NULL ) v = v.destro ritorna v }
L’algoritmo di ricerca del massimo ha, nel caso pessimo, una complessità lineare rispetto all’altezza dell’albero.
Ricerca del predecessore Indichiamo con il termine di predecessore di un nodo v quel nodo contenente come chiave il massimo dell’insieme delle chiavi più piccole di quella contenuta in v. In un albero binario di ricerca il predecessore di un nodo v è:
- il massimo del sottoalbero sinistro, se v ha un figlio sinistro; 2. il più basso antenato di u il cui figlio destro è anch’esso antenato di u ( “ risali l’albero fin quando non incontri una svolta a sinistra ”), altrimenti;
- u ha due figli (figura 2.2): in tal caso sia v il predecessore di u. Poiché u ha due figli il predecessore sarà il massimo del sottoalbero sinistro di u e pertanto v sarà una foglia oppure un nodo interno avente al max un solo figlio: quello sinistro^2. La cancellazione di u pertanto può avvenire copiando la chiave di v in u ed eliminando v cadendo per quest’ultima operazione nei due casi precedenti.
La cancellazione al pari delle altre due operazioni, ricerca ed inserimento, ha una complessità proporzionale all’altezza dell’albero poiché nel caso pessimo potremmo muoverci su l’intera altezza dell’albero alla ricerca del predecessore.
Figura 2.1 –Eliminazione nodo con un solo figlio
(^2) Se v avesse una figlio destro esisterebbe una chiave più grande di v e quindi v non rappresenterebbe il massimo del sottoalbero sinistro di u.
Figura 2.2 – Eliminazione nodo con due figli
u
v
w
t
v
v
w
t
Passo 1 Copia delle
v
v
w
t
Passo 2 Eliminazione di v
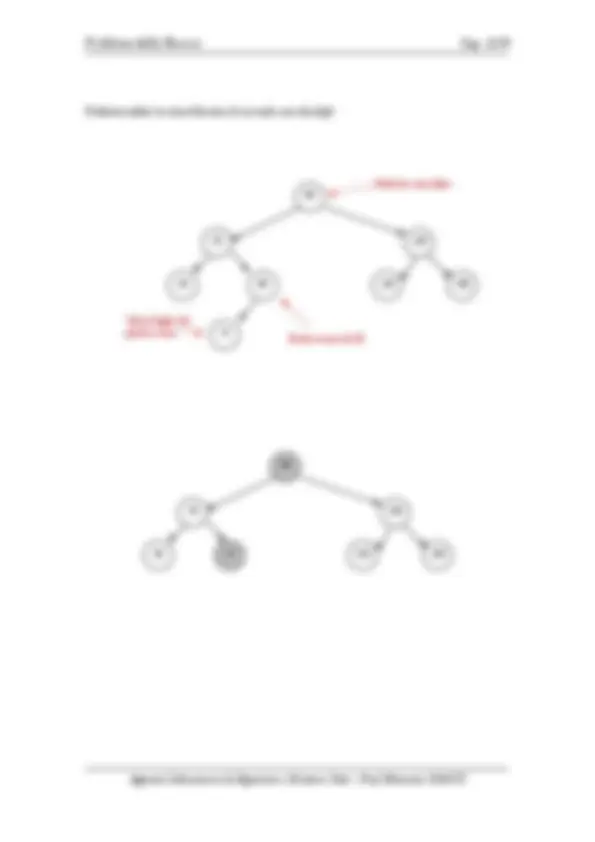
Vediamo infine la cancellazione di un nodo con due figli
80
50
20 60
54
120
110 130
Predecessore di 80
Nodo da cancellare
Unico figlio del predecessore
60
50
20 54
120
110 130
2.1 Analisi dell’altezza di un albero binario di ricerca
Come visto precedentemente, mediante la struttura dati alberi binari di ricerca siamo in grado di implementare algoritmi di inserimento, cancellazione e ricerca aventi complessità lineare con l’altezza dell’albero. L’analisi che ci accingiamo a svolgere all’interno del presente paragrafo ha come obiettivo quello di esprimere tale complessità in termini di numero di nodi del grafo ovvero in termini di numero di elementi presenti nel dizionario. Vediamo prima alcune nozioni propedeutiche all’analisi.
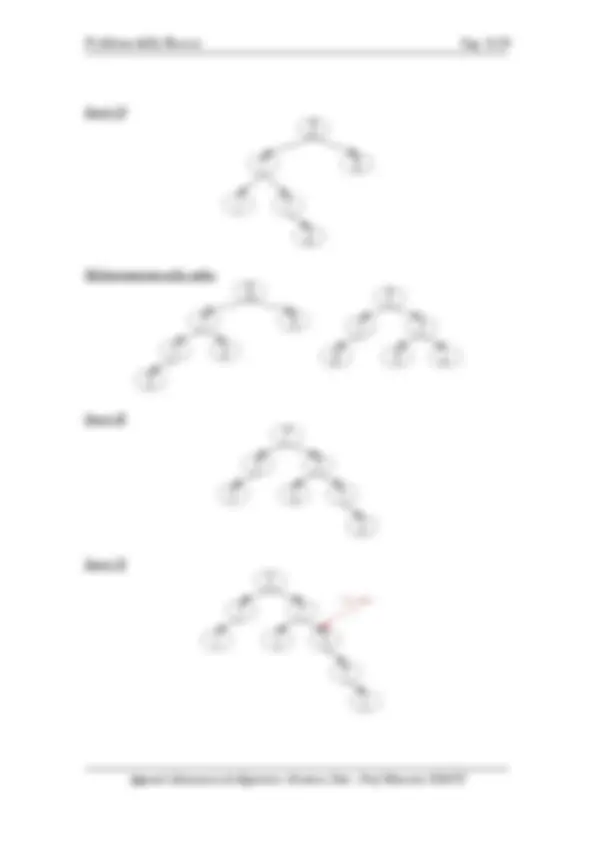
Definizione: un albero binario si definisce completo se ogni nodo interno ha due figli e tutte le foglie appartengono allo stesso livello.
Esempio
Albero binario completo
v
Albero binario non completo , v non ha due figli
Albero binario non completo , tutti i nodi interni hanno due figli ma le foglie non appartengono allo stesso livello
Analisi della complessità - Caso 2: altezza media Presupposto dell’analisi dell’altezza media di un albero binario di ricerca è l’inserimento in ordine puramente casuale dei nodi all’interno dell’albero. Tutti gli elementi del dizionario hanno uguale probabilità di essere scelti e quindi inseriti. Sulla base di tale ipotesi dimostreremo che l’altezza dell’albero è O(log n) e pertanto nel caso medio le tre operazioni del dizionario hanno tutte complessità O(log n).
Teorema 2.1.3. sia T un albero binario di ricerca ottenuto mediante una serie di inserimenti di n coppie (chiave, elemento). Sia inoltre l’ordine di inserimento degli elementi puramente casuale. Si indichi infine con P(n) l’altezza media dell’albero T, allora si ha che: P(n) = O( log n)
Dim: indichiamo con {a 1 , ..., an } l’insieme degli elementi da inserire all’interno dell’albero. Affinchè l’ordine di inserimento sia ritenuto puramente casuale dobbiamo avere che la probabilità di scelta degli elementi sia equidistribuita, ovvero che essa sia uguale ad 1/n per ogni elemento. Indichiamo con a il primo elemento che viene prelevato dalla lista per essere inserito all’interno dell’albero. Essendo la probabilità di scelta equi distribuita abbiamo che la probabilità che a sia uguale ad un qualunque a (^) i è pari ad 1/n per ogni i=1,...,n. Al termine dell’inserimento di tutti gli elementi è lecito raffigurare l’albero binario di ricerca nel seguente modo:
dove nel sottoalbero sinistro sono contenuti gli elementi associati alle chiavi più piccole di a e nel sottoalbero destro gli elementi associati alle chiavi più grandi di a. Indichiamo quindi con i il numero di chiavi più piccole di a e con n-i-1 quelle più grandi di a. Indichiamo inoltre con P(i) e con P(n-i-1) rispettivamente le altezze medie del sottoalbero sinistro e destro quando l’elemento a (^) i è radice dell’albero. Abbiamo che l’altezza media dell’intero albero, P(n) , sarà calcolabile a partire dalla seguente formula: n Pn i n Pi n i n P n i i
( )= ( ()+ 1 )+ − −^1 ( ( − − 1 )+ 1 )+^1
dove:
n-i-1 maggiori chiavi di a
i chiavi minori di a
a
P (^) i (n) : è l’altezza media dell’intero albero contenente n elementi ed avente la radice a = ai. i/n : è la probabilità di aver “pescato” i elementi più piccoli di a dopo l’inserimento di a ; P(i)+1 : è l’altezza media del sottoalbero sinistro più il nodo a ; (n-i-1)/n : è la probabilità di aver “pescato” n-i-1 elementi più grandi di a dopo l’inserimento di a ; P(n-i-1) : è l’altezza media del sottoalbero destro più il nodo a ; 1/n : è la probabilità di aver “pescato” a come primo elemento. Pertanto considerando che la probabilità che un elemento sia radice dell’albero è pari ad 1/n abbiamo:
= (^) ∑ = ∑ + + − − − − + + =
−
− = n
Pn n P n n ni Pi n ni Pn i
n io
n i i
( )^11 ( )^11 ( () 1 )^1 ( ( 1 ) 1 )^1
0 = (^) ∑ + + − − − − + − − + =
− = n n
Pn i n i n
n i n Pi i n
i n
n io
= (^) ∑ + − − − − + + − − + =
− = n
Pn i i n i n Pi n i n
i n
n io
= (^) ∑ + − − − − + =
−
1 n ni Pi n ni Pn^ i
n io =
= ^ +∑− + − − − −
1 n n ni Pi n ni Pn^ i
n io
=
= ^ + ∑− + − − − −
1 n n n iPi n i Pn^ i
n io = + ∑ + − − − − =
−
1 n^2 iPi n i Pn i
n io = + ∑ =
−
1 n^2 iPi
n io = + ∑ =
−
1 n^2 iPi
n io
1 (^2 ) n iPi
n ∑ i
−
Quest’ultima uguaglianza è giustificata dal fatto che per i uguale a zero iP(i)=. Ricapitolando abbiamo che:
( ) 1 2 ()
1 (^2 ) Pn n iPi
n ∑ i
−
Ora, procedendo per induzione su n, dimostriamo che: P ( n )≤ 1 + 4 log n (1)
e pertanto riscrivere la disuguaglianza come:
≤ + ∑ + ∑
− =
−
Pn n i n i n
n i n
n
i
( ) 2 8 log 2 log
1
2
2 1 (^21)
Analizziamo ora separatamente le due sommatorie considerando i due diversi casi: n è pari ed n è dispari. n pari
1
2 1 1
n
n n n n i i
n
i
n
i
^ −
∑ =^ ∑ =
−
−
^ −
∑ =^ ∑ = ∑ −∑ = − −
−
−
−
− = (^) ^2
1
1 1
1
2
1
2
n n i i i i nn
n
i
n i
n in
n i n
= (^2 −^1 )− 4 ^ − 22 = 2 − − − 82 =^4 −^48 − +^2 =
nn n n n^2 n n^2 n n^2 n n^2 n
=^3 n^^2 −^2 n ≤ n^2
n dispari
1
211 1
2 1 1
n n n n
n n n n i i i
n
i
n
i
n
i
^ − ^ +
^ − ^ − +
∑ =^ ∑ = ∑ =
−
=
+−
=
−
^ − + ^ −
∑ =^ ∑ = ∑ −∑ = ∑ −∑ = − −
−
=
−
+−
=
−
− =+
− = (^) ^2
1
1
1 1
211 1
1 1
1
21
1
2
n n i i i i i i nn
n
i
n i
n
i
n i
n in
n i n
^ + ^ −
= − − 2 2 ( 21 ) (^1 )( 8 1 )
( 1 ) nn n n
n n nn
=^4 n (^ n −^1 )−( n +^1 )( n −^1 ) = n^2 − n − n^2 + = n^2 − n + ≤ n^2
Dall’analisi fatta sopra sulle sommatorie ne deriva che:
^ =
≤ + ^ +
≤ + ∑ + ∑
− =
−
Pn n i n i n n n n n n
n i n
n
i
( ) 2 8 log 2 log 2 8 8 log 2 38 log
2 2 2
1
2
2 1 (^21)
= 2 + log n 2^ + 3 log n = 2 +log n −log 2 + 3 log n = 2 +log n − 1 + 3 log n = 1 + 4 log n