Scarica Bioinformatica: Allineamento di Sequenze e Analisi Filogenetica e più Appunti in PDF di Bioinformatica solo su Docsity!
BIOINFORMATICA E CHEMOGENOMICA
INTRODUZIONE
La BIOINFORMATICA viene definita come lo studio dei problemi genomici attraverso le metodologie dell’informatica, e può quindi essere vista come l’unione della biologia molecolare e dell’informatica. La bioinformatica si sviluppa agli inizi degli anni ‘80 in concomitanza con lo sviluppo dei metodi di sequenziamento rapido degli acidi nucleici, e nasce dall’esigenza di gestire i dati biologici (per gestione si intende il mantenimento - ovvero la cura manuale da parte di personale esperto e il costante aggiornamento delle informazioni – l’organizzazione e la distribuzione) e di analizzare i dati biologici (ovvero inferire e fare predizioni sul significato biologico dei dati raccolti). La nascita della GENOMICA, disciplina che si occupa dello studio dei genomi completi degli organismi, è stata possibile proprio grazie all’unione di metodi bioinformatici a metodi di sequenziamento automatico. Ad oggi abbiamo a disposizione le sequenze complete di moltissimi organismi, e ci troviamo infatti nell’era POST- GENOMICA in cui dobbiamo essere in grado di interpretare i dati raccolti, gli aspetti più rilevanti in questa era sono:
- Studi di genomica funzionale : ovvero essere in grado di caratterizzare la funzione di geni umani e di altri organismi modello attraverso lo studio del TRASCRITTOMA [ dove per trascrittomica si intende la disciplina che si occupa dello studio dell’insieme degli mRNA di una cellula ] e del PROTEOMA [ dove per proteomica si intende la disciplina che si occupa dello studio del set completo di proteine espresse in una cellula ].
- Studi di genomica comparata : che consiste nell’analisi comparativa tra genomi come supporto agli studi di genomica funzionale.
- Chemogenomica : ovvero lo studio delle interazioni tra geni e composti bioattivi. La chemogenomica utilizza composti organici di piccole dimensioni, in genere chiamati “ small molecules ” o “ drugs ”, per studiare come il genoma è in grado di codificare per le diverse funzioni che una cellula svolge. L’assunto alla base della chemogenomica è che le small molecules/drugs utilizzate negli studi possono essere in grado di comportarsi come mutazioni in grado di inattivare un gene target (o più propriamente inattivare la proteina per cui il gene target codifica). Il fenotipo che si osserva a seguito dell’utilizzo della drug deve quindi essere lo stesso fenotipo osservato a seguito di un knock out genico, e per fare ciò sono quindi necessarie drugs potenti e specifiche per il gene target d’interesse. Ad esempio se il gene che si inattiva è un gene essenziale, il fenotipo osservato sarà la morte della cellula sia che si utilizzi il knock out genico sia che si utilizzi la drug: Lo scopo dell’utilizzo di queste molecole è individuare la funzione di un gene, la relazione tra gene e drug utilizzata ed eventualmente la correlazione tra geni e patologie. La chemogenomica viene in particolare usata per studi di farmacogenomica [ la farmacogenomica si occupa dello studio del genoma e dei suoi prodotti – RNA e proteine – nella risposta a livello cellulare/tissutale al farmaco, con il fine di individuare nuovi target terapeutici e creare nuovi farmaci ]. Per la drug discovery possono essere utilizzati due approcci diversi: Mancata produzione della proteina perché è stato inattivato il gene essenziale Inattivazione della proteina per azione della drug Forward Drug Discovery approach : Questo tipo di approcci si basa sull’utilizzo iniziale di saggi fenotipici su larga scala che non hanno un target definito. Ad esempio si vuole individuare un farmaco in grado di bloccare il ciclo cellulare di lievito durante la gemmazione, un grande numero di cellule diverse vengono trattate con diversi composti, e individuato il fenotipo d’interesse risalgo al farmaco che ha sortito l’effetto desiderato. Reverse Drug Discovery approach : In questo tipo di approccio si parte con uno specifico target che si vuole colpire (spesso una proteina codificata da un gene) e si cerca di individuare un farmaco in grado di inibire o attivare il target d’interesse.
Il dogma della bioinformatica è che sequenze amminoacidiche o nucleotidiche simili hanno spesso strutture simili e quindi di conseguenza funzioni simili. A partire da una sequenza biologica primaria è quindi possibile predirne la funzione. Gli “oggetti della bioinformatica” primari sono considerati sequenze di acidi nucleici o di proteine, strutture di macromolecole e fenotipi (ovvero le funzioni, che possono essere raggruppate in pathway, network o profili trascrittomici). Per ognuno di questi oggetti esistono banche dati dedicate in cui raccogliere le informazioni. Gli strumenti della bioinformatica sono quindi: BANCHE DATI: che raccolgono informazioni su acidi nucleici, proteine, strutture di macromolecole ecc… PROGRAMMI: le banche dati si interfacciano però con programmi che permettono di analizzare e visualizzare i dati presenti nelle banche dati. BANCHE DATI BIOLOGICHE Le banche dati sono definite come un insieme di dati strutturati, dove per strutturati si intende dati omogeni per contenuti e formato, memorizzati in un computer → rappresentano quindi la versione digitale di un archivio dati. Si deve però distinguere tra:
- Data bank o Banca dati che rappresenta la collezione di dati;
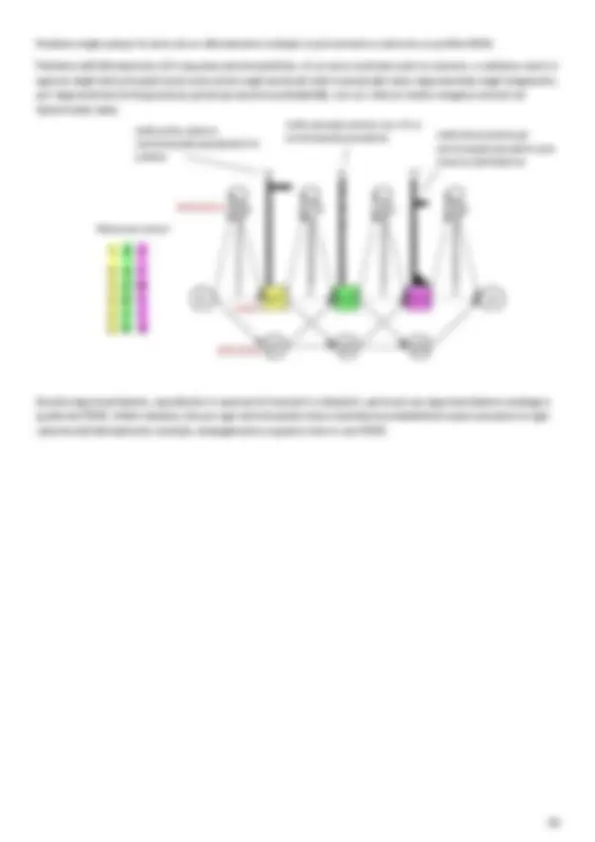
- Database o Base di dati che rappresenta l’insieme della collezione di dati e dei software utilizzati per accedervi. Storia delle banche dati biologiche I primi dati biologici che si ebbero a disposizione furono le sequenze proteiche, ottenute grazie al sequenziamento proteico, negli anni ’60 da Margaret Dayhoff. Dato che inizialmente si avevano a disposizione un numero limitato di sequenze, queste venivano raccolte in libri. Margaret Dayhoff fu la prima a porsi il problema di come organizzare le informazioni derivanti dal sequenziamento proteico, creando un “atlante” di sequenze proteiche PIR - Protein Identification Resource. Dayhoff decide di organizzare le proteine sulla base del grado di similarità di sequenza in famiglie e superfamiglie [ il suo lavoro è anche alla base della creazione delle matrici di punteggio e della classificazione delle proteine in famiglie che oggi ancora alcuni database, come Pfam, sfruttano ]. Alla fine degli anni ’70 la prima banca dati che raccoglieva strutture di macromolecole (PDB) si trovava su floppy disk. Agli inizi degli anni ’80 sono nate le prime banche dati di sequenze nucleotidiche (EMBL e GenBank) su Cd-room. GenBank è la banca dati di sequenze nucleotidiche statunitense, assemblata al Los Alamos National Laboratory (LANL) in New Mexico da Walter Goad nel 1979 ; oggi GenBank è sotto il controllo di NCBI - National Center for Biotechnology Information. La controparte europea di GenBank è EMBL - European Molecular Biology Laboratory
proteico diretto, ma ad oggi la quasi totalità delle sequenze proteiche sono ricavate dalla traduzione di sequenze codificanti di DNA. SwissProt presenta la particolarità di essere una banca dati manualmente annotata e verificata, infatti è costituita da un numero relativamente ridotto di entries (circa 560.823); mentre TrEMBL viene automaticamente annotata e non viene sottoposta a processo di review, infatti presenta un numero decisamente maggiore di entries (circa 171.501.488). TrEMBL deriva dalla traduzione automatica di sequenze depositate in EMBL → esistono infatti banche dati proteiche che derivano dalla traduzione automatica di sequenze depositate in banche dati nucleotidiche. Oltre a TrEMBL si ha anche GenPep che deriva dalla traduzione automatica di sequenze di DNA depositate in GenBank. Sia GenPep che TrEMBL sono annotate in modo molto meno accurato di SwissProt e Pir, ma sono banche dati più complete ed aggiornate. Tra le più importanti banche dati primarie di strutture molecolari troviamo invece PDB - Protein Data Bank. Strutture delle banche dati Le informazioni biologiche che vengono caricate nelle banche dati sono dette “ entry ”, ogni entry è identificata da un Entry name e da un Accession Number. Gli Accession Number sono identificativi univoci usati per identificare sequenze o altri records rilevanti inerenti a dati molecolari. Gli accession number si presentano come delle stringhe alfanumeriche, e la struttura del codice ci indica da quale banca dati proviene → Alcune banche dati sono più curate di altre, e quindi riconoscere da quale banca dati proviene l’informazione è importanti per darci una indicazione su quanto i dati del record siano affidabili. Per ogni entry oltre ad entry name ed accession number possiamo trovare associate informazioni aggiuntive che sono dette attributi o entità. Tutti questi elementi devono essere inseriti all’interno della banca dati in modo ordinato: Il database rappresenta una collezione di record, dove ogni record è costituito dalla entry e dalle informazioni aggiuntive associate alla entry. Le caratteristiche relative ad una entry sono descritte da fields (campi). Vediamo come esempio di struttura di banca dati NCBI: NCBI - National Center for Biotechnology Information (finanziato a sua volta da NIH) è un database che ospita e gestisce varie banche dati di sequenze nucleotidiche/genomiche (come GenBank), di sequenze proteiche, e banche dati di articoli scientifici (PubMed). Inoltre NCBI si occupa anche di sviluppare strumenti e software per analizzare i dati biologici presenti nei database → in particolare NCBI ha sviluppato BLAST, un algoritmo che permette di effettuare ricerche in banche dati per similitudine tra sequenze nucleotidiche o amminoacidiche.
Le banche dati sono quindi integrate all’interno di database di dimensione maggiore, come ad esempio NCBI, e sono collegate tra di loro: Una tipica entry di sequenza nucleotidica di GenBank si presenta come segue: Le sequenze amminoacidiche o nucleotidiche vengono sottomesse nella banca dati in formato FASTA. Il formato FASTA è un formato di testo in cui il nome della sequenza si trova tra due elementi: il simbolo “>” e “a capo”. Nelle righe successive viene riportata tutta la sequenza nel formato a singola lettera in cui ogni simbolo corrisponde ad un amminoacido o nucleotide. Questo è il formato base che permette ai programmi di riconoscere immediatamente le informazioni relative alle sequenze (nome e sequenza nucleotidica/amminoacidica), anche quando più sequenze sono introdotte nello stesso momento.
Esempio di formato FASTA →
L’importanza delle banche dati non ridondanti e del database RefSeq Inizialmente le informazioni che venivano raccolte nelle banche dati erano informazioni derivanti dalla letteratura scientifica, e inserite manualmente da operatori esperti. Oggi le informazioni sono invece sottomesse direttamente dagli autori [ inoltre la sottomissione di sequenze/strutture di macromolecole nelle banche dati è condizione essenziale per pubblicare sulle principali riviste. I dati sono di solito secretati fino alla pubblicazione “entries hold until published” ]. Dato che l’autore ha controllo completo sui dati sottomessi significa che: solo l’autore può modificare l’informazione del proprio record e altri non possono correggere l’informazione presente anche se questa è chiaramente errata; e la possibilità di trovare informazioni dipende da quanto accuratamente è stata descritta dall’autore. Troviamo nella sezione CDS una traduzione della sequenza codificante
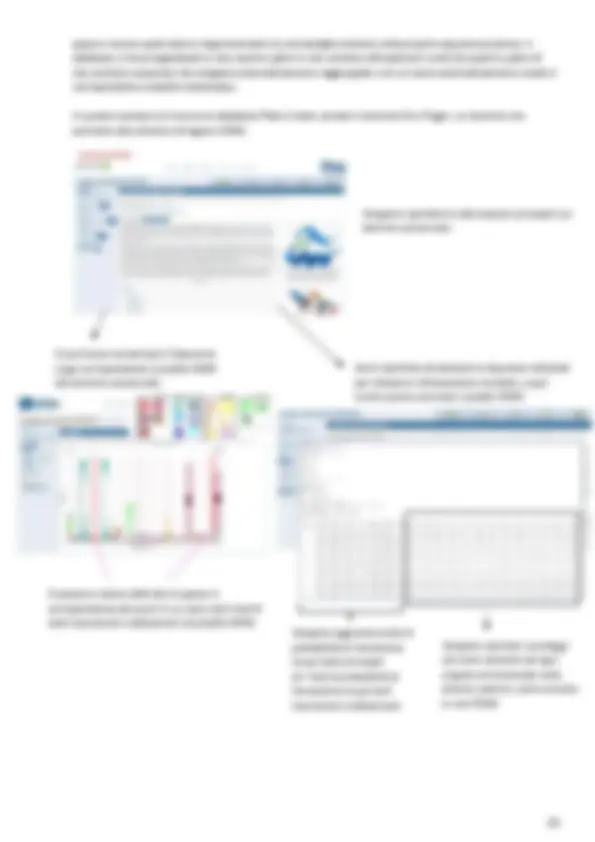
All’interno di RefSeq è anche visibile un genome brower che permette di navigare nel genoma e vedere cosa è presente a valle e a monte di un gene target d’interesse, mostra il senso di trascrizione del gene target e mostra inoltre tutti i possibili splicing alternativi del gene: Interrogazione delle banche dati E’ importante conoscere i sistemi tramite cui si può INTERROGARE una banca dati → interrogare una banca dati significa fare una ricerca testuale nella porzione “header” dei record, contenente le informazioni di testo sulla sequenza. Le banche dati si possono interrogare singolarmente; oppure è possibile fare ricerche incrociate in più banche dati sfruttando database come NCBI che attraverso il suo motore di ricerca Entrez permette di eseguire ricerche in più banche dati contemporantemante come ad esempio banche dati proteiche, banche dati nucleotidiche, banche dati di mutazioni (SNP), banche dati di letteratura scientifica (PubMed) ecc… Banche dati presenti all’interno
del database NCBI →
La ricerca può quindi avvenire: Tramite parole chiave o tramite accession number Per la ricerca tramite parola chiave è possibile sfruttare i boolean queries ovvero: AND, OR o NOT. Poniamo ad esempio di voler utilizzare le parole chiave “Pdcd1” e “cancer” per eseguire una ricerca in letteratura tramite la banca dati PubMed, i risultati ottenuti sfruttando i boolean queries sono i seguenti: Sfruttando i link e i filtri presenti sul database I link possono agire come filtri per rifinire la ricerca della sequenza d’interesse. Ad esempio si può eseguire una ricerca tramite la parola chiave “pdc1” su NCBI, e sfruttare il link “nucleotide” per essere reindirizzati direttamente alla banca dati nucleotidica. Si clicca su nucleotide per essere reindirizzati sulla banca dati
A partire da una entry nucleotidica è possibile arrivare su NCBI alla banca dati proteica semplicemente cliccando sul protein ID presente all’interno della CDS indicata nell’entry: Attraverso ricerca per similarità [ ciò è possibile su NCBI utilizzando BLAST ] E’ importante saper usare i sistemi per interrogare un database propriamente, perché ottenere esattamente l’informazione che si cerca nelle banche dati di sequenze è difficile, soprattutto a seguito dell’aumento della dimensione delle banche dati e soprattutto perché la maggior parte delle entry non sono curate manualmente → è l’autore che decide come descrivere le informazioni, e nelle maggior parte dei database non è presente un gruppo esperto che revisiona le entry per poi assegnare una nomenclatura standard e ciò diventa impattante per la ricerca. Vediamo ad esempio che geni codificanti per l’rRNA 16s possono avere nomenclature molto diverse tra loro: Risultato nella banca dati nucleotidica Risultato nella banca dati proteica
OMOLOGIA, ALLINEAMENTI E MISURE DI SIMILARITA’
OMOLOGIA
Partendo dal presupposto che genomi e geni hanno subito processi di evoluzione divergente, due sequenze si definiscono OMOLOGHE quando derivate da un ancestore comune (e quindi imparentate per evoluzione). Oggi però non si è in grado di stabilire quale sia stata esattamente l’evoluzione di una sequenza, il processo di evoluzione può solo essere dedotto sulla base di confronti tra sequenze. Nonostante il processo di evoluzione divergente abbia portato a mutazioni nelle sequenze, quando due sequenze sono evolutivamente vicine mantengono un certo grado di similarità → questo significa quindi che possono considerare due sequenze omologhe quando allineandole queste risultano simili in modo significativo. Bisogna prestare attenzione al fatto che i termini similarità e omologia hanno in realtà significati distinti: ➔ L’omologia è definibile come un carattere qualitativo , che fa riferimento a presenza/assenza di una relazione evolutiva, e non è quindi corretto parlare di “percentuale di omologia”. ➔ La similarità è invece espressa in termini quantitativi , fa infatti riferimento al grado di similitudine di sue sequenze che viene misurato durante un allineamento. Quindi la presenza di similarità (oltre un certo livello identificato come significativo) esprime una relazione di omologia tra due sequenze. Partendo da una sequenza ancestrale può avvenire un evento di separazione che porta a produrre due sequenze identiche. Nel tempo però le due sequenze che hanno subito l’evento di separazione possono accumulare in modo indipendente mutazioni [ ***** ] di diversa natura, che derivano da errori in fase replicativa del DNA che non vengono corretti dal sistema di riparazione. Ad oggi noi siamo unicamente in grado di osservare la presenza di similarità tra le sequenze allineate, ma non possiamo dedurre quali siano stati i processi evolutivi presenti a monte. Ciò implica che frammenti di DNA aventi la stessa funzione in organismi differenti, o funzioni correlate nello stesso organismo, non hanno esattamente la stessa sequenza in quanto sono avvenute delle sostituzioni puntiformi, delle delezioni e delle inserzioni. L’evento di separazione può essere di due diverse tipologie: o Evento di speciazione a seguito di questo evento si generano due specie diverse, durante il processo di evoluzioni possono essere introdotte mutazioni in modo indipendente nelle due sequenze che si trovano in organismi diversi. Le due sequenze omologhe in questo caso prendono il nome di ORTOLOGHE.
lettere, e un sistema di penalità per la presenza di gaps [ brevi interruzioni nell’allineamento tra le due sequenze ]. Il punteggio totale viene quindi calcolato come ∑ 𝑠𝑜𝑚𝑖𝑔𝑙𝑖𝑎𝑛𝑧𝑒 (𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒 𝑒 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒) − ∑ 𝑝𝑒𝑛𝑎𝑙𝑖𝑡à. Date due sequenze ci sono diversi modi in cui queste possono essere sovrapposte (anche senza considerare l’introduzione di gap), semplicemente andando a slittare una sequenza rispetto all’altra → l’obbiettivo dell’allineamento è ottenere la sovrapposizione ottimale che è quella che presenta il punteggio totale più elevato, conservando l’ordine delle lettere e ammettendo l’introduzione di gaps. Tipicamente l’allineamento viene rappresentato graficamente come segue: in presenza di un match (appaiamento corrispondente tra due lettere) si pone una barra verticale tra le due lettere; in presenza di un mismatch (mancanza di appaiamento tra due lettere) si lascia uno spazio vuoto; mentre in presenza di un gap si pone una barra orizzontale. Un metodo rigoroso per rappresentare tutti i possibili appaiamenti tra due sequenze è rappresentato dalla DOT MATRIX , che è stata ideata nel 1970 da Gibbs e Fitch, e ancor oggi viene utilizzata per mostrare il risultato dell’allineamento tra due sequenze da alcuni software (come BLAST). La dot matrix è una matrice, ai cui margini sono poste le due sequenze che devono essere allineate: una sequenza è scritta da sinistra a destra in corrispondenza del margine superiore, l’altra dall’alto in basso in corrispondenza del margine sinistro. Ogni casella della matrice fa riferimento ad una lettera della prima sequenze e ad una lettera della seconda sequenza. La modalità più semplice per eseguire i confronti è quella in cui le due sequenze vengono fatte scorrere una sopra l’altra, spostandole di volta in volta di un singolo carattere, e confrontando lettera per lettera → se due lettere sono uguali la casella corrispondente alle due lettere viene colorata di nero/segnata con un punto (dot) o un asterisco. L’allineamento migliore è quello che forma una lunga diagonale visivamente distinguibile. _Vediamo un esempio con due sequenze fittizie:
- “margaretoakleydayhoff”
- “margaretdayhoff”_ La quantità di punti che sono presenti nella matrice dot plot è però influenzata dalla natura delle sequenze che vengono confrontate: mentre le sequenze amminoacidiche presentano una grande varietà di lettere, perché si hanno 20 diversi amminoacidi, e quindi si ha una probabilità di 1/20 che il match tra due lettere sia dovuto al caso e non ad una conservazione di lettere per la presenza di omologia di sequenza; le sequenze nucleotidiche sono composte solo da 4 lettere, e quindi si ha una probabilità di 1/4 che il match tra due lettere sia dovuto al caso → una
probabilità molto più elevata. Questa elevata probabilità ci porta quindi ad avere delle dot matrix con un elevato “rumore di fondo” ( noise ) che non ci permette di vedere in modo chiaro la diagonale corrispondente all’allineamento ottimale. Per le sequenze nucleotidiche si deve quindi applicare un metodo di filtraggio che consiste nel non confrontare più lettera per lettera tra le due sequenze, ma confrontare una finestra (window) di caratteri di lunghezza variabile. Si fanno quindi sempre scorrere le due sequenze una sopra l’altra spostandole di un carattere alla volta, ma per ogni confronto si vanno a scontrare finestre di caratteri di W lunghezza. Si deve quindi stabilire una stringenza (stringency), ovvero quanti caratteri devono essere uguali tra loro all’interno di una finestra per poter dichiarare che c’è un match tra le due sequenze. Quando S=1 ci si trova in una situazione di tolleranza, mentre quando S = W si parla di stringenza massima. In genere si preferisce avere finestre di lunghezza dispari, questo perché quando si ha un match tra le finestre nelle due sequenze è possibile porre il dot in corrispondenza del carattere centrale della finestra → si parla di vantaggio del middle point. Possiamo notare la presenza del rumore di fondo, quando per il confronto si mantiene una finestra W=1, ed una stringenza S=1. Se invece utilizziamo una finestra W=4 e una stringenza S=3 otteniamo la seguente situazione:
Si sceglie quindi di utilizzare vie alternative all’allineamento esatto , che sono: Matrici Quando si deve eseguire un allineamento tra sequenze è importante stabilire dei criteri per assegnare punteggi positivi in caso di match tra due caratteri, punteggi negativi in caso di mismatch e penalità per l’apertura di gaps. Quando si vanno a valutare gli allineamenti si deve però tenere conto della tipologia di sequenza con cui si sta lavorando: ➔ Per le sequenze nucleotidiche si valuta unicamente l’ identità , e quindi si possono avere solo due casi: presenza di match o assenza di match. ➔ Per le sequenze amminoacidiche non si può unicamente valutare l’identità, ma si devono tenere in considerazione anche le proprietà chimico-fisiche degli amminoacidi che li rendono simili tra loro. Utilizzo di algoritmi basati sulla PROGRAMMAZIONE DINAMICA. Questa tipologia di algoritmi porta ad ottenere l'allineamento più preciso possibile. Esistono due diverse metodologie che utilizzano la programmazione dinamica:
- Metodo Needleman e Wunsch , implementato nel 1970, ed utilizzato per l’allineamento globale;
- Metodo Smith e Waterman implementato nel 1981, per l’allineamento locale. In entrambi i metodi il numero di calcoli necessari per trovare l’allineamento ottimale non è uguale a nxm come nell’allineamento esatto, ma è proporzionale a nxm. Questo perché per arrivare all’allineamento ottimale si valutano dei sotto-percorsi ottimali. Utilizzo di algoritmi EURISTICI , anche detti approssimati. Questi algoritmi sono meno sensibili rispetto a quelli basati sulla programmazione dinamica, ma garantiscono un aumento di velocità fino anche a 50 volte, sono infatti gli algoritmi utilizzati per la ricerca per similarità in banche dati [ algoritmi implementati nei sistemi di ricerca fastA e BLAST ] → bisogna infatti tenere conto del fatto che nelle banche dati n rappresenta la lunghezza della sequenza d’interesse, mentre m rappresenta la somma delle lunghezze di tutte le sequenze presenti nella banca dati, nxm sarebbe quindi in questo caso un numero esorbitante di confronti. Con entrambe le tipologie di algoritmo è poi possibile eseguire: → Allineamenti globali → Allineamenti locali Identità Identità Somiglianza
Gli amminoacidi possono essere infatti raggruppati a seconda delle loro caratteristiche chimico-fisiche in diversi modi, ad esempio: Oppure ancora secondo questa classificazione: È quindi difficile stabilire dei criteri oggettivi per determinare le somiglianze fisico-chimiche degli amminoacidi perché non è possibile sapere a priori quali caratteristiche sono più importanti per il mantenimento della funzione delle proteine. Bisogna quindi stabilire un modello che sia in grado di quantificare la similarità tra coppie di amminoacidi, però si possono definire molti modelli diversi tra loro, ed è importante sapere che i risultati ottenuti poi dipenderanno esclusivamente dal modello che si è scelto di utilizzare. La prima matrice che si è pensato di utilizzare è stata la MATRICE DI SOSTITUZIONE , questo tipo di matrice è basato sull’osservazione di reali allineamenti tra sequenze proteiche, per essere così in grado di osservare con quale frequenza un amminoacido si trova mutato in un altro amminoacido all’interno delle sequenze proteiche → i valori di frequenza osservati sono infatti proporzionali alla probabilità che l’aai muti nell’aaj (ciò viene calcolato per tutte le coppie di aa possibili) e quindi la frequenza osservata viene sfruttata come misura di similarità tra coppie di amminoacidi. Tuttavia bisogna sempre tenere conto del fatto che il numero di differenze che sono osservate tra due sequenze non è per forza uguale alla distanza evolutiva presente tra le due sequenze, e questo perché:
- c’è una certa probabilità che un residuo possa essere mutato e poi revertito mascherando la mutazione; Alifatici non polari o Glicina (Gly,G) o Alanina (Ala, A) o Valina (Val, V) o Leucina (Leu, L) o Isoleucina (Ile, I) o Metionina (Met, M) Polari non carichi o Serina (Ser, S) o Treonina (Thr, T) o Cisteina (Cys, C) o Prolina (Pro, P) o Asparagina (Asn, N) o Glutammina (Gln, Q) Carichi positivamente o Lisina (Lys, K) o Arginina (Arg, R) o Istidina (His, H) Carichi negativamente o Aspartato (Asp, D) o Glutammato (Glu, E) Aromatici o Fenilalanina (Phe, F) o Tirosina (Tyr, Y) o Triptofano (Trp, W) Idrofobici o Glicina (Gly, G) o Alanina (Ala, A) o Valina (Val, V) o Leucina (Leu, L) o Isoleucina (Ile, I) o Prolina (Pro, P) o Fenilalanina (Phe, F) AA aromatici o Tirosina (Trp, Y) o Triptofano (Trp, W) Idrofilici e anfipatici Con gruppo OH o Serina (Ser, S) o Treonina (Thr, T) o Tirosina (Tyr, Y) AA acidi o Aspartato (Asp, D) o Glutammato (Glu, E) AA con gruppi amidici o Asparagina (Asn, N) o Glutammina (Gln, Q) AA che contengono S o Cisteina (Cys, C) o Metionina (Met, M) AA basici o Lisina (Lys, K) o Arginina (Arg, R) Altri AA carichi positivamente o Istidina (His, H)
Per il calcolo del punteggio di similarità però si preferisce non utilizzare direttamente la matrice di sostituzione, ma piuttosto utilizzare la corrispondente MATRICE DI PUNTEGGIO che è anche detta LOG-ODDS MATRIX. Ogni cella di una matrice di punteggio consiste in un “ odds ratio ” che viene poi convertito in logaritmo: log 𝑝𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡à 𝑐ℎ𝑒 𝑢𝑛𝑎 𝑠𝑜𝑠𝑡𝑖𝑡𝑢𝑧𝑖𝑜𝑛𝑒 𝑠𝑖𝑎 𝑎𝑢𝑡𝑒𝑛𝑡𝑖𝑐𝑎 𝑝𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡à 𝑐ℎ𝑒 𝑢𝑛𝑎 𝑠𝑜𝑠𝑡𝑖𝑡𝑢𝑧𝑖𝑜𝑛𝑒 𝑠𝑖𝑎 𝑑𝑜𝑣𝑢𝑡𝑎 𝑎𝑙 𝑐𝑎𝑠𝑜 codoni (es. leucina), mentre altri amminoacidi sono codificati da un singolo codone, la probabilità che si venga a formare sul DNA casualmente quello specifico codone è più basso e quindi la frequenza attesa nelle proteine di quell’amminoacido (es. metionina e triptofano) è più bassa. La frequenza attesa è diversa per ogni amminoacido, in blu sono indicati gli amminoacidi che sono codificati da 6 codoni, mentre in rosso gli amminoacidi che sono codificati da 1 solo codone. Non solo però la matrice di punteggio è preferita perché tiene conto delle frequenze osservate degli amminoacidi (o delle probabilità di avere una sostituzione random nel caso dei nucleotidi), ma anche perché dato che si utilizza il log-odds, si può sfruttare la probabilità dei logaritmi di sommare per calcolare i punteggi di similarità, mentre se si dovesse tenere conto delle probabilità saprebbe necessario moltiplicare tra loro le probabilità. È invece più facile l’interpretazione del logaritmo del rapporto:
- se il risultato è > 0 allora significa che la probabilità che l’aai venga convertito nell’aaj per una autentica mutazione [ gli aa sono uguali perché le sequenze sono omologhe, oppure gli aa sono sostituiti perché la mutazione è accettata dalla selezione ] è maggiore della probabilità che la sostituzione sia dovuta al caso (quindi ci troviamo nel caso di mutazioni che sono state “accettate” dalla selezione);
- se il risultato è < 0 significa che la probabilità che la sostituzione dell’aai nell’aaj per una autentica mutazione è minore della probabilità che la sostituzione sia dovuta al caso (quindi ci troviamo nel caso di mutazioni che non sono ben tollerate dalla selezione) → quindi è più probabile pensare che la sostituzione sia dovuta al caso, le sequenze non sono omologhe tra loro;
- se il risultato è = 0 significa che la probabilità che la sostituzione amminoacidica sia dovuta ad una autentica mutazione è uguale alla probabilità che la sostituzione sia avvenuta per caso. Partendo dalle matrici di sostituzione PAM si ottengono quindi delle matrici di punteggio Log-odds PAM. Le Log-odds PAM hanno la proprietà di essere simmetriche, e i valori che sono riportati nella matrice esprimono il rapporto tra le probabilità di sostituzione date dall'evoluzione e le probabilità di sostituzione date dal caso. Gli amminoacidi vengono considerati simili quando il loro punteggio di sostituzione è positivo. In questa tipologia di matrice gli amminoacidi sono riportati in modo ordinato a seconda delle loro caratteristiche chimico-fisiche. L’odds è concettualmente diverso dalla probabilità: l’odds esprime il rapporto tra il numero di volte in cui un evento si è verificato rispetto al numero di volte in cui un evento non si è verificato; mentre la probabilità è il numero di volte in cui un evento si è verificato rispetto al numero di eventi possibili. L’odds ratio è il rapporto tra gli odds di un primo gruppo rispetto agli odds di un secondo gruppo e ha lo scopo di confrontare gli odds di due gruppi. Viene quindi introdotto il concetto di probabilità dovuta al caso e di probabilità di sostituzione autentica: mentre per i nucleotidi abbiamo una probabilità di 1/4 che un nucleotide si trovi in quella posizione per caso; per gli amminoacidi non sarebbe corretto considerare che si ha una probabilità di 1/ che si trovino per caso all’interno di una proteina. Infatti alcuni amminoacidi sono più frequenti all’interno delle proteine, mentre altri sono più rari, e questo può dipendere banalmente anche dal fatto che alcuni amminoacidi sono codificati da più
Vediamo ad esempio una matrice Log-odds PAM250: Possiamo ad esempio notare dalla Log-odds PAM250 che l’amminoacido che presenta il punteggio più elevato quando un amminoacido non subisce sostituzioni è il triptofano, che presenta punteggio 17. Questo è dovuto al fatto che il triptofano è uno degli amminoacidi più rari, quindi se si trova presente all’interno di una sequenza proteica probabilmente svolge una funzione ben precisa. Un'altra matrice di sostituzione molto utilizzata è la matrice BLOSUM – BLOck SUbstitution Matrix , così chiamata in quanto questa matrice è stata derivata dall’osservazione di allineamenti locali e non globali (a differenza della precedente PAM). Più precisamente questa matrice è stata creata nel 1992 da Steven e Jorja Henikoff utilizzando per il database BLOCKS, un database secondario che presenta allineamenti (privi di gaps) di sequenze proteiche corrispondenti a regioni molto conservate in diverse famiglie proteiche. All’interno del database BLOCKS sono state contante le frequenze relative degli amminoacidi e le probabilità corrispondenti alla sostituzione di ogni coppia di amminoacidi. Sono quindi stati osservati direttamente gli allineamenti di blocchi conservati che presentassero:
- almeno il 45% di identità di sequenza → dando origine alla matrice BLOSUM45;
- almeno il 62% di identità di sequenza → dando origine alla matrice BLOSUM62 [ la matrice di default utilizzata dall’algoritmo BLAST in NCBI per l’allineamento di sequenze proteiche ];
- almeno l’80% di identità di sequenza → dando origine alla matrice BLOSUM80. Esistono però anche matrici BLOSUM 50 e 90 [ disponibili per BLAST ], il numero identifica sempre la percentuale di identità tra le sequenze comparate su cui è stata creata la matrice. Tutte le matrici BLOSUM sono quindi derivanti dall’osservazione diretta di allineamenti, al contrario delle matrici PAM in cui solo la PAM1 era derivante da un’osservazione diretta di allineamenti di sequenze di proteine strettamente correlate.