Scarica Econometria spiegata facile e più Dispense in PDF di Macroeconomia solo su Docsity!
MODELLI ECONOMETRICI
Guida Completa, Approfondita e Semplificata — Versione Definitiva
Andrea Ichino
Regressione Lineare Semplice · Test di Ipotesi · Regressione Multipla
📖 COME USARE QUESTO DOCUMENTO
Ogni argomento segue lo stesso schema in 4 livelli progressivi:
🎓 CAPISCILO COSÌ — analogia di vita quotidiana, niente matematica.
🎓 INTUIZIONE — la logica del concetto in parole semplici.
🎓 VERSIONE TECNICA — definizioni formali, dimostrazioni, simboli spiegati.
🎓 ESEMPIO CALIFORNIANO — tutti i dati reali del PDF.
🎓 FORMULA — in riquadro giallo con ogni simbolo etichettato.
🎓 TERMINE — ogni volta che appare un termine statistico nuovo, viene spiegato in un
riquadro viola prima di usarlo.
GUIDA AI SIMBOLI USATI NEL DOCUMENTO:
β ₀ β ₁ β ₂ = parametri VERI della popolazione (intercetta e pendenze)
β̂ = stime OLS calcolate dal campione ("cappello" = stimato)
₀ β̂
₁ β̂
σ² = varianza (quadrato della deviazione standard)
σ²_X = varianza di X nella popolazione
σ²_u = varianza degli errori u nella popolazione
σ_X = deviazione standard di X
ρ_Xu = correlazione tra X e u
μ_X μ_Y = medie di X e Y nella popolazione
X̄ = medie campionarie di X e Y (calcolate dai dati)
Ŷ ᵢ = valore predetto dalla retta per l'osservazione i
û ᵢ = residuo OLS per l'osservazione i
R̄ ² = R² corretto (aggiustato)
χ²_q = distribuzione chi-quadro con q gradi di libertà
ν ᵢ = prodotto (X − μ_X)·u (usato nelle derivazioni)ᵢ ᵢ
plim = limite in probabilità (per n → ∞)
Σ = sommatoria (somma su tutti gli i)
📖 ESEMPIO CALIFORNIANO: Il dataset di partenza
Dati: 420 distretti scolastici della California. Per ogni distretto osserviamo:
STR (Student-Teacher Ratio) = numero medio di studenti per insegnante nel distretto
TestScore = punteggio medio al test standardizzato di lettura e matematica
el_pct = percentuale studenti non anglofoni
meal_pct = percentuale che riceve pasto gratuito (proxy del reddito basso)
avginc = reddito medio familiare
expn_stu = spesa scolastica per alunno
La domanda: assumere nuovi insegnanti (riducendo STR di 1 unità) porta a quanti
punti in più al TestScore in media?
1.1 Le due domande fondamentali del corso
Domanda Tipo Esempio concreto Obiettivo
Q1: Qual è l'effetto
CAUSALE di X su Y?
Inferenza
causale
Ridurre STR di 1 → quanti
punti in più al test?
PRINCIPALE
Q2: Come
PREVEDERE Y dato
X?
Previsione Dato STR=21, quale
TestScore aspettarmi?
Secondario
⚠️� ATTENZIONE: Q1 e Q2 richiedono ipotesi diverse
Per la PREVISIONE (Q2) basta che X e Y siano correlati. Non importa se la relazione è
causale.
Per la CAUSALITÀ (Q1) serve molto di più: devo essere sicuro che la variazione di X
CAUSI la variazione di Y, e non entrambe siano causate da un terzo fattore nascosto.
Il professore dice esplicitamente: ci concentriamo principalmente su Q1.
SEZIONE 2 · IL PREDITTORE LINEARE OTTIMALE
(BLP)
2. Il Predittore Lineare Ottimale (BLP)
Prima di stimare qualcosa dai dati, dobbiamo chiederci: nell'universo ideale della
POPOLAZIONE, quale sarebbe la MIGLIORE retta possibile per approssimare Y usando X?
Questa retta si chiama BLP (Best Linear Predictor).
📖 TERMINE: Popolazione vs Campione
POPOLAZIONE = l'insieme di TUTTI gli oggetti che ci interessano, inclusi quelli che
non abbiamo osservato. È un concetto ideale e astratto.
CAMPIONE = il sottoinsieme che abbiamo effettivamente osservato e misurato.
Esempio: la popolazione sono tutti i distretti scolastici californiani. Il campione sono i
420 distretti per cui abbiamo dati.
I parametri della POPOLAZIONE (β , β ) sono fissi ma ignoti. Le stime del CAMPIONE₀ ₁
( β̂ , ) le calcoliamo dai dati.
₀ β̂
📖 CAPISCILO COSÌ: Cosa significa "migliore retta"
Immagina di dover tracciare una retta su un foglio pieno di punti, dove ogni punto è un
distretto (posizione orizzontale = STR, altezza = TestScore). Vuoi la retta che "sbaglia
meno" nel rappresentare tutti i punti.
Come misuri "sbagliare"? Guardi la distanza VERTICALE di ogni punto dalla retta, la
elevi al quadrato (per penalizzare di più gli errori grandi e rendere tutto positivo), e
sommi tutto. La retta migliore è quella che minimizza questa somma.
Questo si chiama CRITERIO DEI MINIMI QUADRATI ed è il cuore di tutta la
regressione lineare.
📖 TERMINE: Valore Atteso E[...]
Il valore atteso di una variabile casuale è la sua MEDIA nella popolazione. Si indica con
E[X] o E(X).
È come la media aritmetica, ma calcolata sull'intera popolazione (non solo sul
campione).
📖 TERMINE: Varianza e Deviazione Standard
La VARIANZA misura quanto i valori di una variabile sono dispersi attorno alla loro
media.
Var(X) = σ²_X = media del quadrato delle distanze dalla media
La DEVIAZIONE STANDARD è la radice quadrata della varianza: σ_X = √Var(X)
Ha la stessa unità di misura della variabile originale (la varianza è in unità al quadrato).
Esempio: se i punteggi al test hanno media 654 e deviazione standard 19, vuol dire che
la maggior parte dei distretti sta tra 654−19=635 e 654+19=673.
📖 TERMINE: Covarianza
La covarianza misura quanto due variabili si muovono INSIEME. Si indica con
Cov(Y,X) o σ_YX.
Cov(Y,X) > 0: quando X aumenta, Y tende ad aumentare
Cov(Y,X) < 0: quando X aumenta, Y tende a diminuire
Cov(Y,X) = 0: nessun legame lineare
La covarianza dipende dall'unità di misura delle variabili. Per confrontare, si normalizza
→ correlazione.
₁ CAPISCILO COSÌ: Perché β📖 = Cov/Var? Un esempio intuitivo
La covarianza Cov(Y,X) misura quanto Y e X si muovono insieme. Se quando STR
aumenta di 1 unità TestScore tende a scendere di 5 punti, la covarianza è negativa.
Ma la covarianza dipende anche da quanto è variabile X. Se tutti i distretti hanno quasi
lo stesso STR (varianza piccola), anche una covarianza grande non ci dice molto sulla
PENDENZA della relazione.
Dividere la covarianza per la varianza di X "normalizza" questa dipendenza: β ₁dice
"per ogni UNITÀ di variazione in X, quanto varia Y in media". È esattamente la
pendenza della retta.
Esempio numerico: Cov(TestScore, STR) ≈ −11.4, Var(STR) ≈ 5.0, quindi β ₁ =
−11.4/5.0 = −2.28. Ogni studente in più per insegnante è associato a 2.28 punti in
meno al test.
2.3 La scomposizione di Y in parte spiegata e parte non spiegata
Y = (β ₀ + β ₁·X) + u
(1) = la parte di Y che la retta riesce a spiegare usando X
(2) = la parte di Y che NON riesce a spiegare (errore di
approssimazione u)
📖 VERSIONE TECNICA: Le proprietà automatiche dell'errore u del BLP
Le condizioni del primo ordine (derivate = 0) del problema BLP implicano
automaticamente:
PROPRIETÀ 1: E(u) = 0
PROPRIETÀ 2: Cov(u, X) = 0
DIMOSTRAZIONE di E(u) = 0:
E(u) = E(Y − β ₀ − β ·X) = E(Y) − β₁ ₀ − β ·E(X)₁
= E(Y) − [E(Y)−β ·E(X)] − β ·E(X) = 0₁ ₁ ✓
IMPORTANTE: queste proprietà NON sono ipotesi aggiuntive. Sono conseguenze
matematiche della costruzione del BLP. Non bastano però per l'interpretazione
causale: serve la MIA più forte.
📖 ESEMPIO CALIFORNIANO: Il BLP per TestScore e STR
Nella popolazione californiana (ideale):
Cov(TestScore, STR) ≈ −11.
Var(STR) ≈ 5.
β ₁= −11.4 / 5.0 = −2.28 (pendenza vera nella popolazione)
β ₀ = μ_Y − β ·μ_X ≈ 654 + 44.9 = 698.9 (intercetta vera)₁
Questi sono i valori VERI nella popolazione. Non li conosciamo: li stimiamo con l'OLS
(Sezione 6).
📖 CAPISCILO COSÌ: Cosa c'è dentro l'errore u?
L'errore u NON è un "errore di misurazione" o uno sbaglio. È la parte di Y che X da solo
non riesce a spiegare. Include TUTTI gli altri fattori che influenzano Y e che non sono
nel modello.
Nel modello TestScore = β ₀ + β ·STR + u, all'interno di u ci sono: il reddito medio delle₁
famiglie, la percentuale di studenti non anglofoni, la qualità degli insegnanti, le
opportunità di apprendimento extrascolastiche, il coinvolgimento dei genitori, e molti
altri fattori.
L'errore u varia da distretto a distretto perché ogni distretto è unico nei suoi fattori non
osservati.
SEZIONE 4 · LA MIA: QUANDO β ₁È UN EFFETTO
CAUSALE
4. L'Ipotesi di Indipendenza in Media (MIA)
Abbiamo il modello Y = β ₀ + β ·X + u. La domanda cruciale è: β₁ ₁misura davvero l'effetto
CAUSALE di X su Y? La risposta dipende da un'ipotesi fondamentale chiamata MIA (Mean
Independence Assumption), in italiano Ipotesi di Indipendenza in Media.
📖 CAPISCILO COSÌ: Perché Cov(u,X) = 0 non basta per la causalità
Già sappiamo (dalla costruzione del BLP) che Cov(u,X) = 0. Sembra una buona
notizia: u e X non sono correlati linearmente.
Ma correlazione zero lineare non significa indipendenza! Pensa a u = X² (una
parabola). Se X è simmetrico attorno allo zero, Corr(u, X) = 0, ma u dipende
FORTEMENTE da X in modo non lineare.
Se u dipende da X in modo non lineare, quando X cambia, u cambia in media in modo
non casuale. Questo inquinerebbe la nostra stima dell'effetto causale di X su Y.
Per la causalità serve qualcosa di più forte: la media di u deve essere zero per OGNI
valore di X.
MIA (Mean Independence Assumption):
E(u | X) = 0
Lettura: "Il valore atteso di u, dato qualsiasi valore di X, è
sempre zero"
Questo è più forte di: E(u) = 0 [solo la media
globale è zero]
E più forte di: Cov(u, X) = 0 [solo la relazione
lineare è zero]
📖 VERSIONE TECNICA: La gerarchia logica delle tre ipotesi
Il reddito alto è in u e influenza positivamente TestScore.
Quindi E(u | STR basso) > 0. La MIA è violata!
Conseguenza: β̂ = −2.28 non misura l'effetto causale puro di STR.
Assorbe anche parte dell'effetto positivo del reddito correlato con STR basso.
Soluzione: includere il reddito nel modello → Regressione Multipla (Sezione 15).
SEZIONE 5 · LA FUNZIONE DI REGRESSIONE DELLA
POPOLAZIONE (PRF)
5. La Funzione di Regressione della Popolazione
(PRF)
📖 CAPISCILO COSÌ: La PRF in parole semplici
La PRF risponde a: per ogni valore di X, qual è la MEDIA di Y in tutta la popolazione?
Per tutti i distretti con STR = 20, qual è il TestScore medio? Per STR = 21? Per STR =
22? La curva che passa per tutte queste medie condizionali è la PRF.
La PRF non dice il TestScore ESATTO di ogni distretto. Dice il TestScore MEDIO dei
distretti con un certo STR. I singoli distretti si discostano dalla PRF per via dei fattori in
u.
5.1 Derivazione della PRF sotto la MIA
E(Y|X) = E(β ₀ + β ₁·X + u | X)
= β ₀ + β ₁·X + E(u|X)
SOTTO LA MIA [E(u|X) = 0]:
E(Y|X) = β ₀ + β ₁·X
Risultato fondamentale: sotto la MIA, la PRF è esattamente una retta con pendenza β ₁ e
intercetta β. Il BLP coincide con la vera media condizionale E(Y|X).₀
₁ VERSIONE TECNICA: Dimostrazione che β📖 è l'effetto causale
Consideriamo due valori di X: x e x + Δx (dove Δx è una piccola variazione):
E(Y | X = x) = β ₀ + β ·x₁
E(Y | X = x + Δx) = β ₀ + β ·(x + Δx)₁
SEZIONE 6 · LO STIMATORE OLS
6. Lo Stimatore OLS (Minimi Quadrati Ordinari)
Finora abbiamo parlato di β ₀ e β ₁nella popolazione. Sono numeri veri ma ignoti. Ora dobbiamo
stimarli usando i dati del campione di n osservazioni. Lo strumento è lo stimatore OLS.
📖 TERMINE: Stimatore
Uno STIMATORE è una formula matematica che, applicata ai dati di un campione,
produce una stima di un parametro ignoto della popolazione.
β̂ (beta con il "cappello") è lo STIMATORE OLS di β. Il "cappello" ˆ indica sempre
che si tratta di una stima calcolata dai dati, non del valore vero.
β ₁ (senza cappello) è il parametro VERO nella popolazione. Ignoto. Quello che
vogliamo stimare.
Come la temperatura di una stanza: il termostato (stimatore) mostra una stima; la vera
temperatura è quella effettiva (parametro vero).
📖 CAPISCILO COSÌ: La logica dell'OLS: trovare la retta che "sbaglia
meno"
Hai 420 punti su un grafico (asse orizzontale = STR, verticale = TestScore). Vuoi
trovare la retta che passa "il più vicino possibile" a tutti i 420 punti.
"Vicino" si misura con la distanza VERTICALE di ogni punto dalla retta. Questa
distanza si chiama RESIDUO: quanto sbaglia la retta nel prevedere il TestScore di quel
distretto.
L'OLS trova la retta che minimizza la SOMMA DEI QUADRATI dei residui. Stesso
principio del BLP nella popolazione, ma con i dati del campione.
6.1 Il problema di minimizzazione OLS
Dati n osservazioni (X ₁,Y ₁), (X ₂,Y ₂), ..., (X ₙ,Y ₙ):
min Σ ᵢ [ Y ᵢ − (b ₀ + b ₁·X ᵢ) ]² rispetto a b ₀ e b₁
dove Σ ᵢ = somma da i=1 a n
e Y ᵢ − (b ₀ + b ₁·X ᵢ) = distanza verticale tra il punto i e la
retta
6.2 Formule esplicite degli stimatori OLS
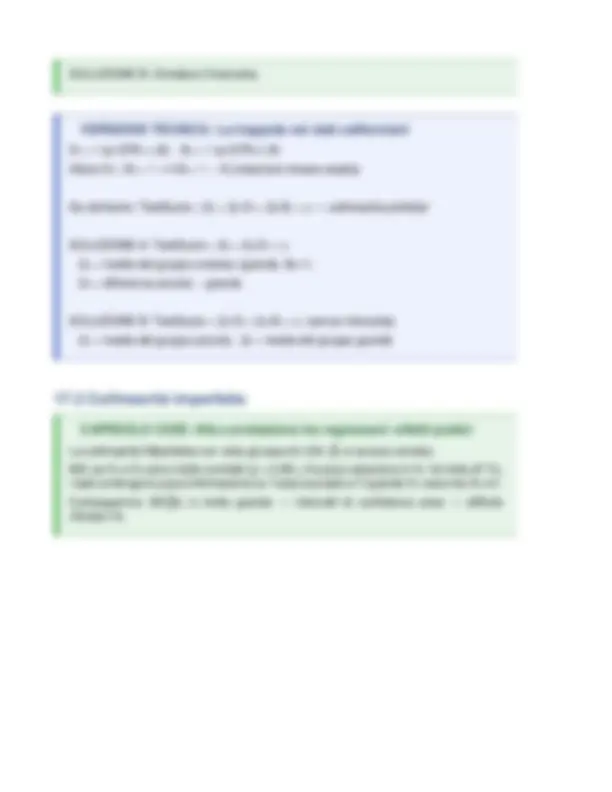
β̂�₁ = Σ ᵢ(X ᵢ − X̄ )(Y ᵢ − Ȳ) / Σ ᵢ(X ᵢ − X̄ )²
β̂�₀ = Ȳ − β̂�₁ · X̄
dove:
X̄ = (1/n) · Σ ᵢ X ᵢ = media campionaria di X
Ȳ = (1/n) · Σ ᵢ Y ᵢ = media campionaria di Y
Σ ᵢ = somma su tutti i i da 1 a n
β̂� = la "cappello" (ˆ) indica stima calcolata dal campione
📖 VERSIONE TECNICA: Derivazione dalle condizioni del primo ordine
Derivando Σ [Y − bᵢ ᵢ ₀ − b ·X ]² rispetto a b₁ ᵢ ₀ e b ₁e ponendo le derivate = 0:
∂/∂b : Σ (Y − b₀ ᵢ ᵢ ₀ − b ·X ) = 0₁ ᵢ ⟹ Σ û = 0ᵢ ᵢ ⟹ Ȳ = β̂ + ·
₀ β̂
₁ X̄
∂/∂b : Σ (Y − b₁ ᵢ ᵢ ₀ − b ·X )·X = 0₁ ᵢ ᵢ ⟹ Σ û ·X = 0ᵢ ᵢ ᵢ
Risolvendo il sistema di 2 equazioni in 2 incognite si ottengono β̂ e.
₀ β̂
La formula di β̂ è l'analogo CAMPIONARIO del BLP nella popolazione:
BLP: β ₁= Cov(Y,X) / Var(X)
OLS: β̂ = covarianza campionaria(Y,X) / varianza campionaria(X)
6.3 Valori predetti e residui OLS
Valore predetto: Ŷ ᵢ = β̂�₀ + β̂�₁·X ᵢ
(cosa prevede la retta stimata per ogni osservazione)
Residuo OLS: û ᵢ = Y ᵢ − Ŷᵢ
β̂ = 698.9: il TestScore stimato per STR = 0 sarebbe 698.9.
Ma STR = 0 è impossibile (non ci sono classi senza studenti!)
→ L'intercetta NON ha significato economico in questo caso.
ESEMPIO SPECIFICO — Distretto di Antelope, CA:
Dato osservato: STR = 19.33, TestScore = 657.
Valore predetto: Ŷ = 698.9 − 2.28 · 19.33 = 698.9 − 44.1 = 654.
Residuo: û = 657.8 − 654.8 = +3.
Il residuo di +3 significa: Antelope va 3 punti MEGLIO di quanto prevede la retta.
Ci sono fattori positivi non catturati da STR che favoriscono questo distretto.
SEZIONE 7 · BONTÀ DI ADATTAMENTO: R², SER,
RMSE
7. Misure di adattamento: quanto bene la retta
spiega i dati?
Dopo aver stimato la retta, vogliamo capire quanto è buona. Due misure complementari: R²
(percentuale di variabilità spiegata, senza unità di misura) e SER (dimensione media dell'errore,
nella stessa unità di Y).
7.1 La scomposizione della varianza: TSS = ESS + SSR
📖 CAPISCILO COSÌ: L'idea della scomposizione
Ogni valore osservato Y si discosta dalla mediaᵢ Ȳ. Questa discostanza totale (TSS) si
può decomporre in due parti:
Parte SPIEGATA (ESS): quanto la RETTA si discosta dalla media.
Parte RESIDUA (SSR): quanto i punti si discostano dalla RETTA.
Se ESS = TSS (SSR = 0), la retta passa per tutti i punti perfettamente. Se ESS = 0
(SSR = TSS), la retta è orizzontale e X non aiuta per niente.
📖 TERMINE: TSS, ESS, SSR: le tre somme dei quadrati
TSS (Total Sum of Squares) = Σ (Y −ᵢ ᵢ Ȳ)² = variabilità TOTALE di Y
ESS (Explained Sum of Squares) = Σ (Ŷ −ᵢ ᵢ Ȳ)² = variabilità SPIEGATA dalla retta
SSR (Sum of Squared Residuals) = Σ û ²ᵢ ᵢ = variabilità NON spiegata
"SS" sta per "Sum of Squares" = Somma dei Quadrati.
La relazione fondamentale: TSS = ESS + SSR (sempre vera con intercetta nel
modello).
TSS = ESS + SSR
TSS = Σ ᵢ(Y ᵢ − Ȳ)² = variabilità totale di Y
ESS = Σ ᵢ(Ŷ ᵢ − Ȳ)² = variabilità spiegata dalla retta OLS