Scarica Informatica di base (Lettere) e più Dispense in PDF di Fondamenti di informatica solo su Docsity!
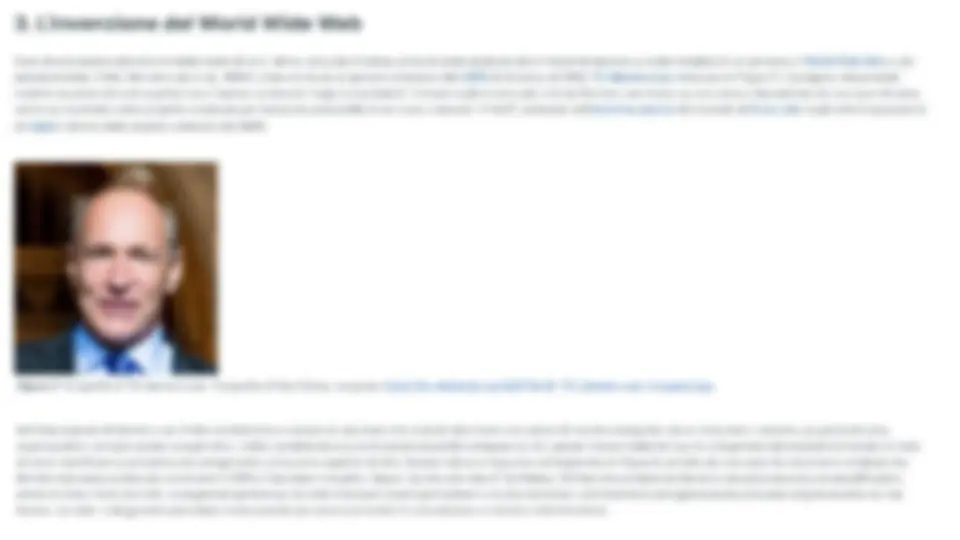
1, Introduzione In questo capitolo e nei successivi affronteremo tutte le tecnologie alla base di Internet e del World Wide Web. Tuttavia, invece di affrontare questi temi in modo tradizionale, ovvero partendo dalla descrizione architetturale di Internet per poi presentare il Web, abbiamo voluto introdurre questi argomenti seguendo la traccia fornita da Tim-Berners Lee (l'inventore del Web) in un noto documento esplicativo a disposizione sul suo sito Web. In particolare, questo capitolo ed i successivi quattro, nella loro interezza, permettono di rispondere ad una semplice, seppur significativa, domanda: e Cosa succede quando si clicca su un collegamento ipertestuale (o link) di una pagina Web? Per rispondere pienamente a questa domanda, è necessario avere delle conoscenze di base relative sia sul come l'informazione viene trasmessa digitalmente, sia sulle componenti che compongono Internet e il Web. In particolare, la narrazione qui presentata segue sistematicamente i vari passi che vengono eseguiti da tutti gli attori coinvolti non appena viene eseguito un “click” su un collegamento ipertestuale di una pagina web. 2. La nascita degli ipertesti Tuttavia, prima di concentrarci sulla descrizione della sequenza di azioni che viene scatenata a seguito di un “click”, è bene chiarire cosa sia un ipertesto e, conseguentemente, cosa sia un collegamento ipertestuale. Un ipertesto è un corpo di materiale scritto interconnesso in modo così tanto complesso che non è conveniente presentare su carta [Nelson, 1965]. Seppur, al giorno d'oggi, siamo abituati ad utilizzare questo tipo di strumento, essendo il Web di fatto un gigantesco ipertesto, una settantina di anni fa quest'idea era praticamente non convenzionale e non realizzabile. L'idea embrionale dell'ipertesto sembra sia stata affrontata ben prima della sua proposta formale, essendovi diversi riferimenti già in letteratura a possibili costruzioni prettamente ipertestuali — ad esempio, si veda il racconto “Il giardino dei sentieri che si biforcano” di Jorge Luis Borges. Tuttavia, l'idea di una esemplificazione tecnologica si ha soltanto nel 1945, a seguito delle riflessioni contenute nel famoso articolo “As We May Think” di Vannevar Bush [Bush, 1945]. Se Figura 1. Fotografia di Vannevar Bush. Sorgente: https://en.wikipedia.org/wiki/File:Vannevar_Bush_portrait.jpg. Figura 2. L'illustrazione originale del memex proposto da Vannevar Bush. Sorgente: https://history-computer.com/Internet/Dreamers/Bush.html. Nel suo articolo, Bush presentava, in linea totalmente teorica, una macchina chiamata memex (mostrata in Figura 2) che avrebbe permesso di salvare tutti i libri, record di dati, e comunicazioni di vario genere su dispositivi appropriati, così da accedervi in modo completamente meccanico, flessibile, e veloce. In particolare, il memex era composto da una scrivania con due schermi al centro per facilitare la lettura dei documenti memorizzati, accompagnati da una tastiera, un insieme di bottoni e leve (a destra), e, sulla sinistra, una plancia su cui posizionare qualunque documento così da essere fotografato e memorizzato nei microfilm utilizzati dalla macchina. Tutte le informazioni memorizzate (ad esempio, un libro) potevano, ovviamente, essere recuperate mediante il classico meccanismo a indici descritto sopra, e consultate attraverso l'uso delle leve messe a disposizione dalla macchina, che permettevano di sfogliare sequenzialmente documenti. Inoltre, la macchina metteva a disposizione anche un meccanismo per annotare i documenti visualizzati, così da aggiungere note a margine, commenti, e quant'altro. In aggiunta a questo, il più grande vantaggio che il memex avrebbe introdotto era la possibilità di creare percorsi tra le informazioni, ovvero dei collegamenti associativi tra le varie porzioni di informazioni memorizzate nel memex. In particolare, un utente avrebbe potuto creare uno specifico percorso associativo e memorizzarlo nella macchina con un nome, così da poterlo richiamare ed estendere in futuro. In questo caso, il memex avrebbe permesso non solo di spostarsi sequenzialmente sul documento visualizzato, ma anche trasversalmente su diversi documenti seguendo tutti i percorsi associativi che un utente avrebbe potuto creare. Infine, avrebbe anche potuto salvare il percorso in uno specifico microfilm così da poterlo condividere con un collega, che avrebbe potuto visualizzarlo nel suo memex. Le idee contenute nell'articolo di Vannevar Bush erano visionarie e d'avanguardia per l'epoca, e alcune di queste rappresentano ancora dei possibili desiderata dello sviluppo degli ipertesti e, più in generale, del Web. Molti ingegneri e inventori sono stati ispirati da quest'articolo nel corso degli anni successivi. Tra questi è bene ricordare Theodor (Ted) Holm Nelson (mostrato în Figura 3), colui che ha coniato la parola ipertesto. Figura 3. Fotografia di Theodor Nelson scattata presso il Tech Museum of Innovation il 19 Febbraio 2011. Fotografia di Dgies, sorgente: https://en.wikipedia.org/wiki/File:Ted_Nelson_cropped.jpg. Nello stesso periodo in cui Nelson divulgava le sue idee e il suo progetto, un altro scienziato, Douglas Engelbart (mostrato in Figura 5), aveva iniziato l'implementazione di un sistema rivoluzionario per l'epoca, che di fatto permetteva per la prima volta la creazione di ipertesti su un computer. Questo sistema, chiamato oN-Line System (NLS) ebbe un impatto dirompente sullo stato corrente e futuro delle tecnologie informatiche che erano a disposizione all'epoca. Basti pensare le innovazioni software (le applicazioni e i programmi a disposizione di un computer) e hardware (ovvero la parte fisica e tangibile di un computer, come il processore, il disco fisso, la memoria RAM, etc.) che lo sviluppo dell’NLS aveva portato: il concetto di finestre come meccanismo visuale per l'organizzazione di contenuti e applicazioni di un sistema operativo, l’ipertesto, un sistema di videoconferenza, il mouse (mostrato in Figura 6), un sistema di videoscrittura (o word processor in inglese, tipo Microsoft Word), un meccanismo (chiamato dynamic linking) per richiedere solo quando necessario opportune librerie e applicazioni a disposizione sul computer, meccanismi per il controllo delle versioni dei documenti, e un editor collaborativo in tempo reale (tipo Google Docs). Tutte queste cose non esistevano prima di NLS, e sono da li in avanti state il fondamento per lo sviluppo dei moderni computer e sistemi operativi. Figura 6. ll primo prototipo di mouse creato da Bill English, seguendo le bozze di Douglas Engelbart. Fotografia di SRI International, sorgente: https://en.wikipedia.org/wiki/File:SRI_Computer_Mouse.jpg. L'intero sistema, implementato realmente da Engelbart e soci, era stato per la prima volta mostrato in una famosa sessione dimostrativa nella Fall Joint Computer Conference del 1968, organizzata dalla Association for Computing Machinery e dall’Institute of Electrical and Electronics Engineers (le due principali associazioni internazionali accademiche di informatica), suscitando commenti entusiastici da parte di tutta la comunità, tanto da aver poi etichettato quella sessione come la madre di tutti i demo (The Mother Of All Demos, in inglese). 3. L'invenzione del World Wide Web Sono dovuti passare diversi anni dalla madre di tutti i demo, poco più di trenta, prima di poter assistere ad un'implementazione su scala mondiale di un ipertesto, il World Wide Web o, più semplicemente, il Web [Berners-Lee et al., 1994]. L'idea venne ad un giovane scienziato del CERN di Ginevra nel 1989, Tim Berners-Lee (mostrato in Figura 7). Il progetto, inizialmente respinto da parte dei suoi superiori con il famoso commento “vago ma eccitante”, ritrovato qualche anno più tardi da Berners-Lee stesso su una copia a disposizione del suo capo di allora, venne poi accettato come progetto collaterale per testare le potenzialità di un nuovo computer (il NeXT, realizzato dall'omonima azienda di proprietà di Steve Jobs negli anni di separazione da Apple) che era stato appena comprato dal CERN. a Figura 7. Fotografia di Tim Berners-Lee. Fotografia di Paul Clarke, sorgente: https://en.wikipedia.org/wiki/File:Sir_Tim_Berners-Lee_{cropped).jpg. Nell'idea originale di Berners-Lee, il Web avrebbe dovuto essere un ipertesto che potesse descrivere una varietà di risorse eterogenee, tra cui documenti, persone, gruppi di persone, organizzazioni, concetti astratti, e quant'altro. Inoltre, sarebbe dovuto anche essere possibile collegare tra loro queste risorse mediante l'uso di collegamenti ipertestuali etichettati, in modo da poter specificare la semantica del collegamento come parte esplicita del link. Questa visione è riassunta nel diagramma in Figura 8, estratto da una copia del documento originale che Berners-Lee aveva scritto per convincere il CERN a finanziare il progetto. Seppur ispirato alle idee di Ted Nelson, l'infrastruttura ideata da Berners-Lee proponeva alcune semplificazioni, prima tra tutte il fatto che tutti i collegamenti ipertestuali del Web dovessero essere percorribili in un'unica direzione, contrariamente all'organizzazione postulata originariamente da Ted Nelson, ove tutti i collegamenti ipertestuali erano pensati per essere percorribili in una direzione o nell'altra indistintamente. 4. Uniform Resource Locator (URL) Quando si legge una pagina web, il computer non mostra tutto quello che conosce sui link ipertestuali presenti in quella pagina. Dentro quel frammento di testo sottolineato e solitamente colorato in blu (o in viola, nel caso sia stato già visitato) che può essere cliccato, c'è nascosto un oggetto invisibile che inizia per “http://" (0, a volte, “https://“, dipendentemente dai casi). Quell'oggetto è un Uniform Resource Locator, o URL. Un URL rappresenta, di fatto, una sorta di nome (o più propriamente, un indirizzo) della pagina web a cui il link punta e permette di accedere cliccandoci sopra. Per esempio, la pagina web su Wikipedia che parla di URL presentata nel link precedente è identificata dall'URL http:/fit.wikipedia.org/wiki/Uniform_Resource_Locator. In generale, la forma di un qualunque URL presente nel Web è conforme con la seguente struttura (ove gli elementi tra parentesi quadre sono opzionali):
://[:][/][?][#] Le varie parti sono descritte come segue — e verranno approfondite sistematicamente nei prossimi capitoli: * schema_- il protocollo di comunicazione usato (tipicamente “http” o “https”, che verranno presentati nel dettaglio nei capitoli successivi) per richiedere informazioni sulla risorsa indicata dall’URL. Se si pensasse, metaforicamente, ad un URL come un modo per descrivere la locazione di uno specifico oggetto all'interno di una casa, il protocollo identificherebbe il mezzo di trasporto usato (ad esempio una macchina di proprietà, un taxi, un autobus) per raggiungere la casa che contiene il suddetto oggetto dal luogo in cui ci si trova. * host il nome o una sequenza numerica associata al server web (un computer “speciale” parte del Web, che introdurremo nel dettaglio nel prossimo capitolo) che ha a disposizione le informazioni della risorsa identificata dall'URL. Riprendendo la metafora precedente, è l'indirizzo che identifica la particolare casa che contiene l'oggetto che si vuol raggiungere - non per niente, di solito, gli URL che specificano soltanto lo schema e il server restituiscono una risorsa che viene comunemente chiamata home page (ad esempio https://www.repubblica.it). Nella realtà, questa specifica parte dell'URL potrebbe essere anche più complessa, ed includere delle credenziali di autenticazione per accedere al server (metaforicamente: le chiavi per accedere alla casa), ma abbiamo preferito non specificare questo ulteriore dettaglio esplicitamente perché è di fatto molto poco usato negli URL presenti sul Web. + porta—il numero che identifica il particolare servizio a disposizione sul server web a cui si vuole inoltrare la richiesta per avere informazioni sulla risorsa indicata dall'URL. In questo caso, è come se la casa in cui si vuole accedere avesse a disposizione diverse entrate — per esempio la principale, quella che affaccia sul giardino, o quella sul retro — e se ne deve scegliere una per poter accedervi. Nel caso questo componente non venga specificato nell'URL, si assume sempre di usare la porta di default associata al protocollo specificato (80 nel caso di “http”, 443 nel caso di “https”), che metaforicamente significa accedere alla casa usando l'ingresso principale. e percorso - la sequenza di locazioni all'interno del server web, separate da ‘/, da raggiungere per ottenere la risorsa indicata dall’URL. A livello generale, un server web è uno speciale computer elettronico che ha memorizzati diversi documenti, organizzati in diverse cartelle, esattamente come siamo abituati a organizzare i nostri documenti nei nostri computer. In pratica, il percorso di un URL identifica esattamente una risorsa all'interno di questo computer speciale. Metaforicamente, una volta entrati nella casa, il percorso potrebbe essere usato per indicare la sequenza di locali della casa che devo attraversare per arrivare alla stanza che contiene l'oggetto che mi interessa, indicato come ultimo elemento del percorso - ad esempio, “scale a sinistra / primo piano / corridoio / seconda porta a destra / camera dei bambini”. * interrogazione - è una sequenza di coppie chiave=valore, separate da “&”, che è possibile comunicare al server web in modo da eseguire determinate operazioni sulla risorsa indicata dall'URL. Nell'esempio precedente, è come se, per esempio, potessimo chiedere alla casa di eseguire determinate azioni, come accendere le luci della camera in cui ci troviamo - cosa non tanto utopistica ai giorni nostri, se si considera l'enorme diffusione della domotica nel nostro quotidiano. e frammento — una sequenza di caratteri che permette di identificare una parte o una posizione specifica all'interno della risorsa indicata dall’URL. Utilizzando sempre la metafora precedente, è come se avessimo la possibilità di indicare uno specifico oggetto presente nella camera dei bambini della casa in cui siamo entrati, ad esempio il letto a castello dei bambini. L'URL di Wikipedia introdotto precedentemente a scopo esplicativo presenta solo alcuni dei precedenti componenti, in particolare: * lo schema specificato è “http”, che identifica l'uso del relativo protocollo, che approfondiremo nei capitoli successivi; * l'host specificato è “it.wikipedia.org”, che identifica il nome del server web che contiene la risorsa a cui siamo interessati; * il percorso specificato è “/wiki/Uniform_Resource_Locator”, che indica di cercare la risorsa “Uniform_Resource_Locator” all’interno della locazione “wiki”. Questi tre componenti sono, di solito, i principali utilizzati negli URL presenti nel Web e nascosti dietro i link ipertestuali che sono specificati in una pagina Web. Ogni qual volta che, da un proprio dispositivo (un computer, uno smartphone, etc.), si clicca su un link, il dispositivo stesso recupera una copia della risorsa (ad esempio, della pagina Web) a cui l'URL si riferisce, per poi visualizzarla a video. Quindi, seppur noi implicitamente diciamo che, a seguito di un click su un link, noi ci spostiamo da una pagina web ad un'altra, quel che davvero accade è che il dispositivo usato per “navigare” tra le pagine web in realtà scarica interamente e localmente una copia della pagina web a cui si vuole arrivare, e poi la visualizza. Queste azioni sono di fatto implementate, indipendentemente dal dispositivo usato, da una specifica tipologia di applicazioni chiamate browser web (0, più semplicemente browser), introdotta di seguito. Il primo browser della storia si chiamava WorldWideWeb (mostrato in Figura 9), come il Web stesso, creando non poca confusione all'inizio. Era stato sviluppato da Tim Berners-Lee come applicazione per il computer NeXT in modo da permettere ad un utente di navigare tra le pagine del Web allora presenti — la cui prima pagina è ancora custodita negli spazi dedicati a Tim Berners-Lee del sito web del World Wide Web Consortium, un'organizzazione non governativa e internazionale fondata da Tim Berners-Lee per governare, nel modo più comunitario possibile, l'evoluzione del Web. Il funzionamento di un qualunque browser, incluso il primo sviluppato, segue sempre il medesimo schema. Come anticipato, ogni risorsa presente nel Web - sia essa una pagina web, un'immagine, un documento PDF e quant'altro — è identificata da un certo URL. Il browser permette di specificare quell’URL in un apposito campo della sua interfaccia, solitamente in alto, in modo da poter scaricare in locale le informazioni relative alla risorsa indicata dall'URL e, a seconda del tipo di risorsa, permette di visualizzarla all'interno della finestra browser (ad esempio nel caso di una pagina web) o di salvarla in uno specifico documento nel proprio computer (ad esempio nel caso di un documento PDF). Nel primo caso, la pagina web visualizzata è un documento ipertestuale a tutti gli effetti: può contenere dei link che, se cliccati, indicano al browser di richiedere e scaricare la risorsa identificata dall'URL del link stesso così da visualizzarla. Sebbene si dica che un browser viene usato per “navigare” il Web, questa navigazione non è effettiva ma solo metaforica, siccome non ci si sposta fisicamente da una pagina web ad un'altra come se prendessimo un autobus per muoverci tra le varie fermate di una città. Piuttosto, il browser richiede sempre una copia della risorsa identificata da un certo URL, la salva localmente in una locazione privata, e poi la visualizza a video o ne permette il salvataggio in una locazione a scelta del dispositivo che si è usato per accedere a quella risorsa. Il processo di richiesta di una risorsa che abbiamo visto fin qui è riassunto in Figura 10. server web richiede risorsa ittp:M/es.itfdoc1 ida = Bea=E copia documento —documento sul server web sul server web visualizza copia risor TTT browser Figura 10. Riassunto delle tecnologie che abbiamo trattato in questo capitolo.