


1
Informatica



























































































Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
Riassunto del corso di informatica
Tipologia: Appunti
1 / 155

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
La codifica dell’informazione. La codifica dell’informazione fa parte del macro-argomento dell’architettura di un elaboratore. Il termine “informatica” deriva dalla crasi di due parole: la radice di lunghezza 6 di informazione + il suffisso di lunghezza 5 di automatica; per cui informatica = inform azione + autom atica. Più nel dettaglio, l’informatica è quella disciplina che si occupa di far elaborare l’informazione a delle macchine, per cui all’equazione precedente può essere aggiunto che: informatica = informazione + automatica = elaborazione o trattamento + automatico + dell’informazione. All’interno del termine “informatica” vengono quindi individuate sostanzialmente tre parole chiavi:
Processo di codifica: prendo il carattere e guardo a che cosa è associato Esempio → Per codificare “B - spazio- r” [stringa di lunghezza 3 perché conta anche lo spazio, che ha una codifica propria così come tutti gli altri caratteri] ottengo = 1000010 0100000 1110010 Processo di decodifica: Per essere una codifica ASCII, la sequenza di bit deve essere necessariamente un multiplo di 7. In questo caso compio il processo opposto a quello della codifica. Esempio → Per decodificare 1 4 bit = 11111011000101 devo inizialmente suddividerla in gruppi di 7 e successivamente, utilizzando la tabella, devo guardare a quale carattere è associata la sequenza. Verifico quindi che la prima sequenza “1111101” corrisponde a “}”, mentre la seconda sequenza “1000101” corrisponde a “E” Osservazione sulla tabella di codifica ASCII:
Codifica UNICODE: codifica che utilizziamo oggi. Si tratta di un organismo internazionale che lavora in continuità per codificare i caratteri. Attualmente, a livello di caratteri standard, l’UNICODE viene effettuata su 16 bit, ovvero 2 byte, per cui ho 2^16 possibili codifiche di carattere che possono inserire all’interno della macchina. In conclusione, l’UNICODE non smette mai di cercare di standardizzare tutta la nuova informazione che è necessaria. Quanti bit sono necessari per codificare “giulia” in UNICODE? 6*16 = 96 bit Per quanto riguarda i numeri non è presente una tabella che fa corrispondere un simbolo ad una sequenza di bit; per cui dato un numero decimale (naturale senza segno) è possibile passare al corrispondente numero binario (espresso esclusivamente con 0 e 1) attraverso una serie di divisioni successive per 2, nelle quali si considerano tutti i resti. Il primo resto ottenuto è il bit meno significativo della codifica binaria (quello posto all’estrema destra della sequenza). Esempio: 10 = 1010 10 / 2 5 Resto 0 5 / 2 2 Resto 1 2 / 2 1 Resto 0 1 /2 0 Resto 1 La sequenza di bit che viene disposta dalla macchina è fissa, per cui, ad esempio, se la mia macchina lascia uno spazio fisso di 1 byte, il numero “10” verrà codificato come 00001010. In poche parole vado ad aggiungere gli “0” negli spazi a sinistra che mi rimangono liberi. Motivo per cui utilizziamo questo metodo: 111010 = 1 x 10^3 + 1 x 10^2 + 1 x 10^1 + 0 x 10^0 → Codifica nel nostro sistema di numerazione di 1110 Il nostro sistema di numerazione è decimale, ha quindi dieci cifre che vanno da 0 a 9, mentre la macchina ha un sistema di numerazione binario, per cui ottengo che: 1110 = c 3 x 2^3 + c 2 x 2^2 + c 1 x 2 + c 0 x 2^0. Il resto della divisione intera per 2 è C^0 , mentre in quoziente della divisione intera per 2 è c 3 x 2^2 + c 2 x 2^1 + c 1 x 2^0. Per questo motivo, nella divisione, il primo resto che io ottengo è il bit meno significativo. Decodifica: Data una stringa binaria è possibile ottenere il corrispondente numero decimale moltiplicando ogni bit della stringa per la potenza di 2 corrispondente all’indice della cifra considerata e sommando tutti i risultati. Spiegazione → data una sequenza di simboli “0” e “1”, ovvero di bit, devo ottenere il corrispondente numero espresso nel nostro sistema di numerazione. Codifica del numero 137 = 10001001 Codifica del numero 18 = 10010
Computer]; il suo peso equivaleva a 30 tonnellate ed occupava uno spazio di 180 m^2 , inoltre la prima volta che venne acceso lasciò completamente al buio la cittadina accanto a dove era fisicamente situato perché dissipava una quantità di calore molto grande che assorbiva tutta l’energia possibile. I calcolatori di oggi si basano quindi sui risultati ottenuti da Von Neumann, ciò significa che pur avendo fatto dei grandi sviluppi, il modello concettuale è rimasto invariato. Prima di questi studi, per eseguire dei programmi differenti era necessario intervenire a livello fisico (hardware) sulla macchina: delle ruote dentate, che rappresentavano gli input, venivano impostate per stabilire, ad esempio, quali numeri dovessero essere sommati. Se invece che sommare i numeri volevo sottrarli o compiervi un’altra operazione era necessario intervenire manualmente per modificare questi dispositivi. L’idea quindi di Von Neumann è stata quella di far risiedere in una memoria (che prende il nome di memoria centrale o RAM ) i programmi che l’utente decide di far eseguire, ovvero il software, e i dati sui quali questi software lavorano, senza il bisogno di apportare alcun tipo di cambiamento fisico per far seguire un programma; progetta quindi nel 1947 il primo calcolatore con programmi memorizzabili anziché modificati mediate cavi e interruttori. Il suo modello prevede 5 componenti principali:
esclusivamente il processore principale a gestire tutte le operazioni che si svolgono all’interno di un calcolatore, la macchina sarebbe molto lenta. In questo modo invece, il processore principale invia le istruzioni al processore aiutante, in modo da svincolarsi dal seguire le informazioni. Le schede grafiche sono tutte dotate di un proprio processore in modo che il processo principale dice al suo aiutante cosa deve mostrare, ma tutte le informazioni vengono svolte dal processore contenuto nella scheda grafica. I vari processori “aiutanti” sono ovviamente delegati e specializzati, per cui sanno svolgere bene una particolare operazione [es. il processore all’interno della stampante sa gestire la stampa, il processore della scheda grafica sa rendere bene al video le immagini].
le operazioni più velocemente rispetto a quelli con frequenza minore. Ogni macchina ha una frequenza di clock. Overclockare → truccare il processore in modo da costringerlo, sfruttando i margini a disposizione, a emettere dei segnali più serrati in modo da eseguire le operazioni più velocemente. Tuttavia, se il processore viene modificato esageratamente si brucia perché non è fatto per mandare queste correnti a giro così rapidamente. Ad oggi, per la frequenza dei clock, andiamo nell’ordine dei Gigahertz. Per l’acquisto di una macchina, oltre a tener di conto della frequenza dei clock è utile considerare anche la dimensione dei registri e dei bus dati: prendendo il processo spiegato prima, nel quale le istruzioni per essere eseguite devono andare dalla RAM al processore che mette in moto tutti gli agenti necessari per l’esecuzione; è possibile descrivere la differenza fra un processore avente dei registri con 64 bit ed un processore avente dei registri con 32 bit → chiaramente nel secondo caso, poiché il processore ha una capienza più limitata, l’informazione proveniente dalla RAM deve essere spezzata per cui per svolgere l’esecuzione occorre il doppio del tempo. Per quanto riguarda i bus, bisogna fare attenzione che quest’ultimi abbiamo dimensioni uguali a quelle del registro, perché altrimenti le operazioni della nostra macchina sono comunque rallentate. Allo stesso modo è inutile avere bus o registri con dimensioni grandi se poi i primi sono lenti, tenendo di conto che la loro frequenza si misura in milioni di trasferimenti al secondo. Le memorie. Le memorie sono classificate in base a due elementi.
proprio nella RAM). Per valutare la velocità di funzionamento delle memorie di massa ci sono tanti parametri, fra i quali: ➢ Access time (tempo di accesso): intervallo di tempo tra il momento in cui una richiesta di accesso dalla CPU arriva alla memoria e l’istante in cui la memoria termina il proprio compito. ➢ Tempo di ciclo: tempo di accesso + tempo che deve trascorrere prima che possa iniziare un successivo accesso alla memoria. Esempio: Quando leggiamo un dato dalla RAM compiamo una operazione distruttiva, per cui prima di poter accedere nuovamente alla memoria quest’ultima deve riscostruirsi l’informazione precedentemente letta, ovvero deve ristabilire tutta una serie di condizioni prima di poter essere nuovamente operativa. ➢ Transfer rate: quantità di dati trasferiti nell’unità di tempo → velocità con cui i dati vengono trasferiti. ➢ Capacità : la capacità di una memoria la misuriamo con i multipli del byte ed indica la quantità di informazione che può contenere. ➢ Costo per bit : quanto costa produrre un bit. ➢ Modalità di accesso: Può essere diretta, sequenziale, mista ed associativa.
2. Memoria Centrale o RAM [Random Access Memory = Memoria ad accesso casuale] Spiegazione → Parliamo di memoria ad accesso casuale , o ad accesso diretto , in quanto la quantità di tempo che impiego per recuperare un dato è indipendente dalla posizione che quest’ultimo occupa all’interno della memoria. Quasi tutte le memorie elettroniche hanno un accesso diretto. Nei vecchi registratori, quando volevamo ascoltare un brano facevamo scorrere il nastro fino alla posizione in cui si trovava la canzone desiderata, per cui sostanzialmente era necessario leggere, o meglio scandire sequenzialmente, tutta l’informazione che precedeva quella richiesta; è questo il caso di una memoria ad accesso sequenziale nella quale l’accesso dell’informazione non è diretto poiché il tempo è dipendente alla sua posizione. Esiste infine una memoria ad accesso misto (dischi in vinile) all’informazione, ovvero in parte diretto ed in parte sequenziale. Il compito della RAM è quello di mantenere le istruzioni oggetto di esecuzione e i dati sui quali queste operano. La RAM è volatile, riscrivibile (per cui può essere sovrascritta l’informazione), veloce, meno capace, costosa e ad accesso diretto; inoltre è costituita da una successione di elementi bistabili raggruppati in celle di uguale lunghezza, ciascuna dotata di un indirizzo univoco (posizione all’interno della sequenza). È quindi importante distinguere il contenuto della memoria dall’indirizzo di quest’ultimo. Poiché la CPU è molto più veloce della RAM, è presente un “cuscinetto” fra la RAM, contenente le istruzioni ed i dati, ed il processore, colui che esegue le istruzioni sui dati, che corrisponde ad una ulteriore memoria denominata cache , più veloce della RAM. Non possiamo costruire le RAM come le cache innanzitutto per una questione di costo, dopodiché per il modo in cui sono fatte: le cache sono meno dense delle RAM, contengono quindi un numero minore di bit; ciò comporta che per renderle maggiormente capienti bisognerebbe aumentarne le dimensioni fisiche. Martedì 12 Marzo Nello schema di funzionamento di un calcolatore, secondo il modello di Von Neumann, il processore continuamente preleva informazioni ed istruzioni dalla memoria centrale e scrive in essa informazioni. La memoria centrale, il bus ed il processore lavorano a velocità diverse (il processore è quello più veloce) e poiché la velocità complessiva del sistema è determinata dal componente più lento per accelerare questa interazione si impiega una memoria ad alta velocità localizzata tra il processore e memoria centrale, e chiamata cache. Un processore attuale ha una frequenza dell’ordine di qualche giga Hertz: un processore con una frequenza di 1 giga Hertz esegue una operazione in un miliardesimo di secondo Quando si esegue un programma, ovviamente le istruzioni che devono essere eseguite devono stare nei registri dell’unità di controllo che li decodifica, li capisce e che mette in atto tutti gli attori. Per prima cosa, l’istruzione da eseguire viene ricercata nella cache, se vi è presente viene fatta avanzare e entra nei registri dei processori
Costruire una macchina non è molto diverso nel fare le lego, in quanto sostanzialmente si tratta di infilare elementi all’interno di una superficie che prende il nome di scheda madre proprio perché alloggia le componenti della macchina. Quando parliamo di memoria espandibile significa che uno, o più, degli alloggiamenti della RAM è vuoto. Ogni periferica è dotata di questa scheda che implementa l’interfaccia della periferica e serve per riuscire a colloquiare con il processore. Se all’interno di una macchina ci fosse un solo BUS condiviso da tutti gli elementi (il video, la stampante, la tastiera ecc. … ) le informazioni non potrebbero essere inviate contemporaneamente e sarebbero necessari dei meccanismi di arbitraggio; per questo motivo nelle macchine moderne sono presenti dei BUS dedicati ad una sola periferica. Sempre più le periferiche sono dotate di processori, sempre più hanno dei BUS propri e dedicati. Unica cosa importante da sapere dei BUS: Non esiste più un BUS unico nelle macchine di oggi bensì sono presenti BUS dedicati alle singole periferiche, in quanto, se così non fosse ci sarebbe troppo traffico e la macchina sarebbe lenta. La scheda madre: La scheda madre contiene:
Le memorie di oggi sono in realtà pile di dischi a doppia faccia, per cui posso scrivere e leggere in entrambe le superficie, e sono presenti delle testine, una per ogni superficie del disco. Queste testine sono attuate da un dispositivo meccanico che gli fa effettuare un movimento radiale sulla superficie del disco. Cilindro: tutte quelle tracce poste alla stessa distanza dal centro. Se la macchina riesce gli conviene scrivere tutta l’informazione sul medesimo cilindro, in modo da evitare di mettere in azione dei movimenti meccanici e da ridurre il tempo impiegato. Il tempo di accesso all’informazione è composto da:
RW [Read and Write] → questi dischi sono riscrivibili, per cui le modifiche apportate a questi materiali frapposti sopra la superficie riflettente non sono permanenti ma reversibili. In questi dischi è presente uno strato riflettente sopra il quale è presente un ulteriore strato che ha la possibilità di cambiare stato, ovvero di diventare da cristallino a amorfo. Quando il laser ad alta potenza fa passare lo stato cristallino a quello amorfo, significa che la luce non riesce ad arrivare allo stato riflettente; se sono nello stato cristallino riesco allora ad arrivare di sotto. Il processo è reversibile perché se abbasso la potenza del laser e raffreddo la superficie, lo stato amorfo torna ad essere cristallino. La lettura avviene sempre con gli stessi principi dei dischi normali, con un laser a minor potenza. La differenza fra i cd, i dvd, e il Blu-ray: Le dimensioni dei buchi dei cd sono più grossi rispett o a quelli dei dvd, la distanza tra le tracce è più piccola per cui a parità di dimensione del supporto nel dvd la densità dell’informazione è maggiore rispetto al cd, ottenuta facendo i pit e i land più piccoli e serrando le tracce su cui vi risiedono. Per cui i dvd hanno Pit più piccoli, spirale più serrata e laser rosso. Nei cd si usa un laser a infrarossi, mentre nei dvd si utilizza un laser rosso. Nei Blu-ray i pit e i land sono ancora più piccoli e la distanza fra le tracce è ancora inferiore; inoltre il raggio laser utilizzato è il blu. Blu-ray → non c’è la “e” finale perché nel posto in cui sono nati non è possibile utilizzare nomi normali. Giovedì 14 Marzo Il sistema operativo è un software come tutti gli altri, per cui risiede nella RAM e viene eseguito dal processore, ed ha lo scopo di fungere da intermediario tra la parte fisica (hardware) e l’utente. Sono quindi presenti diversi strati: il cuore (l’hardware), il sistema operativo (che maschera sia all’utente sia ai software di tipo applicativo tutta la complessità architetturale dei dispositivi digitali), i software applicativi ed infine, all’esterno, c’è l’utente che interagisce con il software operativo, per cui i software applicativi non hanno un accesso diretto ai dispositivi hardware ma solo ed esclusivamente attraverso il sistema operativo. Sistemi operativi: [windows, Linux, OS, Android, ecc..] I software applicati sono tutti quei programmi che non fanno parte dei sistemi operativi e che sono suddivisi in diverse categorie a seconda del tipo di problema che sono in grado di risolvere; esiste ad esempio il software per l’elaborazione del testo, il software per l’elaborazione dei dati (es. R, excelle), il software per le basi di dati (Microsoft, access, Oracol), il software per la grafica, il software per la risoluzione dei filmati, ecc. … Oltre ai software applicativi sono preseti gli strumenti di sviluppo , ovvero ambienti di sviluppo integrati che permettono di scrivere il codice utilizzando un linguaggio di programmazione ad alto livello e di tradurre le istruzioni che scriviamo in alto livello in un insieme di istruzioni del tutto equivalenti ma scritte in un linguaggio particolare, ovvero quello macchina. Quando l’utente scrive i programmi in MathLab scrive i codici sorgenti scritti in un linguaggio di programmazione ad lato livello in quanto hanno una sintassi ed unna semantica che riguarda parole inglesi. All’interno dell’idea di MathLab c’è una categoria di software che prendono il nome di traduttori che hanno lo scopo di scrivere un insieme di istruzioni, in un altro linguaggio, del tutto equivalenti a quelle scritte in un linguaggio ad alto livello:
I sistemi operativi sono composti da sei moduli:
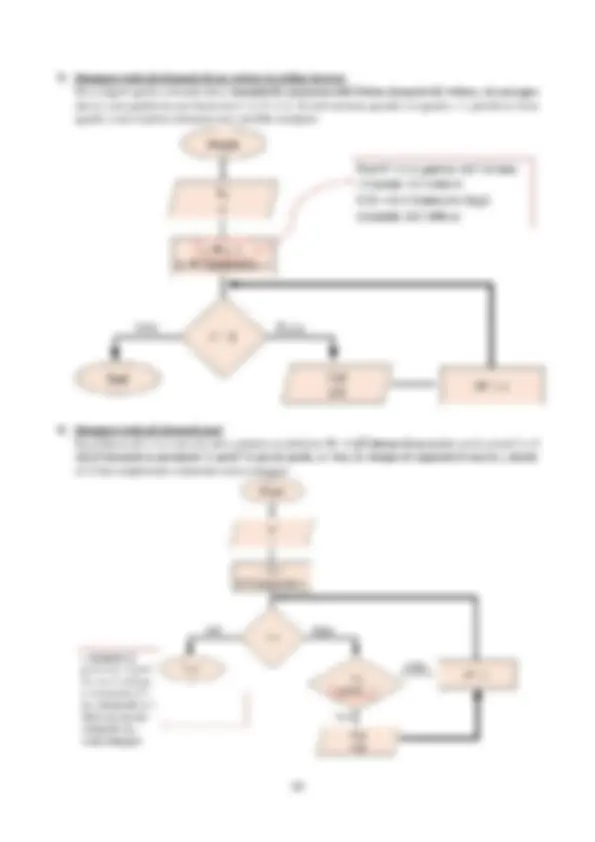
terminare, oppure può avere necessità di una risorsa I/O entrando quindi nella fase di attesa. Dallo stato di attesa un processo torna nello stato di pronto quando l’utilizzo del dispositivo I/O è stato effettuato, in modo da proseguire la sua esecuzione (ritorna ad attendere l’attenzione della CPU).
1. Il gestore dei processi Il gestore dei processi è colui che gestisce il contesto di esecuzione dei vari processi, per cui li crea e li cancella, li sospende e li riattiva (dallo stato di pronto il processo prima o poi torna nello stato di esecuzione), fornisce i meccanismi per la loro sincronizzazione, comunicazione e per evitare, prevenire e risolvere i deadlock, gestisce il contesto di esecuzione di ognuno di loro [quando il processo passa dallo stato di esecuzione a quello di pronto viene fatta una specie di fotografia al contesto in modo da poterlo ripristinare nel momento in cui passa dallo stato di esecuzione a quello di pronto], gestisce l’alternanza nell’accesso alla CPU da parte dei processi in esecuzione, gestisce i compiti da assegnare alla CPU ed infine gestisce la risposta agli eventi esterni generati dalle unità periferiche. In poche parole, il gestore dei processi detta quali processi assegnare al processore secondo alcune politiche e gestisce la risposta generata dalle unità periferiche (quando la stampante ha finito di stampare manda al processore un feedback nel quale lo avverte di aver finito il proprio compito). Quindi, ricapitolando, dal punto di vista del processore in ogni istante vi è un solo processo di esecuzione, mentre dal punto di vista dell’utente, se l’alternanza tra i processi è frequente, l’impressione è che l’esecuzione dei programmi avvenga simultaneamente. Le politiche per alternare i processi nello stato di pronto eseguibili dal processore sono molte e dipendono dai vari sistemi operativi, o meglio dai vari software che vengono lanciati in esecuzione poiché non tutti hanno la stessa priorità: ad esempio, l’antivirus ha una priorità maggiore di word per cui se rileva qualcosa che non quadra salta la lista dei processi pronti prima di lui e va immediatamente in esecuzione. Per quanto riguarda la politica utilizzata per i processi operativi aventi tutte le medesime priorità, prende il nome di round robin , è di tipo FIFO [First In First Out], per cui il primo processo che entra nella lista è il primo ad essere assegnato al processore, e funziona a time-sharing (partizione del tempo) , grazie al quale un solo processo non può monopolizzare il processore che assegna quindi ad ognuno dei processi un quanto di tempo. Cosa succede: supponiamo che nella lista dei processi pronti ci siamo tre processi, il primo di nome P1, il secondo di nome P2 ed il terzo di nome P3. P1, essendo il primo presente, passa subito allo stato di E, nel quale sta per il tempo che gli viene dedicato, dopodiché passa ad uno stato di P (pronto), ed il processore rivolge la sua attenzione al processo P2. Il processo P2 viene eseguito per il suo quanto di tempo, dopodiché anche a lui viene tolta l’attenzione del processore che viene data al processo P3. Una volta che anche quest’ultimo processo termina il suo quanto di tempo, P1 che si era nuovamente accodato, ripassa nello stato E ed il processo esegue nuovamente questo ciclo. Ad un certo punto, P1 ha bisogno di una operazione I/O, ovvero richiede la necessità di un dispositivo ingresso/uscita, per cui passa nello stato A (attesa) ed il suo posto nello stato E viene sostituito da P2, in modo da non lasciare il processore ad attendere senza far niente. Fino a quando P1 è situato nella fase A, solamente P2 e P3 vengono alternati per ricevere l’attenzione del processore; nel momento in cui lo stato di attesa termina, P1 passa nuovamente nello stato di pronto e si rimette in fila.