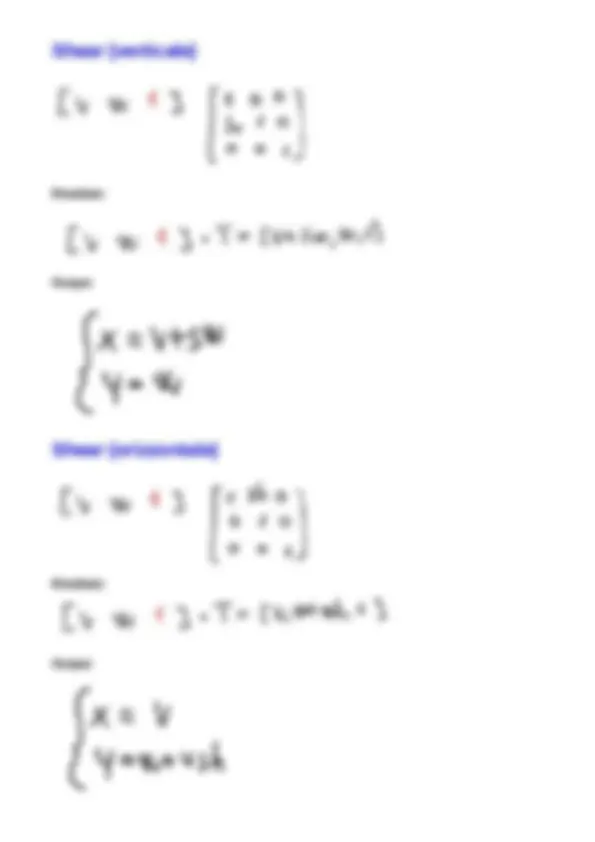Scarica Interazione e Multimedia: Elaborazione delle Immagini Digitali, Tecniche e Metodi e più Appunti in PDF di Elaborazione digitale delle immagini solo su Docsity!
ELABORAZIONE DELLE IMMAGINI
E' una rappresentazione visiva non solida ( bidimensionale ) di una realtà. Quello che il cervello percepisce è sempre un'immagine bidimensionale anche se, comunque, si tratta di un'immagine 3D.
Storia
La prima foto fu scattata nel 1827 ed il tempo di esposizione era di circa 8 ore e quest'ultima si chiama " Vista dalla finestra a Le Gras ". Le prime immagini digitali si trovano nei quotidiani. Alcuni anni dopo (dopo il 1920) si pensa di ottenere nuove immagini da delle immagini di partenza, quindi si pensa all' editing di esse. La stampa in halftoning conteneva immagini con scala di grigi che ingannano l'occhio e, andando avanti nel tempo, si avevano 5 e poi 15 livelli di grigio. La prima elaborazione di un'immagine avviene dalla NASA negli anni '60 ed elabora un'immagine della luna e ne corregge alcune distorsioni ottiche per acquisire molti più elementi dell'immagine.
Perché si elabora un'immagine digitale?
Le immagini digitali vengono usate in medicina , ricerche (dal satellite), per le forze dell'ordine , per i beni culturali ecc.. L'occhio può acquisire le immagini ma è il cervello a dover elaborare le immagini viste. Di seguito vediamo delle leggi per capire, in maniera approssimativa, come vengono elaborate le immagini dall'occhio umano.
Le leggi della percezione visiva
I daltonici non riescono a distinguere le lettere CH dall'immagine soprastante e dipende dal nostro modo di reagire agli stimoli visivi perchè è soggettivo "formare" immagini.
Leggi della vicinanza
Si tende a mettere insieme ciò che è vicino e quindi a fare un raggruppamento. Tendenzialmente si vedono 4 elementi da formati da 2 linee ciascuno.
Legge della chiusura
Gli elementi chiusi hanno più valore per l'occhio e quindi, per tale motivo, i quadrati risaltano di più rispetto alle linee.
Legge della somiglianza
Si tende a pensare che sia una linea di pallini piuttosto che dei pallini vicini fra essi. Generalmente si vedono 4 righe di punti bianchi e 4 linee di punti neri.
Altre illusioni ottiche
Si è abituati a completare ciò che non è completo. Per esempio:
Non sempre si ha bisogno di tutto per avere una comprensione di quello che si sta osservando perché viene completato in automatico sfruttando una stima.
Nell'immagine soprastante, si immagina che la linea rossa, sotto i rettangoli che la coprono, sia comunque continua.
Queste leggi possono essere sfruttate, per esempio, nella ristrutturazione degli oggetti utilizzando le linee già presenti.
Inpainting
La tecnica inpainting consiste nell'eliminazione di elementi da delle immagini facendo una stima della realtà mediante il rimpiazzo di elementi come se fosse lo strumento "Correggi" negli editor di immagini.
Illusioni ottiche
Le bande di Mach
La banda a destra è più chiara e quella a sinistra è più scura. La percezione è quella mostrata ne grafico " Perceived intensity ", dov'essa è diversa rispetto alla reale transizione di colori fra i grigi (" Actual Intensity "). Tendenzialmente, se si guardano le figure da sinistra verso destra, si vede il rettangolo seguente un po' più scuro di quanto non lo sia veramente.
Contrasto simultaneo
I quadrati centrali sono dello stesso colore. Il quadrato centrale più a destra sembra più scuro all'impatto e dipende dallo sfondo. I colori uguali dei quadrati centrali sembrano completamente diversi perchè l'occhio valuta anche il contrasto dello sfondo.
Rappresentazione di un'immagine
L'immagine è bidimensionale non solida quindi si può usare il formalismo matematico a 2 dimensioni. Un'immagine si può considerare come una funzione f ( x , y ) che ha un certo valore in corrispondenza di x e y che rappresentano le coordinate spaziali.
Si distinguono 2 aspetti:
- i ( x , y ), che rappresenta LUCE INCIDENTE , cioè quella che arriva dall'esterno e colpisce l'oggetto;
- r ( x , y ) , che rappresenta la LUCE RIFLESSA cioè la luce che l'oggetto riflette (dipende quindi dall'oggetto e le sue caratteristiche chimiche) che non è la stessa di quella incidente visto che una parte di luce viene assorbita dall'oggetto.
Quindi, generalmente, l'immagine può essere descritta f ( x , y ) = i ( x , y ) ⋅ r ( x , y )
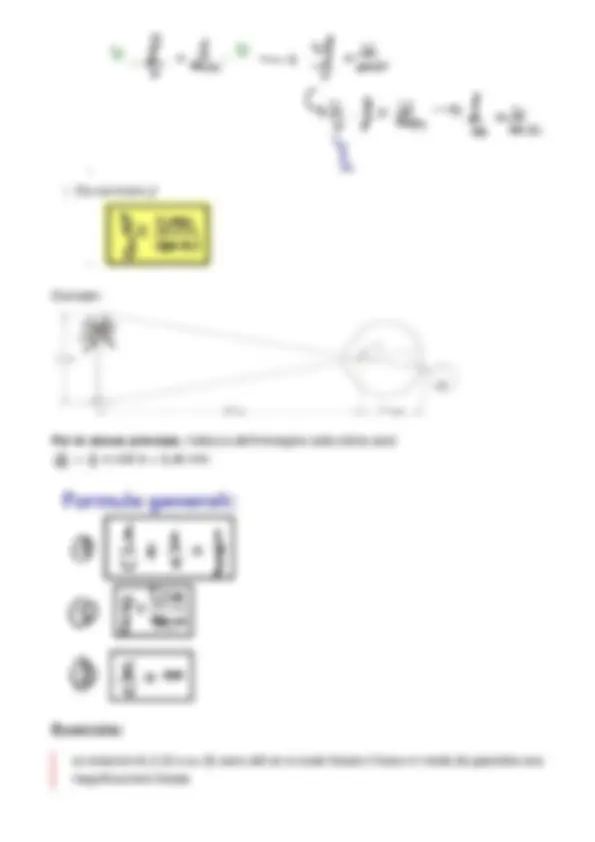
i può tendere ad un valore estremamente grande (non si considerano limiti), quindi 0 < i ( x , y ) < ∞ r può avere un valore in percentuale della luce riflessa, quindi 0 < r ( x , y ) < 1. Quando è 1, dipende solo dalla luce incidente perchè tutta la luce incidente viene riflessa. Quando è 0 allora l'oggetto lo vedo nero e la luce riflessa è pari a 0.
Gli oggetti che appaiono più scuri perchè hanno coefficiente di riflessione più vicini allo zero e viceversa; Un oggetto che assorbe completamente la luce non si può ottenere mai in natura (coefficiente di riflessione 0) (per esempio: "il nero più nero del mondo"); L'unità di misura dell'intensità luminosa è il lumen.
Alcuni valori tipici di illuminazione e riflettanza
Il Sole può produrre più di 90000 lm / m^2 ; produce fino a 10000 lm / m^2 quando è nuvoloso; La Luna piena raggiunge 0.1 lm / m^2 (ricordando però che la Luna non produce luce propria ma diremo "teoricamente" che brilla di luce propria).
Questo implica che nella descrizione dell'immagine ho una limitazione del numero di pixel che si ha a disposizione. Il grado di dettaglio dipende, quindi, dal numero di pixel disponibili. Il numero di pixel disponibili viene chiamato RISOLUZIONE.
Esempio di Raster: Paint.
Immagine Vettoriale
L'immagine vettoriale si descrive attraverso una lista definendo singolarmente tutte le primitive geometriche presenti nell'immagine.(bordo, centro, altezza,colore della figura, colore del bordo, ...) Quindi esiste una maniera precisa che serve per descrivere le figure. Pertanto le primitive sono " fissate ".
Vantaggi e svantaggi
Un' immagine fotorealistica , rappresentata con immagini vettoriali, avrà primitive geometriche molto elevate e quindi verranno utilizzate grandissime quantità di memoria. Pertanto si utilizzano le immagini Raster; Uno schizzo e/o un disegno tecnico viene rappresentato con un'immagine vettoriale che rappresenta linee più nitide per ogni area dell'immagine.
Confronto fra foto fotorealistiche
Rasterizzare
Rasterizzare vuol dire passare da un'immagine vettoriale ad una matrice in raster, così perdendo descrizione, non c'è più concetto di descrizione a livello geometrico.
Formati grafici vettoriali:
PS ( Postscript ): Formato sviluppato da AdobeSystems originariamente per la stampa di documenti su stampanti laser, è utilizzato anche per la memorizzazione di immagini vettoriali. EPS ( Encapsulated Postscript ): Estensione del formato PostScript che consente di incapsulare immagini bitmap (raster). DCS ( Desktop Color Separation ): Un caso speciale di EPS sviluppato originariamente da Quark per tenere separati i dati al alta risoluzione dall'anteprima a bassa risoluzione. PDF ( Portable Data Format ): Sviluppato da Adobe, è il formato più diffuso per condividere, indipendentemente dalla piattaforma, documenti di testi e immagini. PDF usa immagini raster ma sa gestire immagini vettoriali mantenendo, dopo l'esportazione, le immagini vettoriali che sono state inserite. Sa ricalcolare le primitive. PICT : Formato grafico sviluppato da Apple Computer per la piattaforma Macintosh in grado di memorizzare sia immagini vettoriali che raster.
PIXEL
i 3 puntini servono per dire che la figura è più grande rispetto a quella rappresentata. La matrice a sinistra rappresenta una porzione dell'immagine di Lena e i vari numeri rappresentano proprio f(x,y).
Ogni numero presente nel pixel è associato ad una luminosità/colore; con 8 bit , i valori dei pixel variano da 0-255 ; colori scuri = valore del pixel basso colori chiari = valore del pixel alto Nella seguente immagine vi è l'immagine di Lena e, accanto, la tabella che rappresenta i valori dei pixel di una porzione d'immagine.
Scala di grigi
Servono 8 bit per pixel; Nella posizione ( i , j ) ci sarà un valore compreso fra [0, 255].
A colori
8 bit per canale. Poiché i canali sono 3 avrò 24 bit ; Nella posizione ( i , j ) ci sarà una terna del tipo ( x , y , z ) con x , y , z che assumono valori compresi tra [0, 255].
In questo caso si descrive anche la lunghezza d'onda combinando le 3 lunghezze d'onda fondamentali, ovvero Red, Green e Blue (RGB). Quindi si rappresenta mediante 3 contributi di 3 lunghezze d'onda (il più usato).
Se si usassero i canali singoli (solo una lunghezza d'onda) vengono rappresentati come se fossero 3 immagini a scala di grigi:
OPERAZIONI SULLE IMMAGINI
Si tratta di un'operazione che prende una matrice e modifica i valori dei pixel secondo qualche regola (dipende dall'operazione da implementare e dal risultato al quale si tende ottenere). Le operazioni principali sono:
Somma di un valore negativo o positivo se voglio scurire o schiarire un'immagine quindi modificando i valori dei pixel. Il prodotto puntuale si fa fra 2 matrici che hanno esattamente le stesse dimensioni e corrisponde: A = [ aij ] B = [ bij ] C = [ cij ] = [ aij ⋅ bij ]
Le possibili operazioni che si fanno fra le matrici di un'immagine sono somma e prodotto:
Dalla somma fra 2 matrici raster (immagini raster) posso ottenere la matrice risultante. Con la somma matriciale non ottengo un un risultato "interessante" perchè non ottengo l'unione fra le due immagini raster. Il prodotto , invece, mi da un risultato molto più interessante. Esso è riga per colonna. Per eseguire tale moltiplicazione matriciale è necessario che le colonne della prima matrice siano uguali al numero di righe della seconda matrice. Per esempio: 4x e 3x7 sono moltiplicabili perchè i valori "medi" delle dimensioni sono uguali
OPERAZIONI AFFINI
Presa un'immagine, un' operazione affine lavora solo sulla posizione dei singoli pixel. Serve per spostare i pixel nella nuova immagine. Non cambiano l'aspetto dell'immagine ma solo la posizione dei pixel e solitamente si fa sempre con le 3x3.
Sostanzialmente si calcola, pixel per pixel, la nuova posizione che l'immagine deve assumere.
Procedura:
Prendo un punto nella matrice di coordinate generiche ( v , w ) e le metto in un vettore riga e con questo si vuole fare un'operazione; L'operazione vale per un solo pixel; Il numero di pixel non raddoppia perchè non aumento o diminuisco i pixel; Scorro tutti i pixel della matrice e dico dove andare a posizionare i nuovi pixel mediante le operazioni affini; Non è detto che nella matrice di output io abbia riempito tutti pixel.