Scarica Linguaggio java fondamenti di programmazione e più Schemi e mappe concettuali in PDF di Informatica solo su Docsity!
I linguaggi di programmazione sono divisi in: Compilati Semi-interpretati Interpretati Linguaggi come il C, C++, sono linguaggi compilati Linguaggio compilato ossia il codice sorgente (il codice scritto con un editor di testo) viene “trasformato” (tramite il compilatore) in codice macchina, ovvero in un file eseguibile direttamente su quella macchina. Questo tipo di linguaggi hanno il vantaggio di avere prestazioni migliori, ma hanno lo svantaggio di portabilità. Nei linguaggi interpretati, invece, le istruzioni del codice sorgente vengono eseguite direttamente, senza essere trasformate in un altro formato.
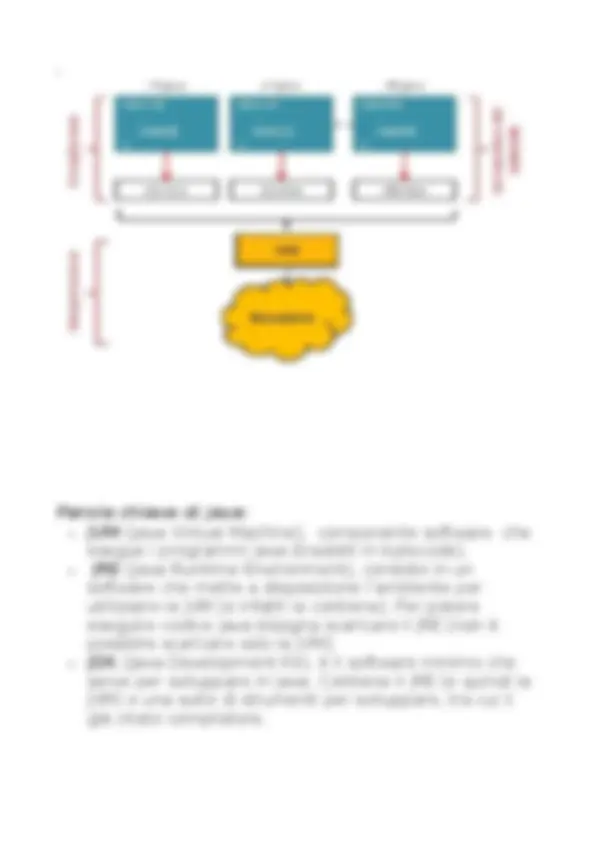
Linguaggio interpretato Un esempio su tutti è l’HTML, il cui codice viene eseguito direttamente dal browser. La potenza di questo genere di linguaggi è, di fatto, l’alta portabilità. Java è un linguaggio semi-interpretato , ossia il codice sorgente viene “trasformato” (tramite un compilatore) in un formato intermedio (detto bytecode , riconoscibile dalla estensione file .class ) che viene eseguito da un componente software installato sulla macchina in questione. Questo componente è detto Java Virtual Machine (JVM). Linguaggio semi-interpretato Quindi riassumendo, il codice sorgente, uguale per qualsiasi macchina, viene compilato tramite il compilatore (uguale anch’esso per tutte le macchine). Dal compilatore si ottiene il bytecode che viene eseguito dalla virtual machine, quest’ultima dipendente dal tipo di macchina (ossia una JVM di linux sarà diversa da una JVM di windows). Il vantaggio è che un file compilato .class può essere trasferito su qualunque macchina senza problemi. Alta portabilità.
LE VARIABILI
Per scrivere applicazioni Java, la prima cosa che un programmatore deve sapere è creare e usare le variabili. Una variabile è una piccola area di memoria nel quale viene salvato un determinato dato. Per essere utilizzata per svolgere qualche operazione deve essere prima dichiarata e poi inizializzata. Per la dichiarazione si fa riferimento alla seguente sintassi: <tipo_variabile> <nome_variabile>; che ha lo scopo di allocare in memoria una variabile indicata dal nome “x”. Il tipo_variabile indica che cosa si deve memorizzare nella area di memoria. Può essere ad esempio un numero, un numero con virgola, un testo etc. Più avanti vedremo i tipi dati in java. Esempio di dichiarazione di una variabile con nome x e di tipo intero (int in java) int x; Una volta che la variabile è stata dichiarata, abbiamo la possibilità di inserire dei valori (sempre dello stesso tipo della variabile, quindi se la variabile è di tipo intero possiamo inserire solo degli interi). La sintassi è: <nome_variabile> = Esempio:
short : da -32768 a 32767 incluso. 16 bit int: da -2147483648 a 2147483647 incluso. 32 bit long : da -9223372036854775808 a 9223372036854775807 incluso. 64 bit. In genere si aggiunge il suffisso l o L. es. long prova = 500L; float : per numeri con la virgola, fino a 7 cifre dopo la virgola. Occupano 32 bit. In genere si aggiunge il suffisso f o F. double : per numeri con la virgola, fino a 16 cifre dopo la virgola. Occupano 64 bit. In genere si aggiunge il suffisso d o D. Se non è specificato, un numero con la virgola è considerato un double. boolean : serve a rappresentare i valori vero o falso. es. boolean pro = true; char : è utilizzato per la memorizzazione di caratteri. Il casting è un meccanismo che consente di convertire i dati da un tipo a un altro (per ora intendiamo tipi primitivi). Esempio: short c = 10 ; int d = c; Questo conversione può essere fatta senza problemi, perché siamo sicuri che il valore contenuto in c potrà essere sicuramente contenuto in d, essendo il range del tipo int più grande di quello del tipo short. Ma cosa succede se facciamo l’operazione inversa? Ossia cerchiamo di convertire un int in un short? Esempio: int a = 10 ; short b = a;--> errore di compilazione (overflow) Il compilatore ci segnala l’errore perché c’è il pericolo di perdita di precisione: infatti un numero intero potrebbe essere più grande di un numero short.
Possiamo ignorare questa segnalazione effettuando un cast esplicito, cioè vengono inserite una coppia di parentesi, indicando all’interno il tipo dati in cui convertire la variabile “a”. Esempio : int a = 10 ; short b = (short) a; in questo modo il programmatore si sta assumendo il rischio di una eventuale perdita di precisione. Ma che succede se il valore di “a” è più grande di “b”? Esempio : int a = 100000 ; short b = (short) a; dentro b ci sarà il valore “-31072”, cioè, in questo caso, il valore inferiore del range di short. In un casting, per esempio, tra double e float invece perdiamo le ultime cifre decimali. Esempio: double a = 0.100000234523; float b = (float)a;-->dentro “b” ci sarà il valore approssimato “0.10000023”
La differenza principale è che, nel caso di new, viene creato un nuovo oggetto in memoria, invece, con la forma letterale, viene prima controllato se esiste già una stringa simile in una speciale area di memoria dedicata alle stringhe ( String Pool ); se esiste si ritorna un riferimento ad essa altrimenti si crea nuova e la si mette sempre nel string pool. Esempio: Str1 e str2 puntano alla stessa stringa in memoria (nello string pool). Str3 invece, nonostante il contenuto della stringa sia uguale (abc) punta ad un’altra locazione di memoria. Di conseguenza str1== str2 è vera; mentre str1== str3 è falsa. L’uso delle stringhe letterali è da preferire, in quanto ottimizzano l’uso della memoria.
La caratteristica di usare lo string pool, non avviene solo alla creazione di una stringa, ma anche alla modifica: ogni volta che si tenta di modificare una stringa non si modifica effettivamente la variabile ma si crea una stringa nuova, o la si prende dal string pool. Questa caratteristica delle stringhe è nota come immutabilità delle stringhe. Esempio : creiamo una stringa String a = "abc"; e, subito dopo: a = "World"; L’ultima istruzione modificata l’oggetto originario, che conteneva la stringa “abc”, ma crea una nuova stringa inizializzata con la stringa “World”. La vecchia stringa “abc” è rimasta in memoria intatta, senza nessuna modifica. Anche l’assenza di metodi set, nelle stringhe, mette in evidenza la loro immutabilità.