



1
LA REGRESSIONE
LINEARE SEMPLICE
























































Besser lernen dank der zahlreichen Ressourcen auf Docsity

Heimse Punkte ein, indem du anderen Studierenden hilfst oder erwirb Punkte mit einem Premium-Abo

Prüfungen vorbereiten
Besser lernen dank der zahlreichen Ressourcen auf Docsity
Download-Punkte bekommen.
Heimse Punkte ein, indem du anderen Studierenden hilfst oder erwirb Punkte mit einem Premium-Abo
slides su regressione statistica
Art: Slides
1 / 66

Diese Seite wird in der Vorschau nicht angezeigt
Lass dir nichts Wichtiges entgehen!
1
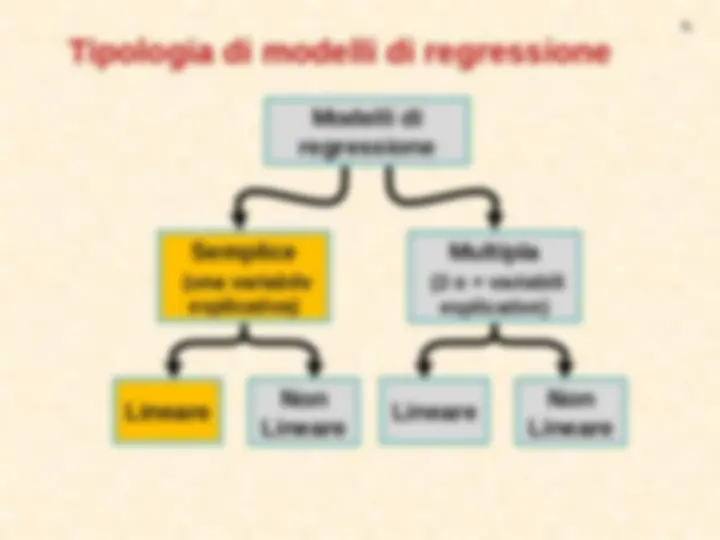
Nello studio delle relazioni tra due (o più) variabili, oltre a misurare l’intensità del legame esistente, si è anche interessati ad accertare come varia una di esse (dipendente) al variare dell’altra (indipendente, o delle altre, variabili indipendenti), individuando un’opportuna funzione analitica che sintetizzi tale relazione. (^) Nel caso di una sola variabile indipendente si parla di regressione semplice ; (^) In presenza di due o più variabili indipendenti siamo nel campo della regressione multipla.
Dopo aver rappresentato graficamente i dati a mezzo dello scatter-plot se notiamo una regolarità di tipo lineare (i punti si dispongono grossomodo attorno ad una retta immaginaria) possiamo voler “sintetizzare” tale “regolarità” mediante una funzione analitica “ragionevolmente semplice” Il presupposto è che esista una variabile (la "X” detta indipendente o esogena) che è causa o che comunque agisce sull’altra (la "Y” detta dipendente o endogena). La scelta del ruolo delle due variabili è una scelta extra-statistica
Y X Y X Y Y X X Relazione forte Relazione debole
Y X Y X Nessuna relazione
Vi sono molti casi in pratica in cui la teoria di un fenomeno può essere sintetizzata da un modello espresso da una equazione lineare. Ad esempio, ”Y" la spesa per consumo delle famiglie e sia ”X" il reddito disponibile. L'idea che il consumo aumenti all’aumentare del reddito disponibile può essere espressa dalla relazione funzionale: Componente Lineare Intercetta della Popolazione Coefficiente angolare della popolazione Errore casuale Variabile Dipendente Variabile Indipendente
Il modello qui sopra mi dice che tutti i possibili Yi sono pari a
Di fatto, noi possiamo osservare solo alcune coppie
Partiamo però da alcuni punti fermi (assiomi di partenza):
Scriviamo in un foglio Excel (Simulazione) in B1 , B2 e B4 i “parametri
Supponiamo di osservare un valore della variabile X (reddito) pari a 3529. Il corrispondente valore Y (spesa) sarà pari a
un numero estratto casualmente da una normale con m= B e s2= B
Generiamo questo secondo la “regola” ipotizzata