Download 2 Contingency Tables and more Schemes and Mind Maps Statistics in PDF only on Docsity!
2 Contingency Tables
I. Probability Structure of a 2-way Contingency Table
I.1 Contingency tables
- X, Y :– cat. var. Y − usually random (except in a case-control study), response; X− can be random or fixed, usually acts like a covariate. X has I levels, Y has J levels.
- A contingency table for X, Y is an I × J table filled with data.
- For example,
Y 1 2 3 X 1 n 11 n 12 n 13 2 n 21 n 22 n 23
Y
X 1 n 11 n 12 2 n 21 n 22 3 n 31 n 32
- For example, from a random sample of n = 1127 Americans, we have the following contingency table: Table 2.1. Cross classification of Belief in Afterlife by gender Belief in afterlife Yes No/Undecided Gender Female 509 116 Male 398 104
- With a contingency table for X, Y , we would like to understand the association between X and Y , the underlying probability structure of the table, etc.
- For example, for the afterlife table, we would like to see if one gender is more likely to believe in afterlife, or the overall proportion with belief in afterlife in the population, etc.
? In general, a 2 × 2 table from multinomial sampling Y 1 2 X 1 n 11 n 12 n1+ 2 n 21 n 22 n2+ n+1 n+2 n where (n 11 , n 12 , n 21 , n 22 ) are random variables that have a multinomial distribution with sample size n (n = n 11 + n 12 + n 21 + n 22 ) and probabilities Y 1 2 X 1 π 11 π 12 2 π 21 π 22 (π 11 , π 12 , π 21 , π 22 ) define the probability structure of the contingency table. Slide 43
The standard statistical model underlying analysis of contingency tables is to assume that (unconditional on the total count) the cell counts are independent Poisson random variables.
Once you impose a total cell count for the contingency table, or a row or column count, the resulting conditional distributions of the cell counts then become multinomial.
https://stats.stackexchange.com/questions/45479/pearsons-residuals
? πij ’s can be estimated by pij = nij /n. ? With multinomial sampling, we can estimate many relevant quantities:
P̂ [Y = 1] = n^11 +^ n^21 n
= n+ n P̂ [X = 1] = n^11 +^ n^12 n =^
n1+ n P̂ [Y = 1|X = 1] = n^11 n 11 + n 12 =^
n 11 n1+ P̂ [X = 1|Y = 1] = n^11 n 11 + n 21 =^
n 11 n+^ ... ? For afterlife example, we estimated that
P̂ [belief in afterlife] = 509 + 398 1127 = 80% P̂ [belief in afterlife|Female] = 509 509 + 116 = 81% P̂ [belief in afterlife|Male] = 398 398 + 104 = 79%...
Total 907 220 1,
- Find joint prob;
- Find marginal prob;
- Find Conditional prob.
? In general, the data looks like Y 1 2 3 X 1 n 11 n 12 n 13 n1+ 2 n 21 n 22 n 23 n2+ where n1+ and n2+, the sample sizes for X = 1 and X = 2, are fixed. (n 11 , n 12 , n 13 ) ⊥ (n 21 , n 22 , n 23 ) (n 11 , n 12 , n 13 ) ∼ multinom(n1+, (π 1 , π 2 , π 3 )), π 1 + π 2 + π 3 = 1 (n 21 , n 22 , n 23 ) ∼ multinom(n2+, (τ 1 , τ 2 , τ 3 )), τ 1 + τ 2 + τ 3 = 1 ? Since the likelihood of π’s and τ ’s is the product of the likelihood of π’s and the likelihood of τ ’s, this sampling scheme is called product-multinomial sampling on X. ? Clinical trials, cohort studies (prospective studies) all use this sampling scheme. Prospective study: Participants are enrolled into the study before they develop the disease or outcome in question.
? When X is also random (so has a distribution in the population), (π 1 , π 2 , π 3 )’s defines the conditional distribution of Y given X = 1 (τ 1 , τ 2 , τ 3 )’s defines the conditional distribution of Y given X = 2. ? With product-multinomial sampling on X, we can only estimate conditional probabilities of Y |X = x. Other probabilities are not estimable. For example, we cannot estimate P [Y = 1].
? We may consider a design such as the following one:
Lung Cancer Yes No Smoking Yes n 11 n 12 No n 21 n 22 n+1 = 100 n+2 = 200 All cell counts will not be small ⇒ efficient. n 11 ⊥ n 12 n 11 ∼ Bin(n+1, π 1 ), π 1 = P [smoking|case]. n 12 ∼ Bin(n+2, π 2 ), π 2 = P [smoking|control].
? We can still investigate the association between smoking and lung cancer using this design. ? This sampling scheme is product-multinomial on Y. ? The study is often called the case-control study.
? In general,
Lung Cancer Yes No Smoking Yes n 11 n 12 No n 21 n 22 n+1 n+ where n+1, n+2, are all fixed. n 11 ⊥ n 12 n 11 ∼ Bin(n+1, π 1 ), π 1 = P [smoking|case]. n 12 ∼ Bin(n+2, π 2 ), π 2 = P [smoking|control].
n 11 n 11 + n 21
π1=
π2=
n 12 n 12 + n 22
- Note: Multinomial sampling ⇒ product-multinomial sampling.
For example, if we have data from a multinomial sampling with sample size n: Y 1 2 X 1 n 11 n 12 2 n 21 n 22
Y
X 1 π 11 π 12 2 π 21 π 22 Then we can view the data from product-multinomial sampling on X or product-multinomial sampling on Y. That is: n 11 |n1+ ∼ Bin(n1+, (^) π 11 π+^11 π 12 ) ⊥ n 21 |n 2 + ∼ Bin(n2+,π 21 π^21 +π 22 ) Or n 11 |n+1 ∼ Bin(n+1, (^) π 11 π+^11 π 21 ) ⊥ n 12 |n+ 2 ∼ Bin(n+2,π 12 π^12 +π 22 )
I.3 Sensitivity & Specificity in Diagnostic Tests
- In a diagnostic test, X = true disease status, Y = test result. Then we can form a 2 × 2 table:
Y Positive Negative X Disease No Disease
- Using data from multinomial sampling or product-multinomial sampling on X, we can estimate Sensitivity = P [Y =Positive|X = Disease] (True positive rate) Specificity = P [Y =Negative|X = No disease] (True negative rate)
- 1-Sensitivity = False negative rate, 1-Specificity = False positive rate. These two quantities tell us how accurate a test/device is. Manufacturer of a test device usually provides these two measures. Slide 53
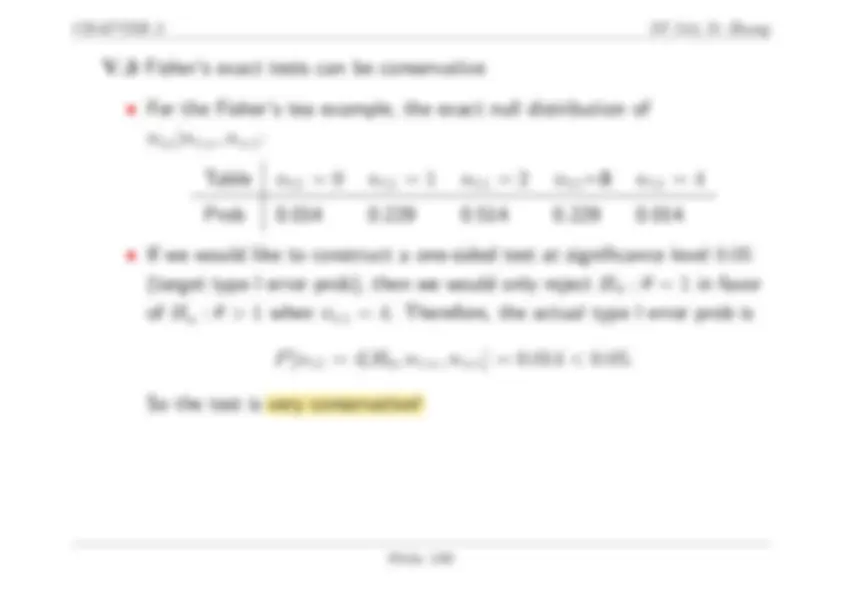
Q: Find sensitivity and specificity.
The higher the sensitivity and specificity, the better the diagnostic test.
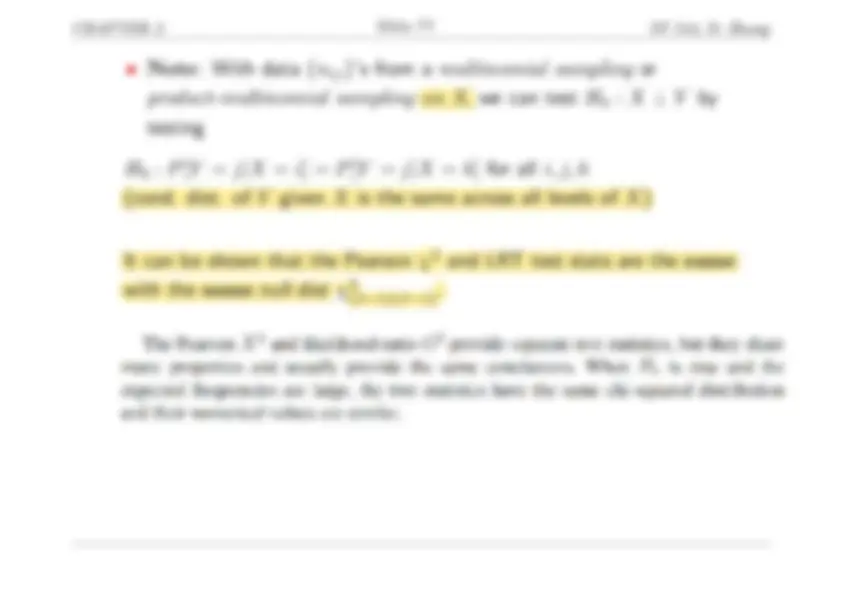
I.4 Independence of X and Y
- X and Y are random with the underlying probability structure Y 1 2 J X 1 π 11 π 12. π 1 J 2 π 21 π 22. π 2 J ..... I πI 1 πI 2. πIJ
• X ⊥ Y
⇔ P [ X =i , Y =j ] =P [ X =i ]*P [ Y =j ] f or i = 1 , 2 ,. .., I , j = 1 , 2 ,. .., J. ⇔ πij =πi+π+j f or i = 1 , 2 ,. .., I , j = 1 , 2 ,. .., J. (πi+ =πi 1 +πi 2 +. .. +πiJ , π+j =π 1 j +π 2 j +. .. +πIj ) ⇔ P [ Y =j |X =i ] =P [ Y =j |X =k] f or all i , j, k.
- When X and Y are random 2-level cat. variables, the underlying probability structure is Y 1 2 X 1 π 11 π 12 2 π 21 π 22
- X ⊥ Y ⇔ πij = πi+π+j for i, j = 1, 2 (πi+ = πi 1 + πi 2 , π+j = π 1 j + π 2 j ) We only need one of them, e.g. π 11 = π1+π+ ⇔ P [Y = 1|X = 1] = P [Y = 1|X = 2], i.e.
π 1 = (^) ππ^11 1+
= (^) ππ^21 2+
= π 2
Note that
- Estimate of π 1 − π 2 :
p 1 − p 2 = n^11 n1+
− n^21 n2+
- Estimated SE (standard error) of p1 − p 2 :
SE(p 1 − p 2 ) =
p 1 (1 − p 1 )/n1+ + p 2 (1 − p 2 )/n2+
- Large-sample (1 − α) CI for π 1 − π 2 :
p 1 − p 2 ± zα/ 2 SE(p 1 − p 2 ).
If this CI does not contain 0, we can reject H 0 : X ⊥ Y at significance level α.
Recall:
Critical value: Zα/ = qnorm(0.975) =1.
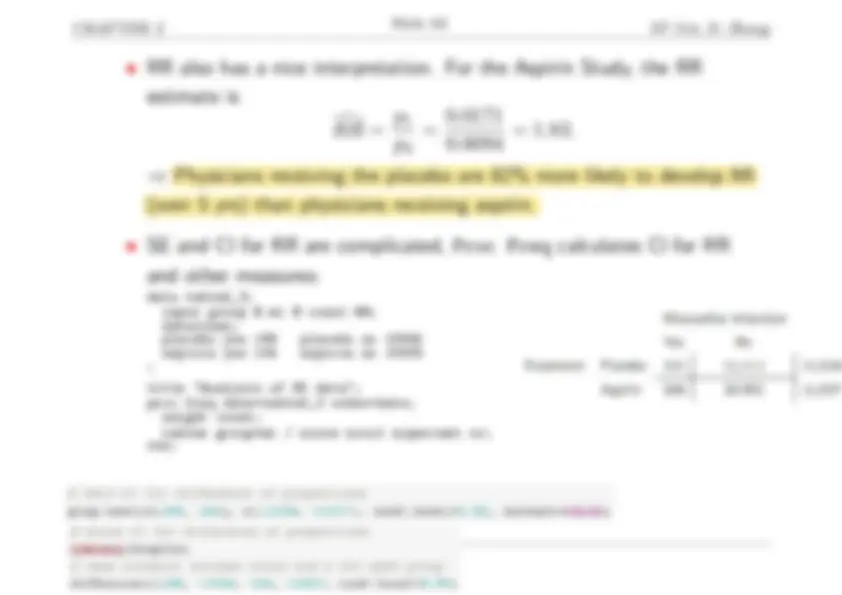
- Example: Aspirin and heart attack.
In a 5-yr study, 22,000+ physicians were randomized (blinded) to the placebo/aspirin (one tablet every other day) group: Myocardial infarction Yes No Treatment Placebo 189 10 , 845 11, Aspirin 104 10,933 11,
- Difference of MI probabilities between placebo and aspirin groups: p 1 − p 2 = 189/ 11034 − 104 /11037 = 0. 0171 − 0 .0094 = 0. 0077.
- SE =
- Large sample 95% CI of Difference of MI probabilities:
- 0077 ± 1. 96 × 0 .0015 = [0. 0048 , 0 .0106]. ⇒ Physicians in placebo group are more likely to develop MI.
(on X)
Critical value: Zα/ = qnorm(0.975) =1.