Download Problem Set 3 for CSC/ECE 506: Architecture of Parallel Computers - Prof. Gehringer and more Assignments Electrical and Electronics Engineering in PDF only on Docsity!
CSC/ECE 506: Architecture of Parallel Computers
Problem Set 3
Due April 7, 2001
[April 14 for off-campus students]
Problem 1, 4, and 5 will be graded. There are 50 points on these problems. Note: You must do all the problems, even the non-graded ones. If you do not do some of them, half as many points as they are worth will be subtracted from your score on the graded problems.
Problem 1. (15 points) In a NUMA multiprocessor, local memory references take 100 nsec. and remote references take 800 nsec. A certain program makes a total of N memory references during its execution, of which 1 percent are to a page P. That page is initially remote, and it takes C nsec. to copy it locally. Under what conditions should the page be copied locally in the absence of significant use by other processors?
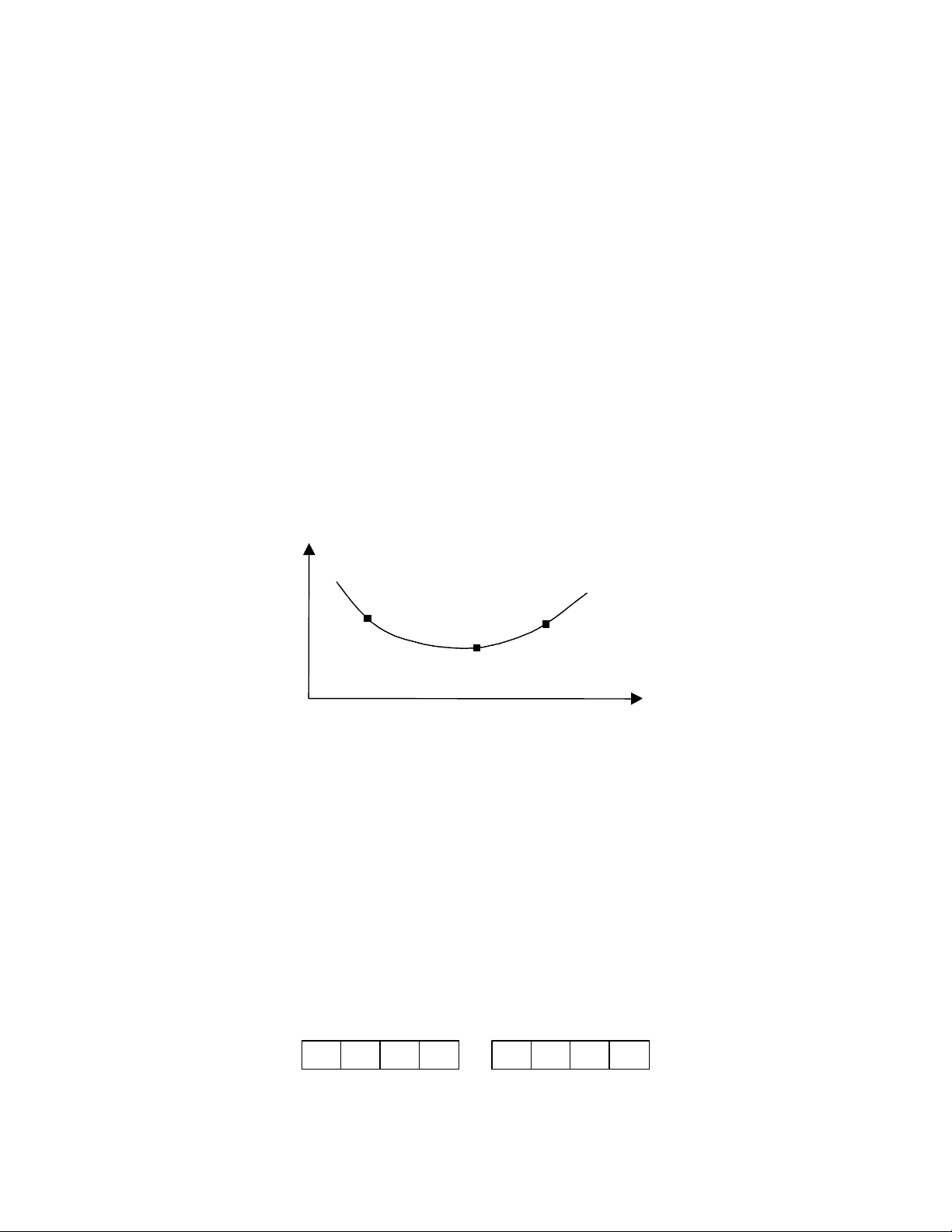
Problem 2. (10 points) [CS&G 5.2] Consider the following graph indicating the miss rate of an application as a function of cache-block size on a multiprocessor. As might be expected, the curve has a U-shaped appearance. Consider the three points A, B, and C on the curve. Indicate under what circumstances, if any, each may be a sensible operating point for the machine (i.e., the machine might give better performance at that point than at the other two points). How would you expect the shape and placement of the curve to differ for a uniprocessor?
A
B
C
Miss rate
Cache line size
Problem 3. (20 points) This problem should be solved using the MESI protocol for a bus-based shared-memory multiprocessor. Assume the following:
Direct-mapped cache organization P 1 and P 2 each have exactly 2 cache lines Cache-block size: 4 words Cache-to-cache block transfer takes 4 cycles Read/write hit (when no bus action is needed) takes 1 cycle Invalidation takes 2 cycles Memory-to-cache block transfer takes 8 cycles
B 1 and B 2 are two memory blocks that map to the same cache line. They contain the data items W, X, Y, Z, and P, Q, R, S, respectively as shown below. Each data item is one word.
W
B 1
X Y Z P
B 2
Q R S
You are given the following trace of memory accesses from two processors P 1 and P 2. Assume that the accesses occur strictly sequentially in the textual order shown at the right. Also assume that whenever a bus action is required then the time for the bus action is in addition to the time needed to satisfy the processor request (read/write).
Determine the total time needed to execute the given memory access sequence. Assume that initially the caches are empty. Clearly show the state transition for the affected cache blocks in the caches of P 1 and P 2 after each access. Whenever there is a cache miss, indicate it as one of cold-miss, coherence-miss, capacity-miss, or conflict miss. For coherence misses, indicate the ones that are due to false sharing and those due to true sharing. Assume that Q and Z are private variables for P 1.
P 1 : READ Z
P 2 : READ W
P 1 : READ W
P 1 : WRITE Z
P 2 : READ W
P 1 : READ P
P 2 : WRITE P
P 1 : READ P
P 1 : READ Q
P 2 : READ W
P 1 : WRITE Q
P 2 : READ X
P 1 : READ R
Problem 4. (15 points) [CS&G 5.9] Consider the following conditions proposed as sufficient conditions for SC
ÿ Every process issues memory requests in the order specified by the program. ÿ After a read or write operation is issued, the issuing process waits for the operation to complete before issuing its next operation. ÿ Before a processor Pj can return a value written by another processor PI , all operations that were performed with respect to PI before it issued the store must also be performed with respect to Pj.
Are these conditions indeed sufficient to guarantee SC executions? If so, say why. If not, construct a counterexample, and say why the conditions that were listed in the chapter are indeed sufficient in that case. Hint: Think about how these conditions are different from the ones in the chapter.
Problem 5. (20 points) [Hwang & Briggs, 2.6] A certain uniprocessor computer system has a paged segemented virtual memory system and also a cache. The virtual address is a triple ( s , p , d ) where s is the segment number, p is the page within s , and d is the displacement within p. A translation lookaside buffer (TLB) is used to perform the address translation when the virtual address is in the TLB. If there is a miss in the TLB, the translation is performed by accessing the segment table and then a page table, either or both of which may be in the cache or in main memory (MM).
Address translation via the TLB requires one clock cycle. A fetch from the cache requires two clock cycles (one clock cycle to determine if the requested address is in the cache plus one clock cycle to read the data). A read from MM requires eight clock cycles. There is no overlap between TLB translation and cache access. Once the address translation is complete, the read of the desired data may be from either the cache or MM. This means that the fastest possible data access requires three clock cycles: one for TLB address translation and two to read the data from the cache. There are nine other ways in which a read can proceed, all requiring more than three clock cycles.
(a) Assuming a TLB hit ratio of 0.9 and a cache hit ratio of h , enumerate all ten possible read patterns, the time taken for each, and the probability of occurrence for each pattern. What is the average read time in the system? (Assume that when a word is fetched from memory, a read- through policy is used).
To get you started, here are the first three possibilities. “H” stands for “hit” and “M” for “miss.”