



























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
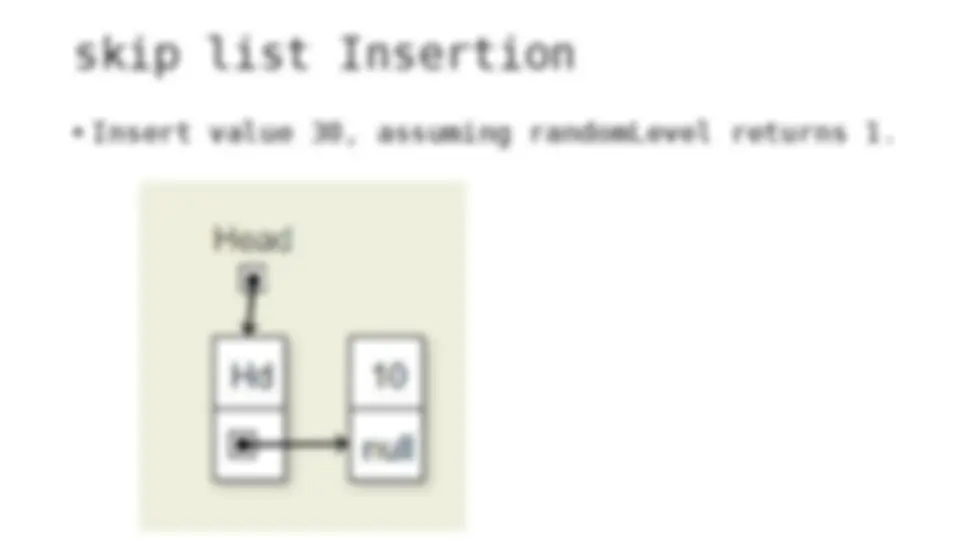
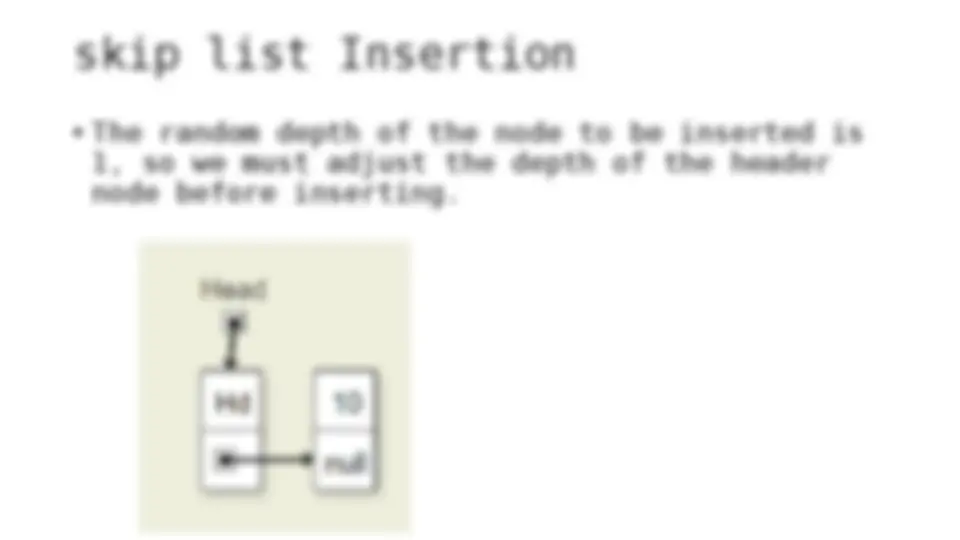
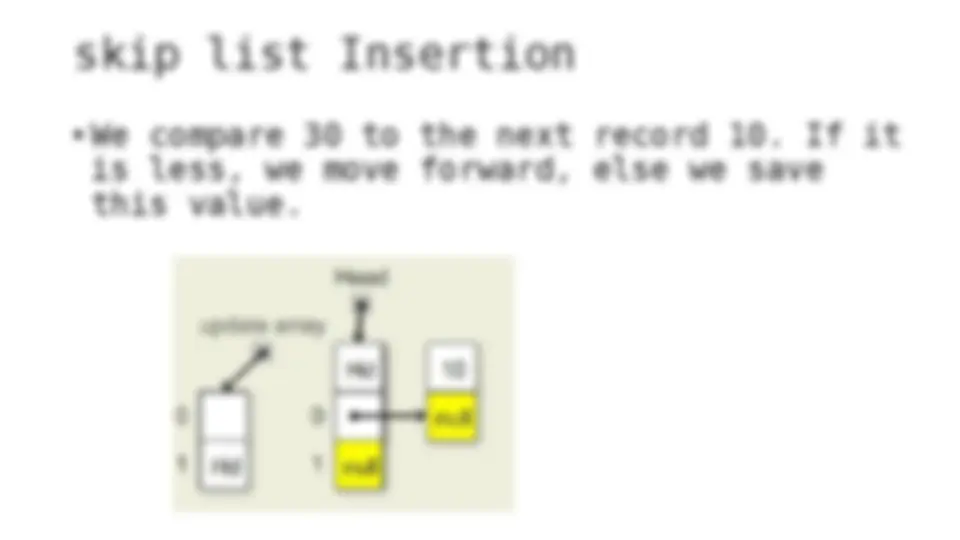
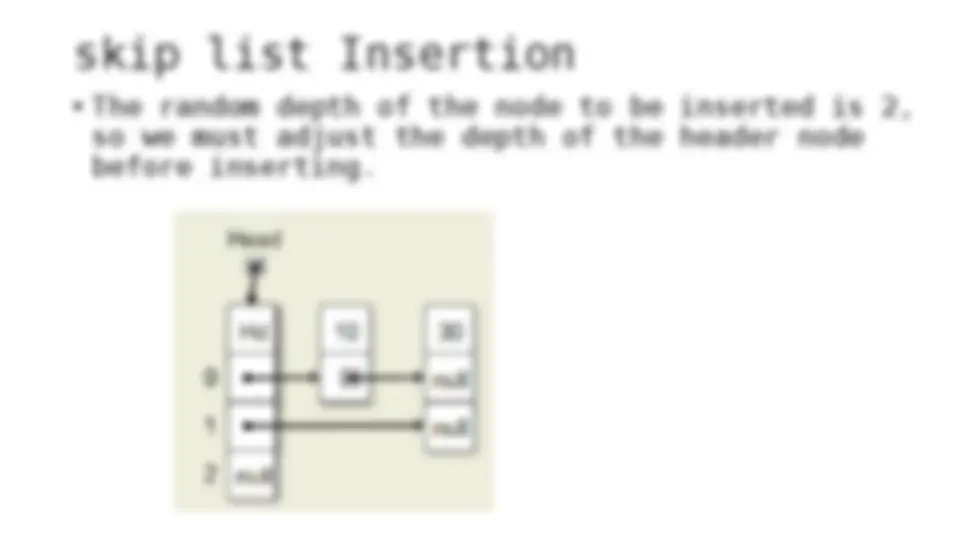
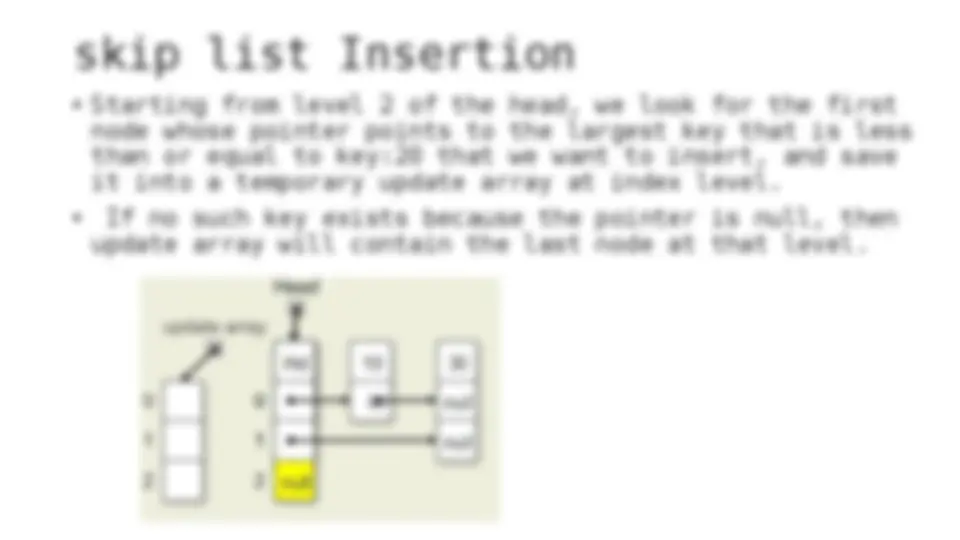
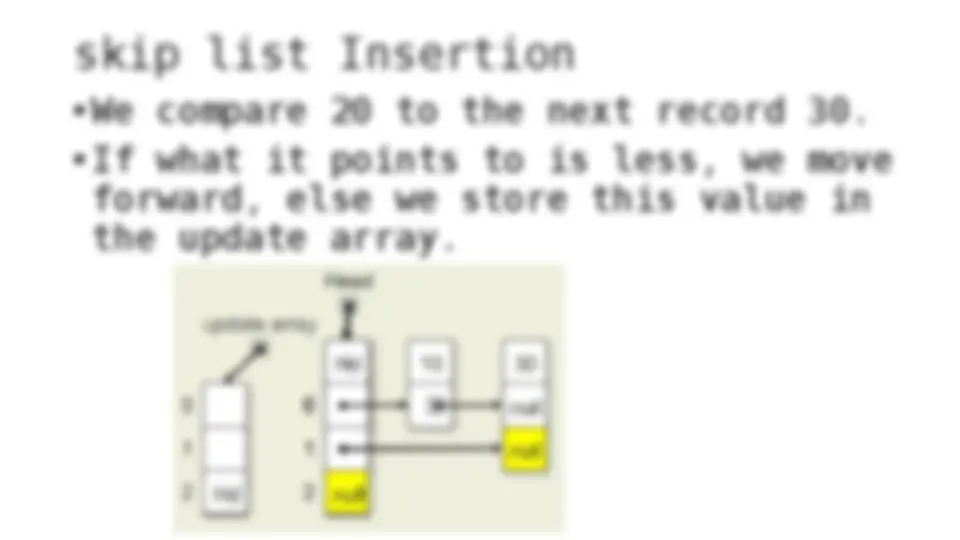
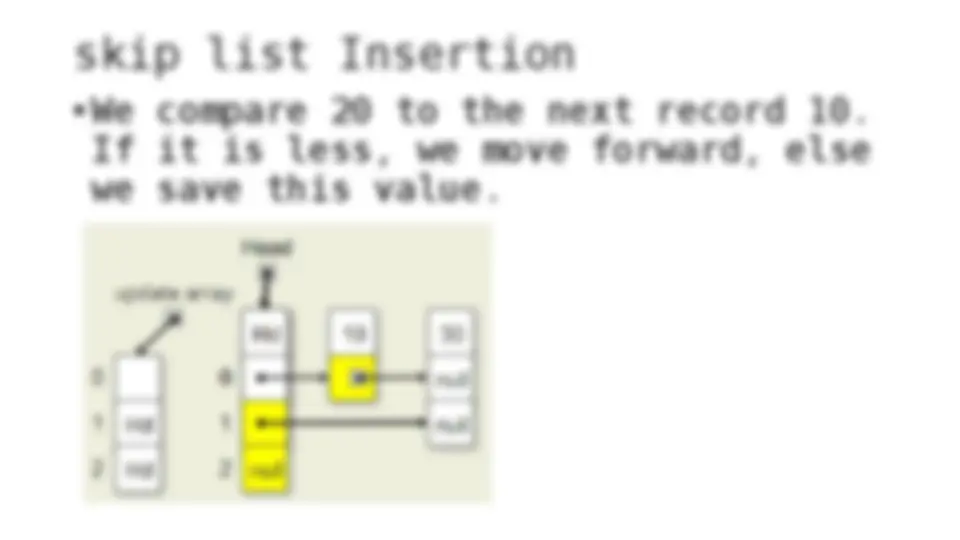
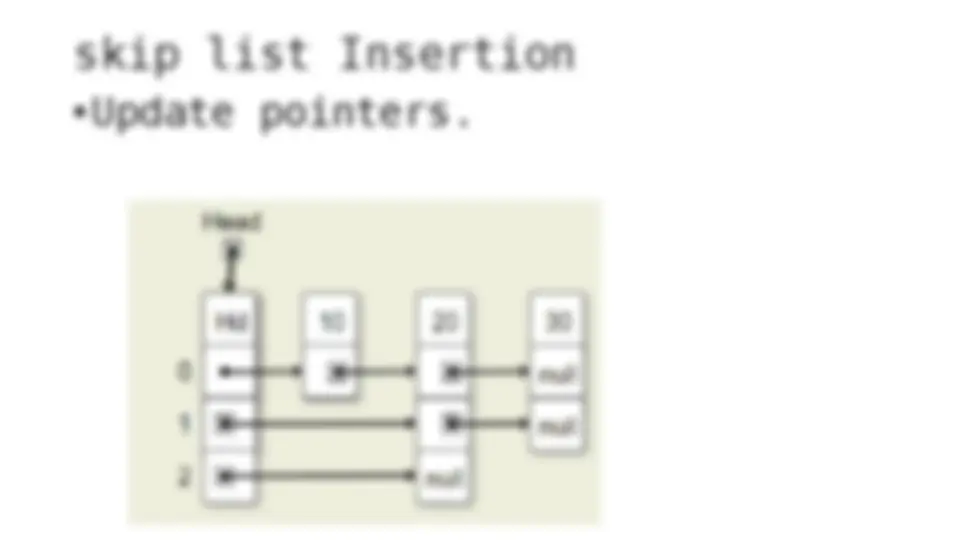
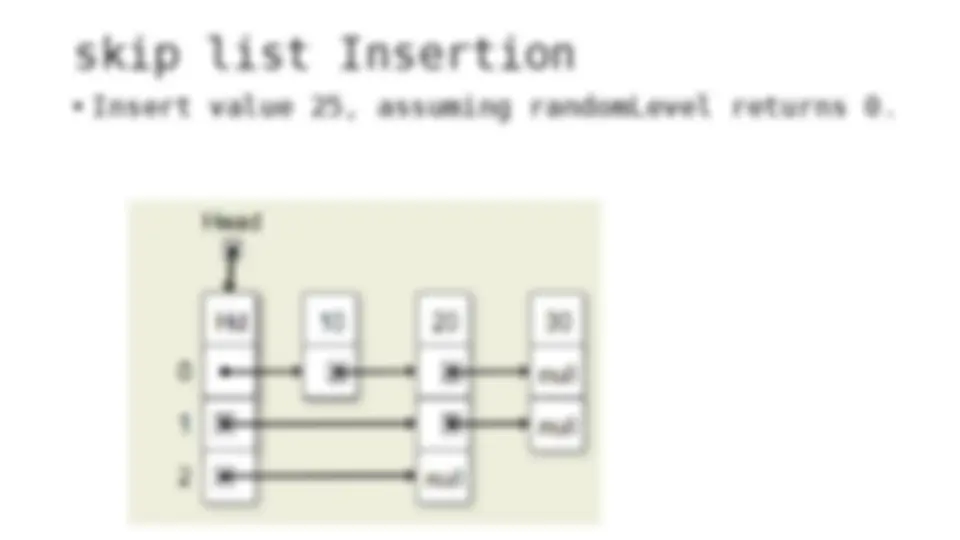
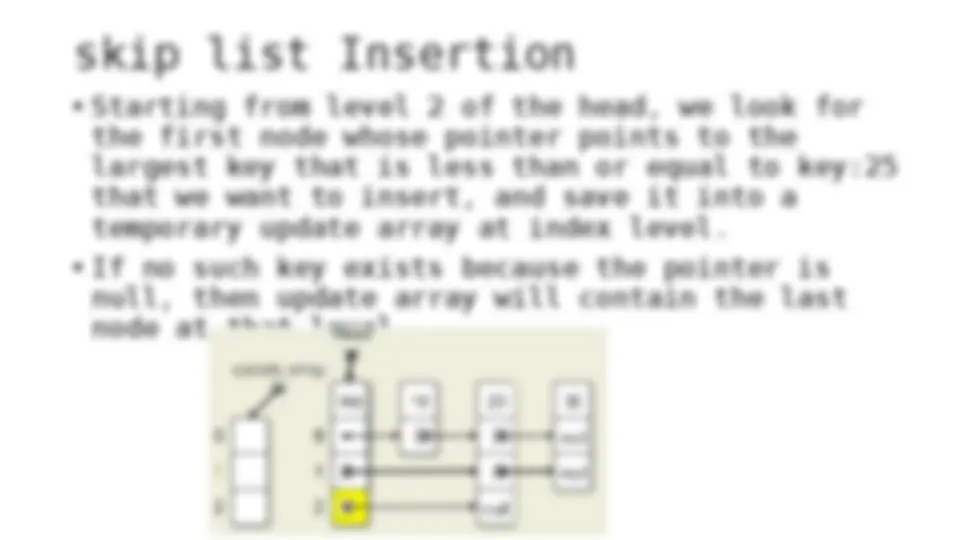
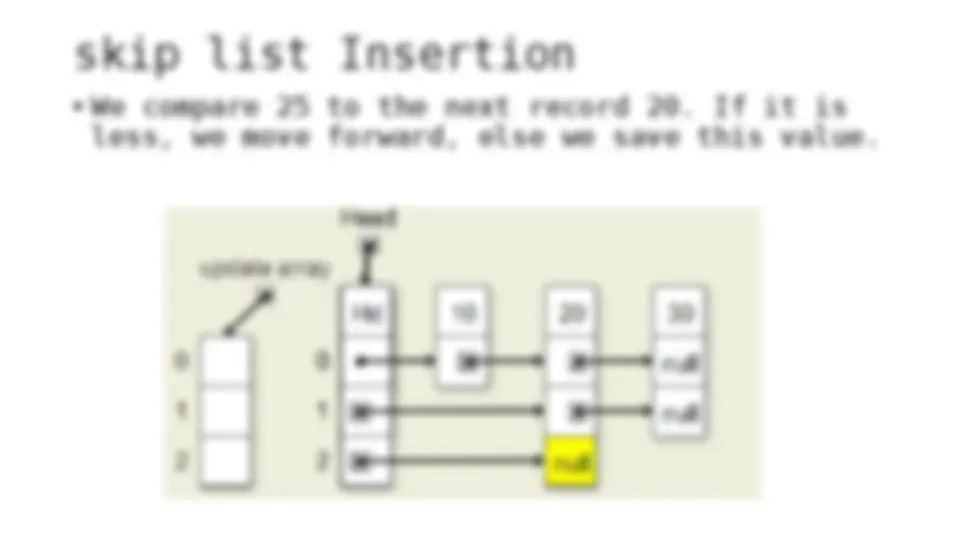
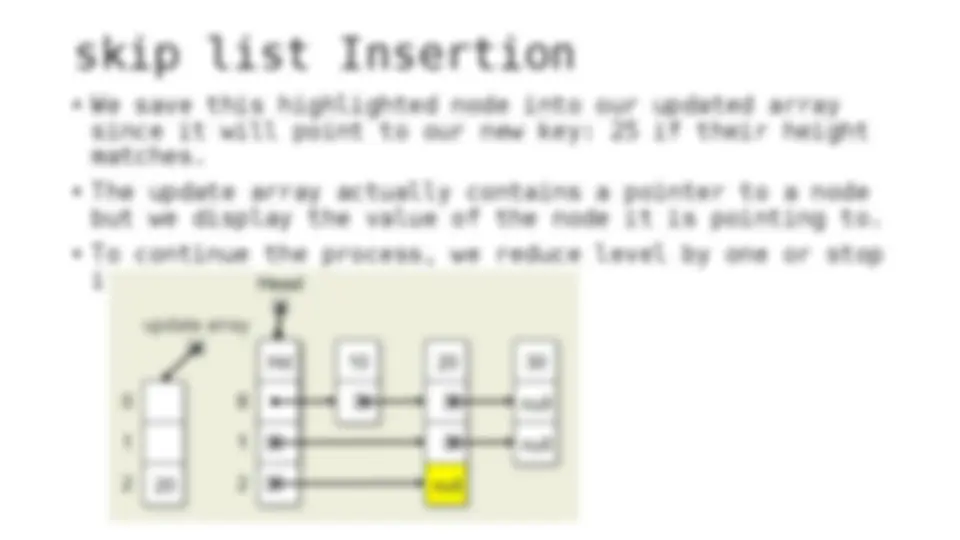
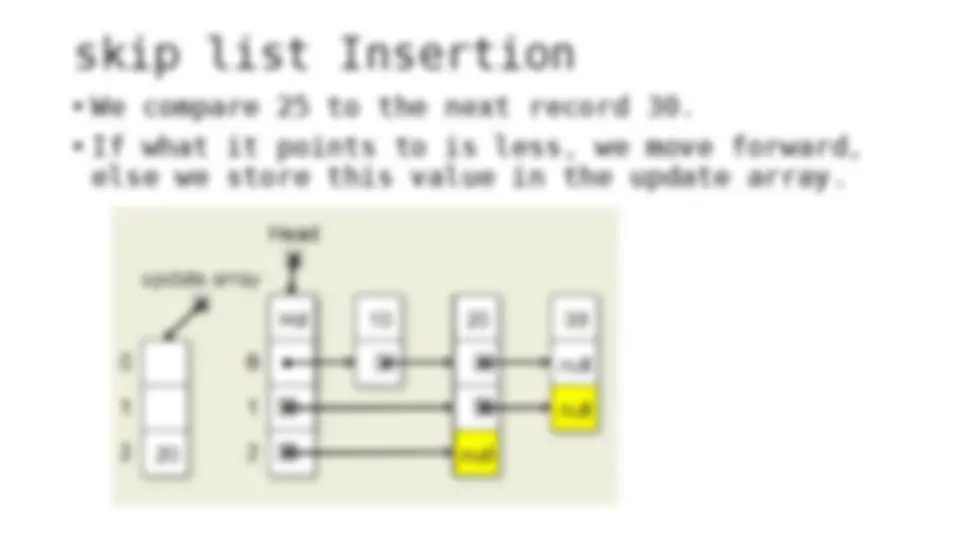
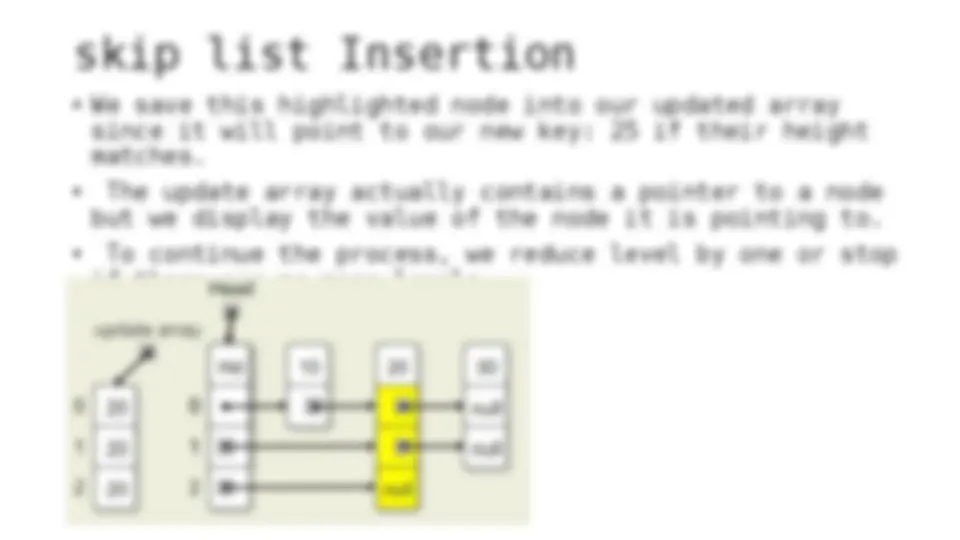
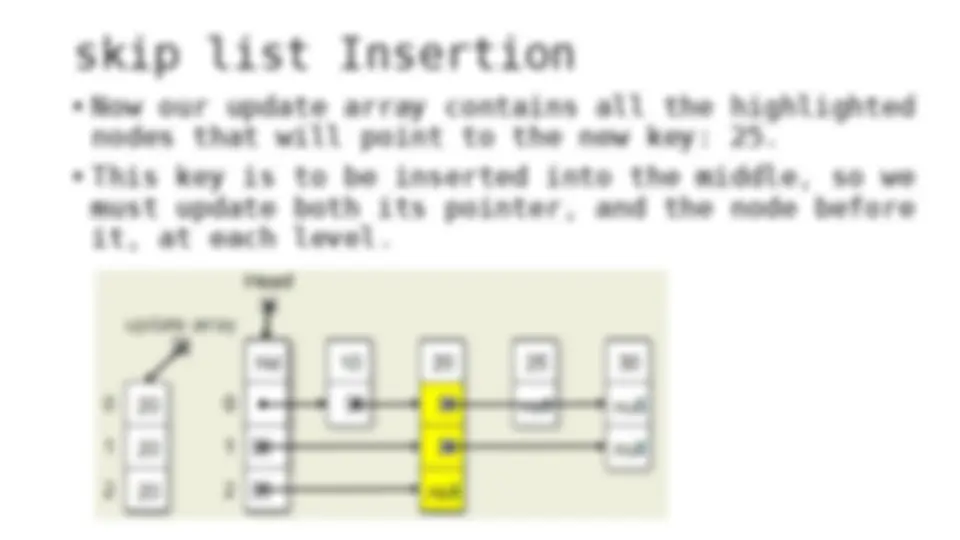
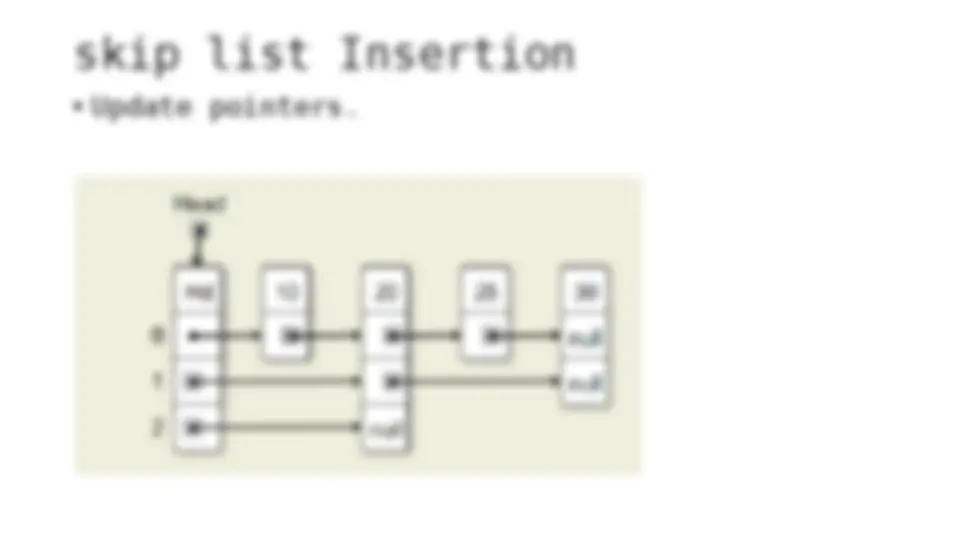
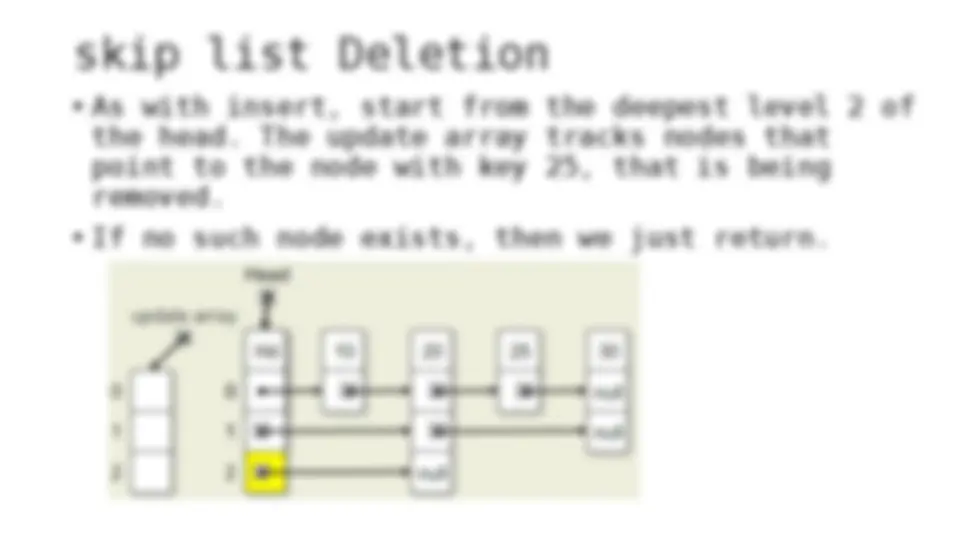
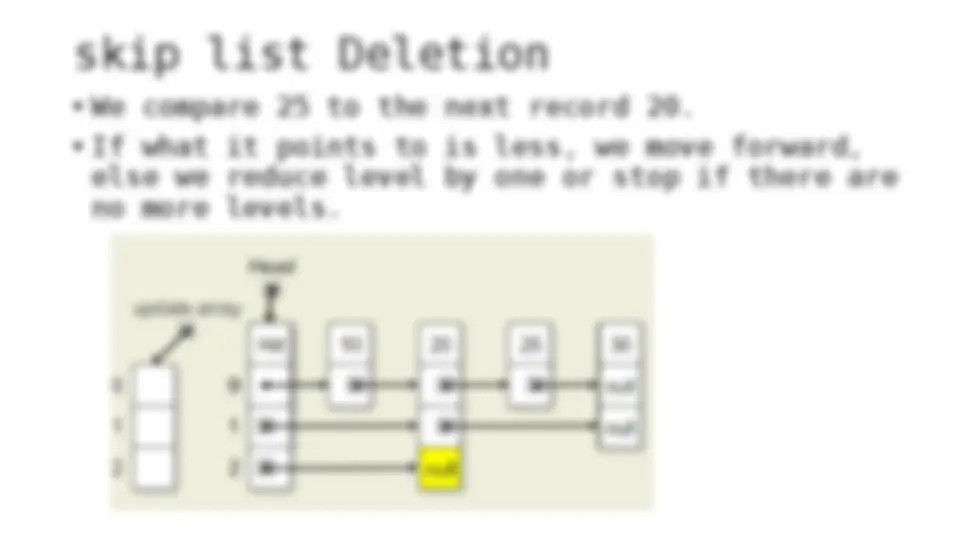
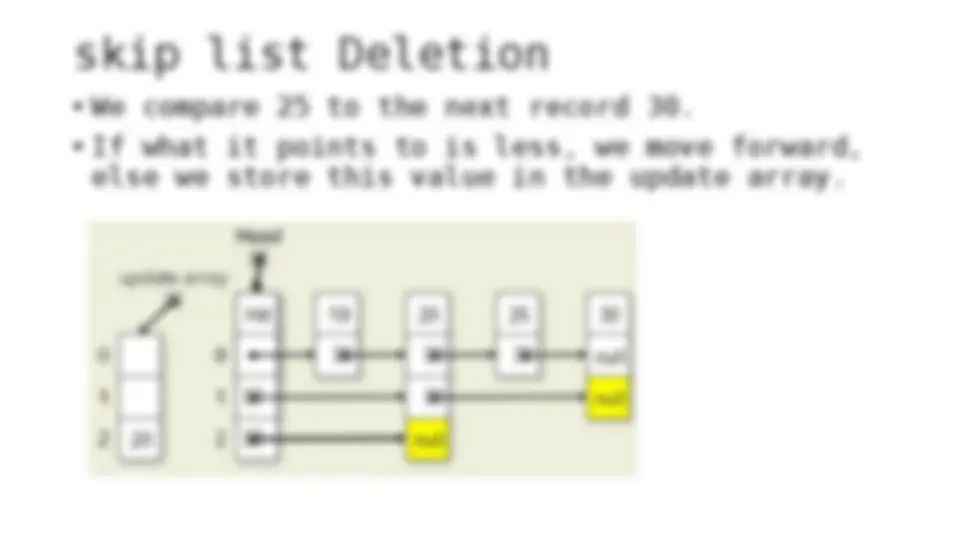
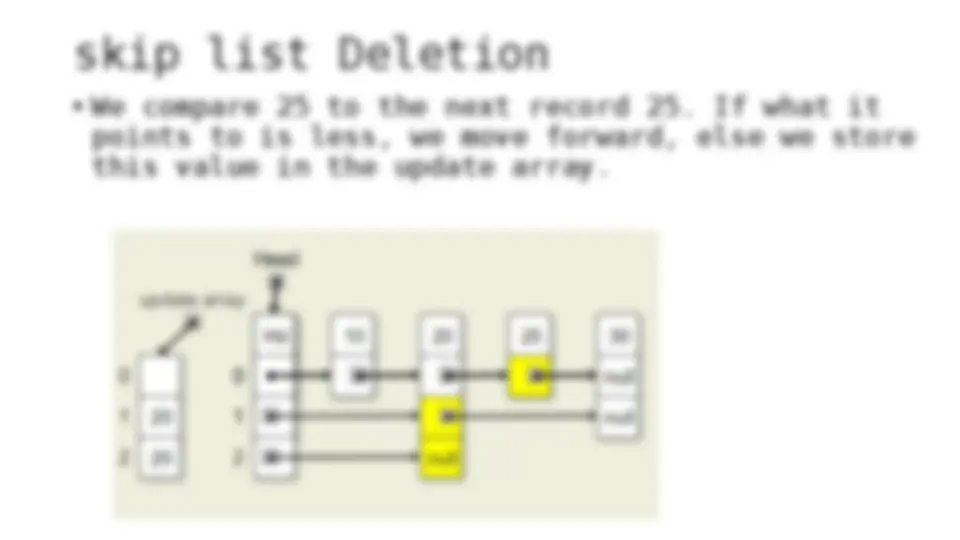
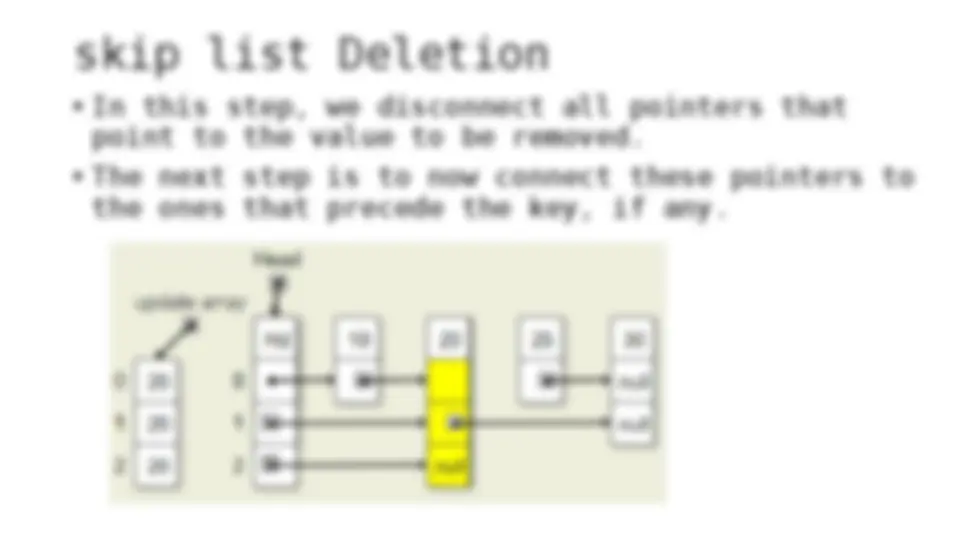
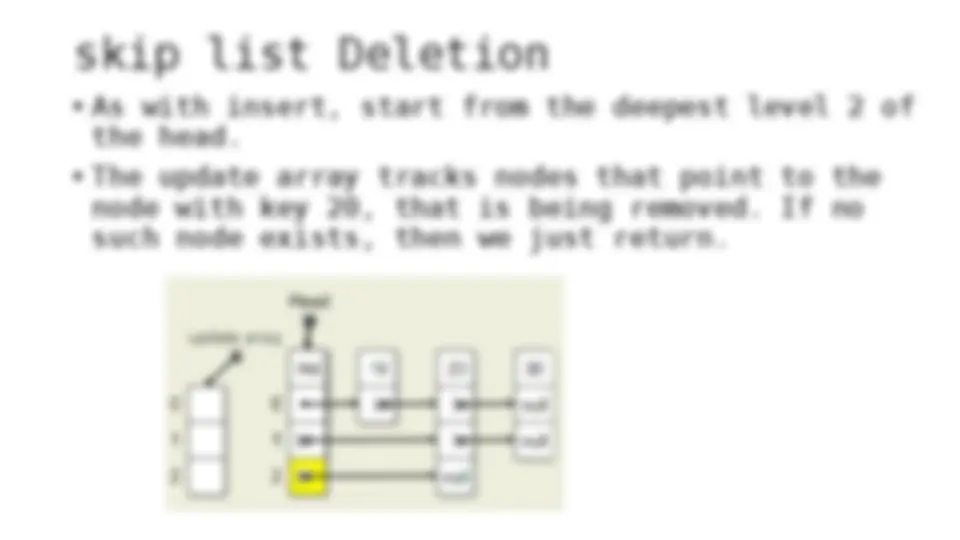
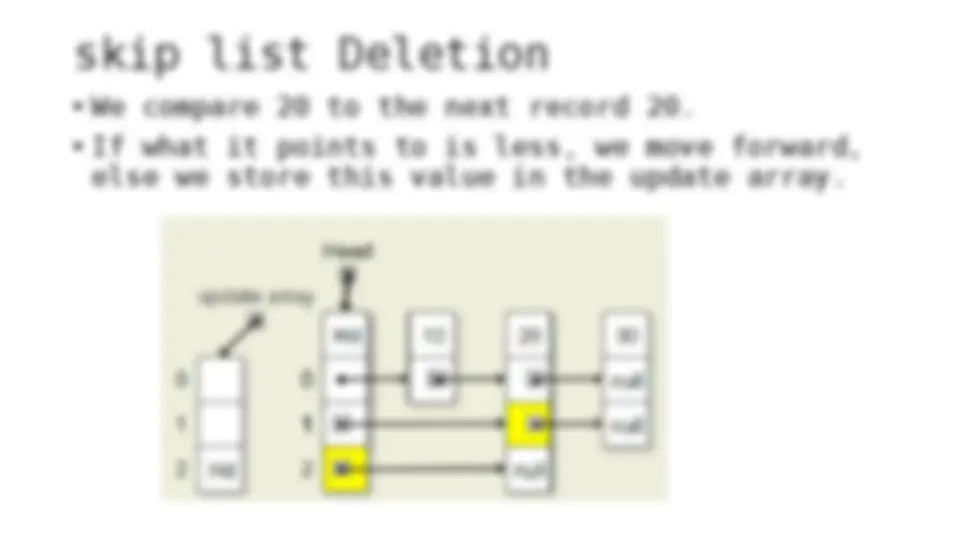
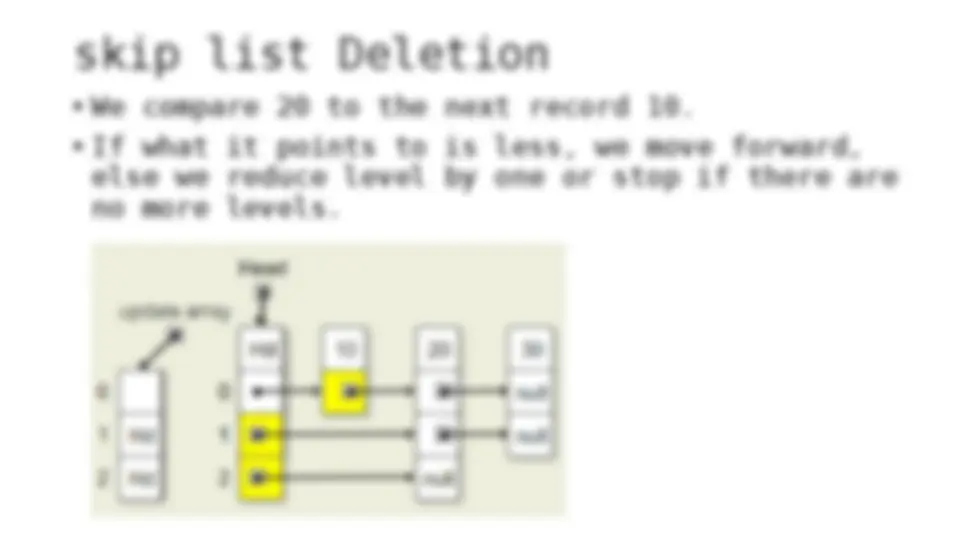
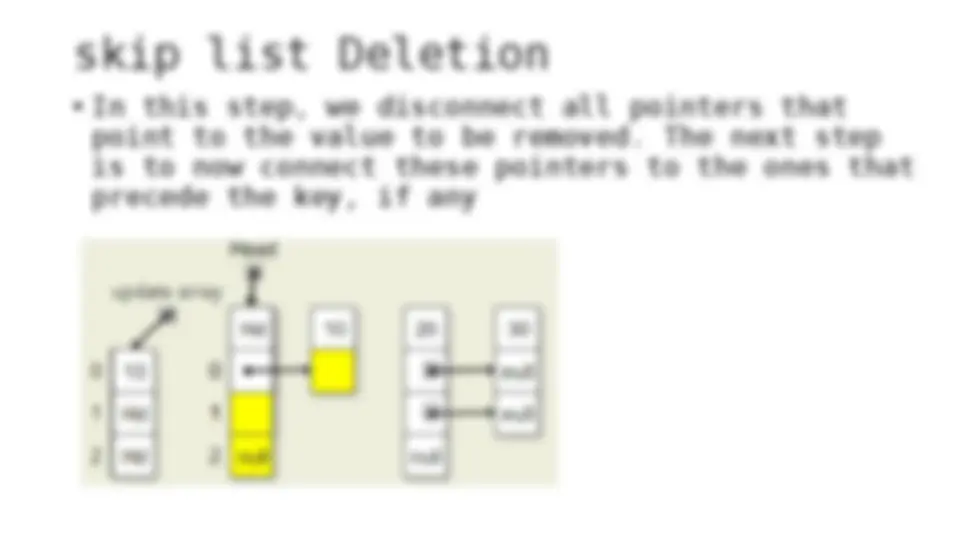
The process of inserting and deleting keys in a skip list. A skip list is a probabilistic data structure that allows fast search within an ordered sequence of elements. The algorithm starts by initializing the skip list with a header node and then inserts or deletes keys by updating the pointers of the nodes at each level. The random depth of the node to be inserted or deleted determines the number of levels that need to be adjusted.
Typology: Lecture notes
1 / 56

This page cannot be seen from the preview
Don't miss anything!