


Skip List: Implementation
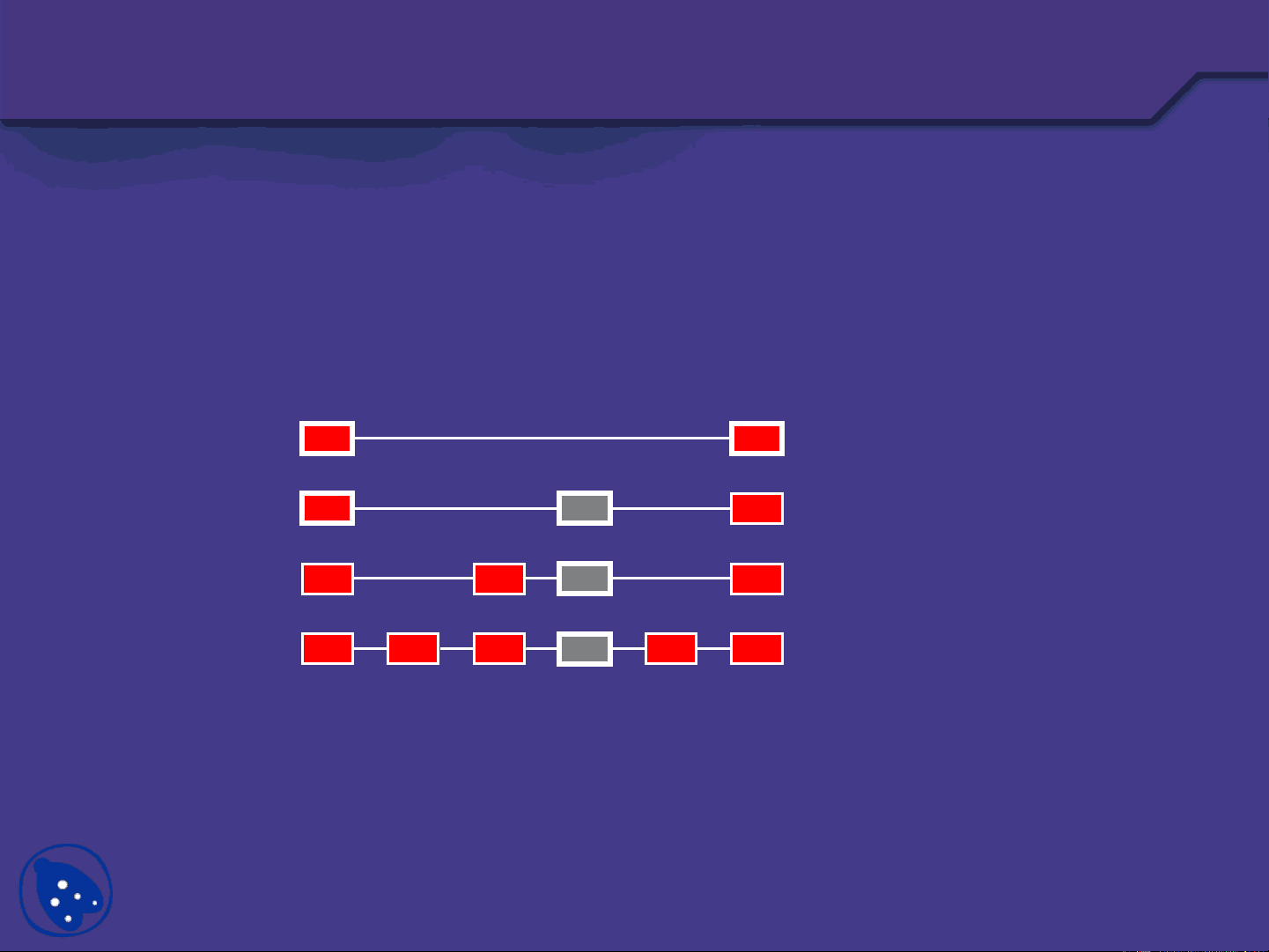
−∞ +∞
S0
S1
S2
S3
−∞ +∞
45 12 23 34
−∞ +∞
34
−∞ +∞
23 34
Docsity.com







Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Skip List Implementation, Implementation TowerNode, Implementation QuadNode, Skip Lists with Quad Nodes, Performance of Skip Lists, Hashing, Finding the hash function are some of data structures topics and terms you will learn in these lecture slides.
Typology: Slides
1 / 17

This page cannot be seen from the preview
Don't miss anything!
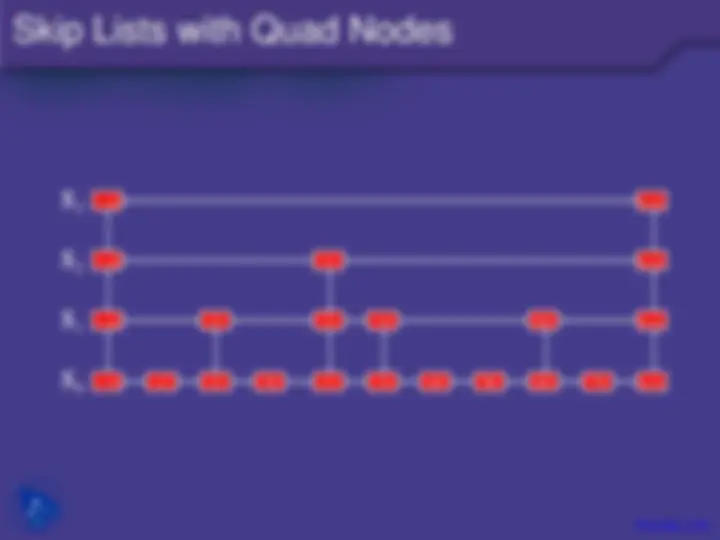
−∞ +∞
S 0
S 1
S 2
S 3
−∞ 12 23 34 45 +∞
−∞ 34 +∞ −∞ 23 34 +∞
TowerNode will have array of next pointers. Actual number of next pointers will be decided by the random procedure. Define MAXLEVEL as an upper limit on number of levels in a node.
40 50 60
head (^) tail
20 26 30 57
Tower Node
−∞ 12 23 26 31 34 44 56 64 78 +∞
−∞ +∞
−∞^31 +∞
−∞ 23 31 34 64 +∞
S 0
S 1
S 2
S 3
In a skip list with n items
So far we have find, remove and insert where time varies between constant log n.
It would be nice to have all three as constant time operations!
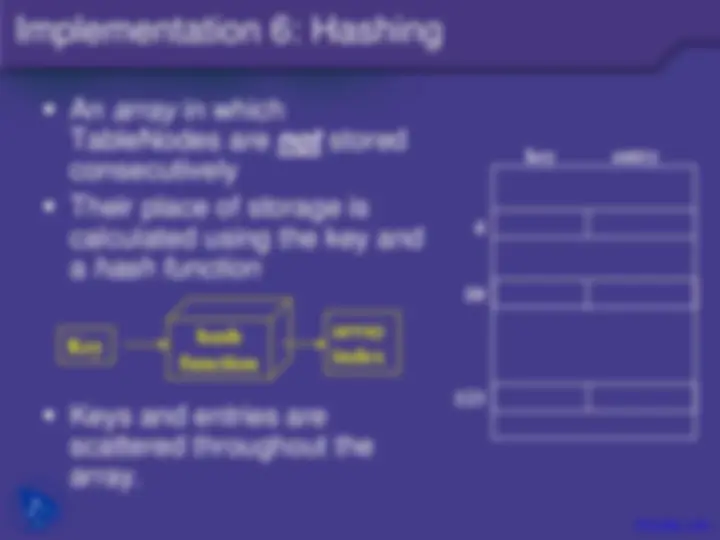
An array in which TableNodes are not stored consecutively Their place of storage is calculated using the key and a hash function
Keys and entries are scattered throughout the array.
key entry
Key (^) functionhash^ arrayindex
4
10
123
We use an array of some fixed size T to hold the data. T is typically prime.
Each key is mapped into some number in the range 0 to T-1 using a hash function , which ideally should be efficient to compute.
Suppose our hash function gave us the following values: hashCode("apple") = 5 hashCode("watermelon") = 3 hashCode("grapes") = 8 hashCode("cantaloupe") = 7 hashCode("kiwi") = 0 hashCode("strawberry") = 9 hashCode("mango") = 6 hashCode("banana") = 2
kiwi
banana watermelon
apple mango cantaloupe grapes strawberry
0 1 2 3 4 5 6 7 8 9
table["apple"] table["watermelon"] table["grapes"] table["cantaloupe"] table["kiwi"] table["strawberry"] table["mango"] table["banana"]
kiwi
banana watermelon
apple mango cantaloupe grapes strawberry
0 1 2 3 4 5 6 7 8 9
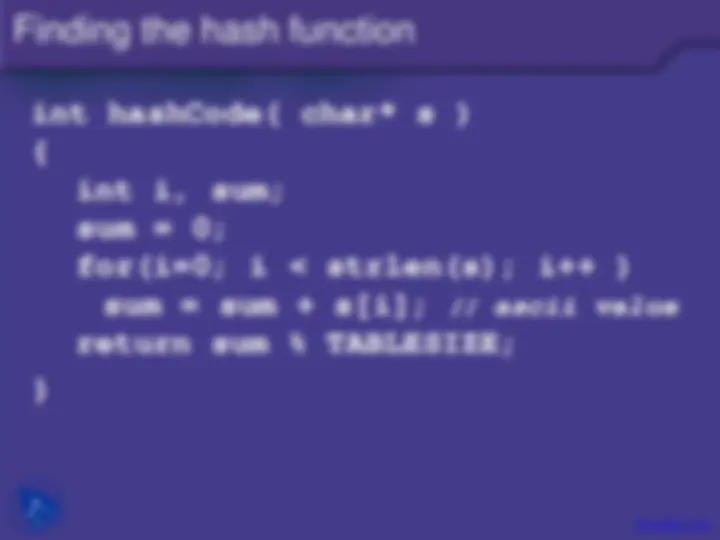
If the keys are strings the hash function is some function of the characters in the strings. One possibility is to simply add the ASCII values of the characters:
Example h ABC TableSize
h str str i TableSize
length
i : ( ) ( 65 66 67 )%
( ) [ ] %
1
0 = + +
−
=
Another possibility is to convert the string into some number in some arbitrary base b ( b also might be a prime number):
Example h ABC b b b T
h str str i b T
length
i
i
: ( ) ( 65 66 67 )%
( ) [ ] %
0 1 2
1
0 = + +
−
=
If the keys are integers then key%T is generally a good hash function, unless the data has some undesirable features. For example, if T = 10 and all keys end in zeros, then key%T = 0 for all keys. In general, to avoid situations like this, T should be a prime number.