



Artificial Intelligence
(part 4d)
BEHAVIOR OF HEURISTICS EVALUATIONS
(USING HEURISTICS IN GAMES)













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Artificial Intelligence part 4 d
Typology: Lecture notes
1 / 25

This page cannot be seen from the preview
Don't miss anything!
BEHAVIOR OF HEURISTICS EVALUATIONS
A search is admissible if it is guaranteed to find a minimal path to a solution whenever such a path exists Recall… f(n) = g(n) + h(n) estimates the total cost of path from start state through n to the goal state
g(n) start (^) goal f(n)=total cost
n
h(n)
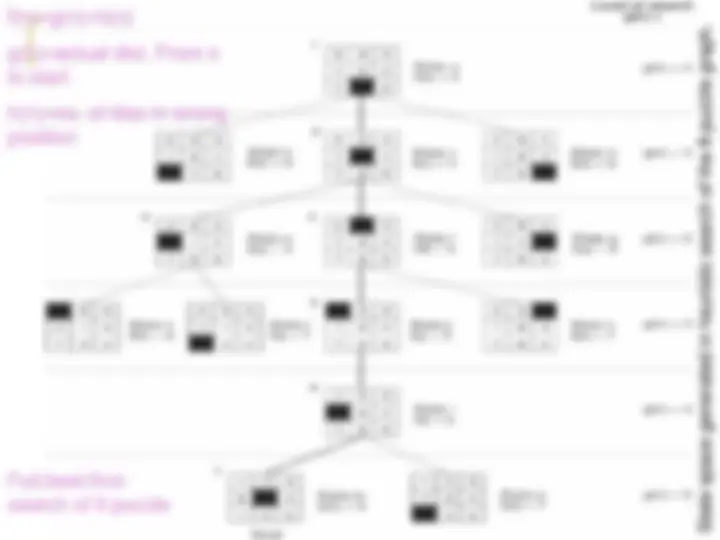
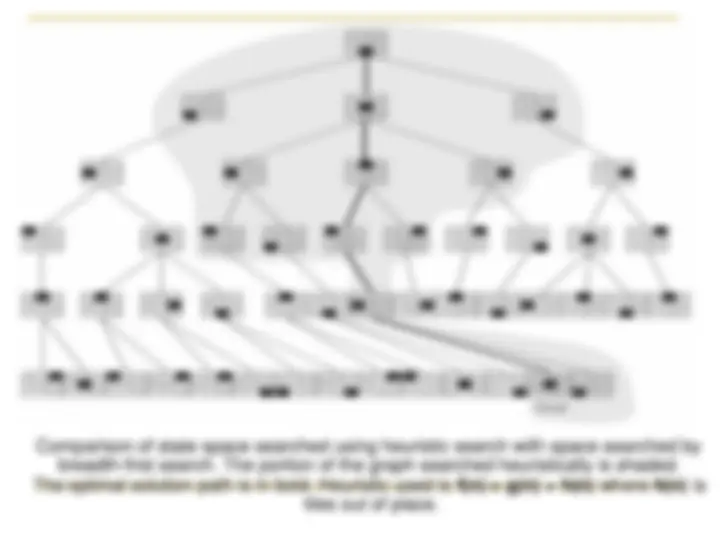
State space generated in heuristic search of the 8-puzzle graph
f(n)=g(n)+h(n).
g(n)=actual dist. From n to start
h(n)=no. of tiles in wrong position
Full best-first- search of 8 puzzle
Informed Heuristics
Heuristics in Games
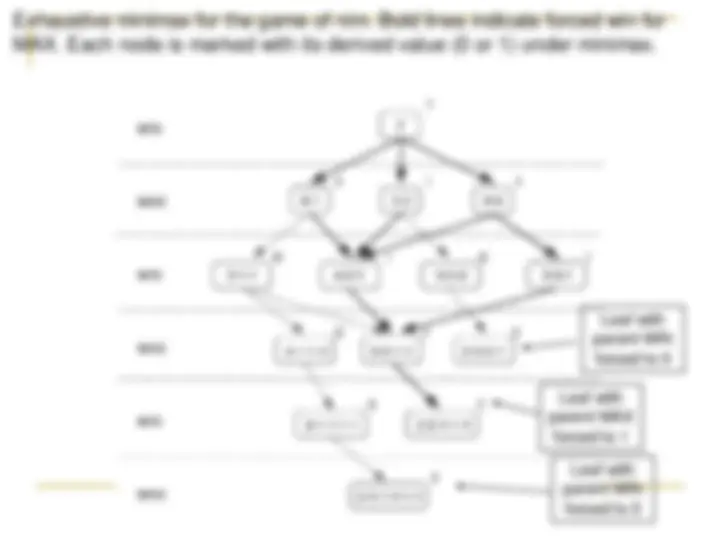
State space for a variant of nim. Each state partitions the seven matches into one or more piles.
Exhaustive minimax for the game of nim. Bold lines indicate forced win for MAX. Each node is marked with its derived value (0 or 1) under minimax.
Leaf with parent MIN forced to 0
Leaf with parent MIN forced to 0
Leaf with parent MAX forced to 1
Minimaxing to fixed Ply depth
States on that ply are measured heuristically, the values are propagated back up using minimax, Search algo uses these values to select possible next moves
Figure 4.16:
Heuristic measuring conflict applied tostates of tic-tac-toe.
FIXED FLY DEPTH: Two-ply minimax applied to the opening move of tic-tac-toe, from Nilsson (1971).
Step1:expand the tree Step2:calculate heuristic for level n Step3:derived values for n- 1(propogate values back-up)
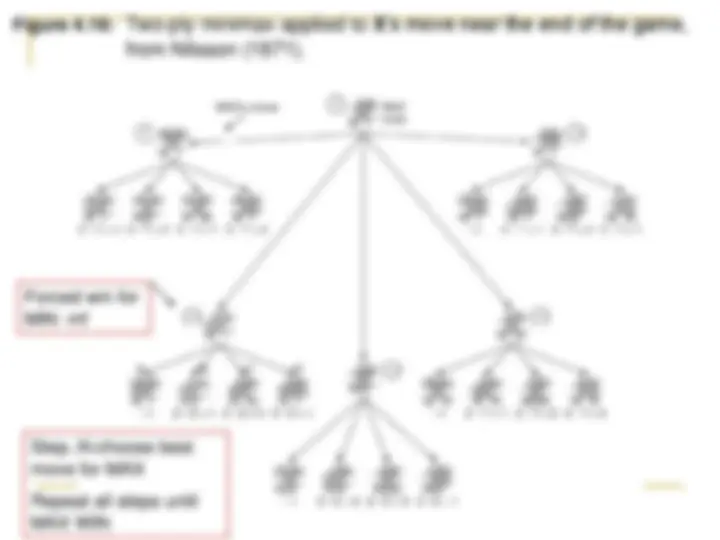
Figure 4.19: Two-ply minimax applied to X ’s move near the end of the game, from Nilsson (1971).
Forced win for MIN -inf
Step..N:choose best move for MAX Repeat all steps until MAX WIN
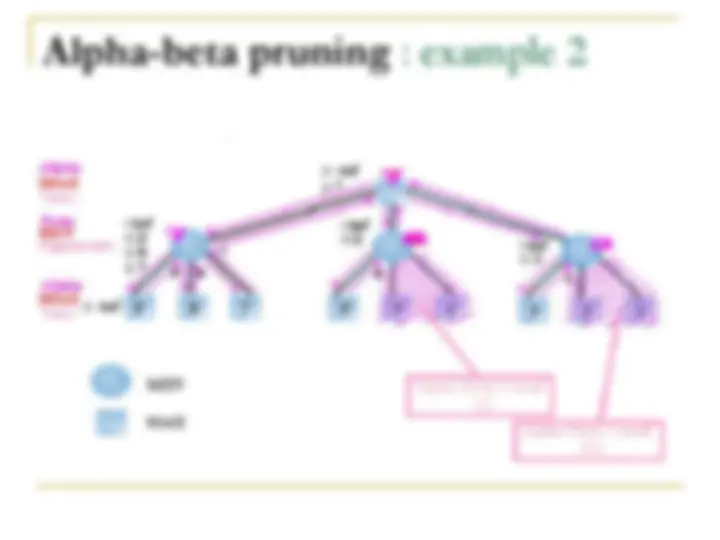
Alpha-beta pruning
To improve search efficiency in two-person games (compared to minimax that always pursues all branches in state space)
Alpha-beta search in depth-first fashion
Alpha(α) and beta(β) values are created
α associates with MAX-never decrease
β associates with MIN-never increase
How?
Expand to full-ply Apply heuristic evaluation to a state and its siblings Back-up to the parent The value is offered to grantparent as a potential α or β cutoff