Download Basic Communication Operations-Parallel Computing-Lecture Slides and more Slides Parallel Computing and Programming in PDF only on Docsity!
Lecture OutlineIntroduction
4.1 One-to-All Broadcast and All-to-One Reduction4.2 All-to-All Broadcast and Reduction4.3 All-Reduce and Prefix-Sum Operations4.4 Scatter and Gather4.5 All-to-All Personalized Communication4.6 Circular Shift4.7 Improving the Speed of Some Communication
Operation 4.8 Summary
Basic CommunicationOperations: Introduction (1/2)
^
Many interactions in practical parallel programs occur inwell-defined patterns involving groups of processors. ^
Efficient implementations of these operations canimprove performance, reduce development effort andcost, and improve software quality. ^
Efficient implementations must leverage underlyingarchitecture. For this reason, we refer to specificarchitectures here. ^
We select a descriptive set of architectures to illustratethe process of algorithm design.
4.1 One-to-All Broadcast andAll-to-One Reduction (1/2)
One processor has a piece of data (of size
m
) it
needs to send to everyone.
The dual of one-to-all broadcast is
all-to-one
reduction
In all-to-one reduction, each processor has
m
units
of data. These data items must be combined piece-wise (using some associative operator, such asaddition or min), and the result made available at atarget processor.
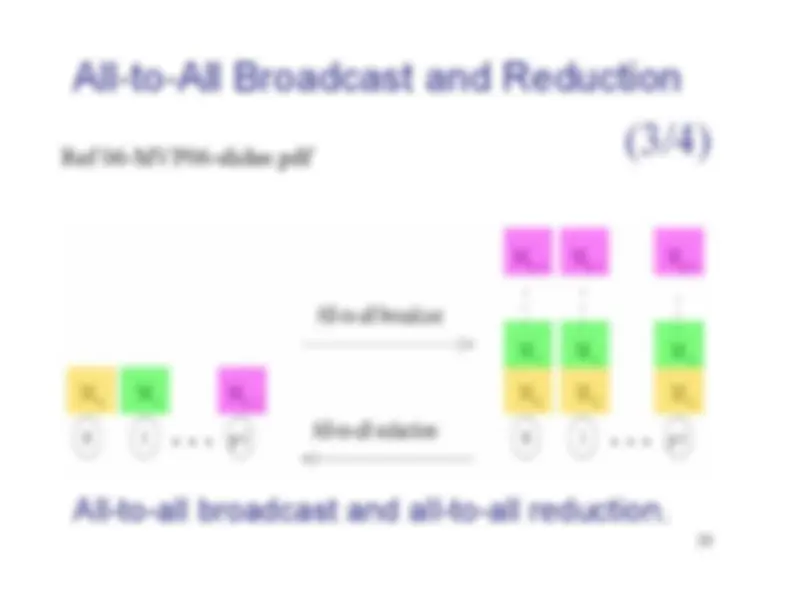
One-to-All Broadcast and All-to-One Reduction (2/2)One-to-all broadcast and all-to-one reduction among
processors.
One-to-All Broadcast on Rings(2/3)
Recursive doubling
^
use logical binary tree for broadcasting ^
make sure to minimize congestion ^
complexity:
(t
+ts^
wm
)logp
p^0
p^1
p 2
p^3
p 4
p^5
p 6
p^7
p^0
p^1
p 2
p^3
p 4
p^5
p 6
p^7
Which better?
Ref CommImpl1.ppt
One-to-All Broadcast on Rings
One-to-all broadcast on an eight-node ring. Node 0 is thesource of the broadcast. Each message transfer step is shownby a numbered, dotted arrow from the source of the messageto its destination. The number on an arrow indicates the timestep during which the message is transferred.
All-to-One Reduction on Rings
Reduction on an eight-node ring with node 0 as thedestination of the reduction.
Broadcast and Reduction onRings : Example (1/2)
Consider the problem of multiplying a matrix with a vector. ^
The
n
x
n
matrix is assigned to an
n
x
n
(virtual) processor grid.
The vector is assumed to be on the first row of processors. ^
The first step of the product requires a one-to-all broadcast of thevector element along the corresponding column of processors.This can be done concurrently for all
n
columns.
^
The processors compute local product of the vector element andthe local matrix entry. ^
In the final step, the results of these products are accumulated tothe first row using
n
concurrent all-to-one reduction operations
along the columns (using the sum operation).
4.1.2 Broadcast and Reduction ona Mesh (1/2)
Each row and column of mesh is a ring!
p
nodes
Two phases
^
Ring broadcast in row of initiating node ^
Ring broadcast in all columns from row of initiatingnode
Similar
(n phase)
procedure works on
nD
mesh
Matrix Vector product
^
n*n
matrix,
n*
vector,
n*n
mesh
Broadcast and Reduction on a
Mesh: Example
One-to-all broadcast on a 16-node
mesh.
Broadcast and Reduction on a
Hypercube: Example
One-to-all broadcast on a three-dimensional hypercube.The binary representations of node labels are shown inparentheses.
4.1.4 Broadcast and Reduction ona Balanced Binary Tree (1/2)
Consider a binary tree in which processors are(logically) at the leaves and internal nodes arerouting nodes.
Assume that source processor is the root of thistree. In the first step, the source sends the data tothe right child (assuming the source is also theleft child). The problem has now beendecomposed into two problems with half thenumber of processors.
4.1.4 Broadcast and ReductionAlgorithms (1/3)
All of the algorithms described above areadaptations of the same algorithmic template.
We illustrate the algorithm for a hypercube, butthe algorithm, as has been seen, can be adaptedto other architectures.
The hypercube has
^2
d^
nodes and
my_id
is the
label for a node.
X
is the message to be broadcast, which initially
resides at the source node 0.
Broadcast Algorithm
One-to-all broadcast of a message X from source on ahypercube.