Download Programming Using the Message Passing Paradigm-Parallel Computing-Lecture Slides and more Slides Parallel Computing and Programming in PDF only on Docsity!
Dr. Hanif Durad
2
Lecture Outline
^ Principles of Message-Passing Programming ^ The Building Blocks: Send and Receive Operations ^ MPI: the Message Passing Interface ^ Topologies and Embedding ^ Overlapping Communication with Computation ^ Collective Communication and Computation Operations ^ Groups and Communicators
6.1 Principles of Message-PassingProgramming (1/3)
^ The paradigm is one of the oldest and most widely usedapproaches for programming parallel computers.
^ its roots can be traced back in the early days of parallel proc. ^ its wide-spread adopted ^ There are two key attributes that characterize theparadigm.
^ Assumes a partitioned address space and ^ It supports only explicit parallelization
PC5.pdf
Principles of Message-PassingProgramming (3/3)
^ Advantage of explicit two-way interactions:
^ the programmer is fully aware of all the costs of nonlocalinteractions, and is more likely to think about algorithms(and mappings) that minimize interactions. ^ paradigm can be efficiently implemented on a widevariety of architectures.
^ Disadvantage:
^ For dynamic and/or unstructured interactions thecomplexity of the code written for this type of paradigmcan be very high for this reason.
Programming Issues (1/5)
^ Parallelism is coded explicitly by the programmer:
^ The programmer is responsible:
^ for analyzing the underlying serial algorithm/application and ^ Identifying ways by which he/she can decompose thecomputations and extract concurrency. ^ Programming using the paradigm tends to be hard andintellectually demanding. ^ Properly written message-passing programs can oftenachieve very high performance and scale to a very largenumber of processes.
Dr. Hanif Durad
Programming Issues (3/5)
^ Loosely synchronous programs:
^ tasks or subsets of tasks synchronize to performinteractions ^ between these interactions, tasks executecompletely asynchronously ^ Since the interaction happens synchronously, it isstill quite easy to reason about the program
8
Dr. Hanif Durad
Programming Issues (4/5)
^ Paradigm supports execution of a differentprogram on each of the
p^
processes.
^
provides the ultimate flexibility in parallelprogramming
^
makes the job of writing parallel programseffectively unscalable.
6.2 The Building Blocks:Send and Receive Operations (1/3)
^ The prototypes of these operations are as follows: ^ send (void *sendbuf, int nelems, int dest) ^ receive (void *recvbuf, int nelems, int source)
^ sendbuf points to a buffer that stores the data to be sent ^ recvbuf points to a buffer that stores the data to bereceived ^ nelems is the number of data units to be sent andreceived ^ dest is the identifier of the process that receives the data ^ source is the identifier of the process that sends the data
The Building Blocks:Send and Receive Operations (2/3)
1.^
P
2.^
a = 100;
3.^
send(&a, 1, 1);
4.^
a = 0;
P1 receive(&a, 1, 0)printf("%d\n", a);
^ Performance ramifications of how these functionsare implemented.Example:
What is problem with this code??
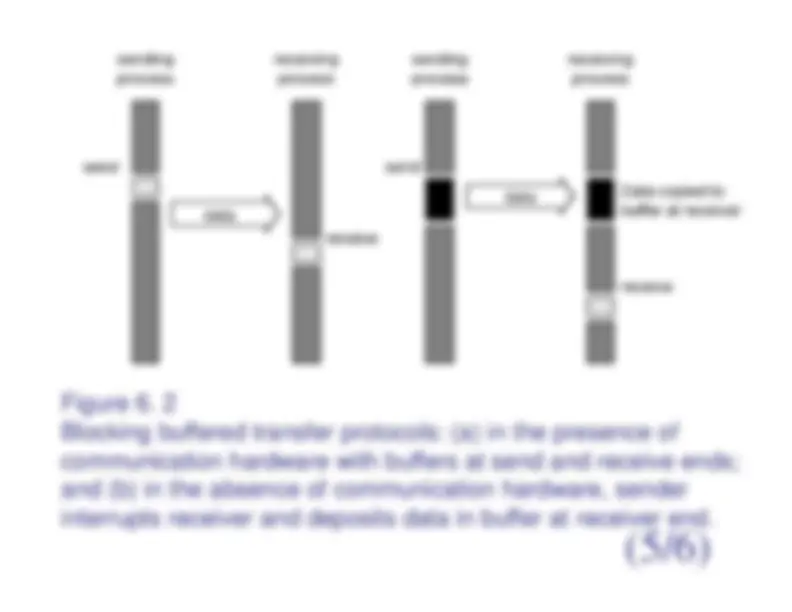
6.2.1 Blocking Message PassingOperations
^ The sending operation blocks until it canguarantee that the semantics will not be violatedon return irrespective of what happens in theprogram subsequently. ^ There are two mechanisms by which this can beachieved:
^ Blocking Non-Buffered Send/Receive. ^ Blocking Buffered Send/Receive.
6.2.1.1 Blocking Non-BufferedSend/Receive (1/2)
^ The send operation does not return until thematching receive has been encountered at thereceiving process. ^ Then the message is sent and the send operationreturns upon completion of the communicationoperation.
6.2.1.1.1 Idling Overheads in BlockingNon-Buffered Send/Recv (1/3) ^ 3 scenarios:a)^
the send is reached before the receive is posted, b)^
the send and receive are posted around the sametime, c)^
the receive is posted before the send is reached.
Figure 6. 1Handshake for a blocking non-buffered send/receive operation.It is easy to see that in cases where sender and receiver do notreach communication point at similar times, there can beconsiderable idling overheads.
(2/3)
6.2.1.1.2 Deadlocks in BlockingNon-Buffered Send/Recv (1/2)
1.^
P
2. 3.^
send(&a, 1, 1);
4.^
receive(&b, 1, 1)
P1 send(&a, 1, 0);receive(&b, 1, 0)
^ Consider the following simple exchange ofmessages that can lead to a deadlock:
Deadlocks in Blocking Non-BufferedSend/Recv (2/2) ^ The send at P0 waits for the matching receive at P1 ^ The send at process P1 waits for the correspondingreceive at P0, resulting in an infinite wait. ^ Deadlocks are very easy in blocking protocols and caremust be taken to break cyclic waits of the nature outlined. ^ In the above example, this can be corrected by replacingthe operation sequence of one of the processes by areceive and a send as opposed to the other way around. ^ This often makes the code more cumbersome and buggy.