Computer Design and Organization
•Architecture = Design + Organization + Performance
•Topics in this class:
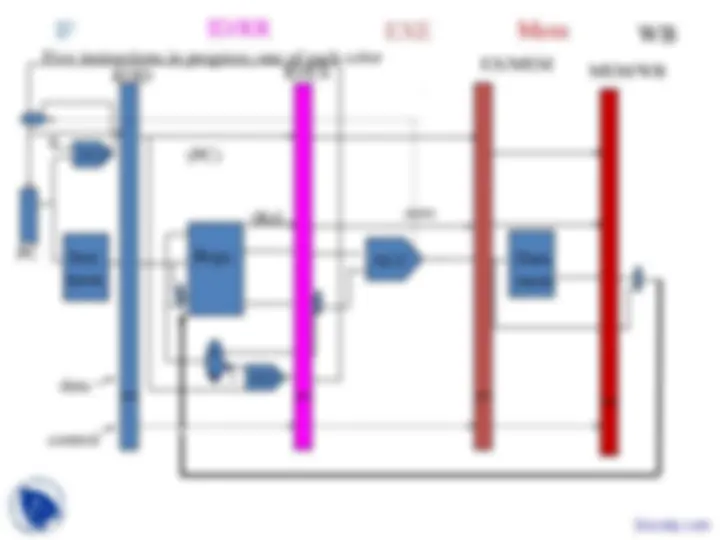
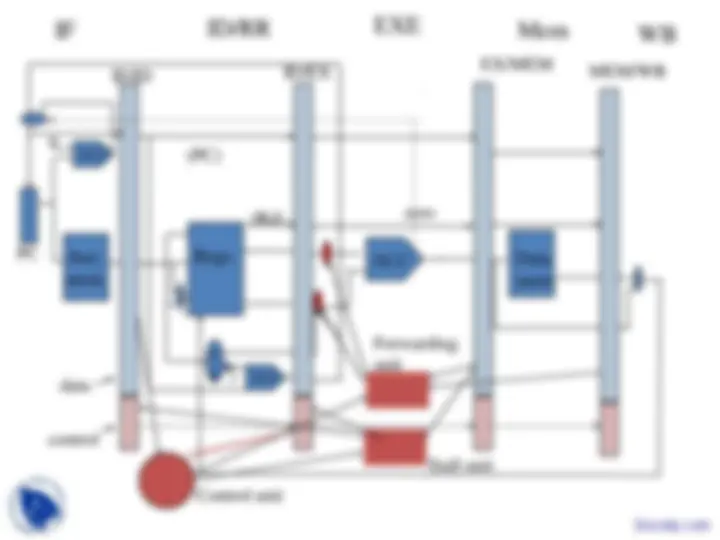
–Central processing unit: deeply pipelined, multiple instr.
per cycle, exploitation of instruction level parallelism (in-
order and out-of-order), support for speculation (branch
prediction, spec. loads).
–Memory hierarchy: multi-level cache hierarchy, includes
hardware and software assists for enhanced performance
–Multiprocessors: SMP’s and CMP’s –cache coherence and
synchronization
–Multithreading: Fine, coarse and SMT
–Some “advanced” topic: current research in dept.
Docsity.com