



Classification Algorithms
Docsity.com






























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of classification algorithms, focusing on rule generation and linear models. It covers various methods for generating rules from decision trees, including covering algorithms and simple covering algorithms. The document also discusses linear regression and logistic regression as linear models for classification. It is a useful resource for students and researchers in machine learning and data mining.
Typology: Slides
1 / 38

This page cannot be seen from the preview
Don't miss anything!
Docsity.com
2 Docsity.com
each class in turn find rule set that covers all
instances in it (excluding instances not in the
class)
because at each stage a rule is identified that
covers some of the instances
4 Docsity.com
5
y
x
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) aa
a a
Docsity.com
7
y
x
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) aa
a a
y
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) aa
a a
1·2 x
y
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) a
a a a
1·2 x
2·
Docsity.com
8
y
x
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) aa
a a
y
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) aa
a a
1·2 x
y
a
b b
b
b
b
b b
b
b b^ b b b b
a (^) a
a a a
1·2 x
2·
Docsity.com
rule’s accuracy
of selecting an attribute to split on
rule’s coverage:
10
space of examples
rule so far
rule after adding new term
witten&eibe Docsity.com
11 witten&eibe Docsity.com
13
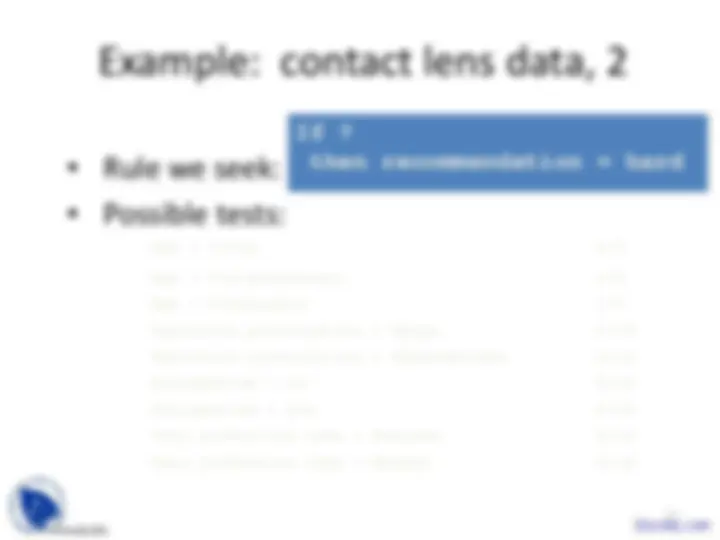
Age = Young 2/
Age = Pre-presbyopic 1/ Age = Presbyopic 1/ Spectacle prescription = Myope 3/ Spectacle prescription = Hypermetrope 1/ Astigmatism = no 0/ Astigmatism = yes 4/ Tear production rate = Reduced 0/ Tear production rate = Normal 4/
witten&eibe Docsity.com
14
Age Spectacle prescription Astigmatism Tear production rate Recommended lenses Young Myope Yes Reduced None Young Myope Yes Normal Hard Young Hypermetrope Yes Reduced None Young Hypermetrope Yes Normal hard Pre-presbyopic Myope Yes Reduced None Pre-presbyopic Myope Yes Normal Hard Pre-presbyopic Hypermetrope Yes Reduced None Pre-presbyopic Hypermetrope Yes Normal None Presbyopic Myope Yes Reduced None Presbyopic Myope Yes Normal Hard Presbyopic Hypermetrope Yes Reduced None Presbyopic Hypermetrope Yes Normal None
If astigmatism = yes then recommendation = hard
witten&eibe Docsity.com
16
Age = Young 2/ Age = Pre-presbyopic 1/ Age = Presbyopic 1/ Spectacle prescription = Myope 3/ Spectacle prescription = Hypermetrope 1/ Tear production rate = Reduced 0/ Tear production rate = Normal 4/
witten&eibe Docsity.com
17
Age Spectacle prescription Astigmatism Tear production rate Recommended lenses Young Myope Yes Normal Hard Young Hypermetrope Yes Normal hard Pre-presbyopic Myope Yes Normal Hard Pre-presbyopic Hypermetrope Yes Normal None Presbyopic Myope Yes Normal Hard Presbyopic Hypermetrope Yes Normal None
If astigmatism = yes and tear production rate = normal then recommendation = hard
witten&eibe Docsity.com
19
Age = Young 2/ Age = Pre-presbyopic 1/ Age = Presbyopic 1/ Spectacle prescription = Myope 3/ Spectacle prescription = Hypermetrope 1/
witten&eibe Docsity.com
20
If astigmatism = yes and tear production rate = normal and spectacle prescription = myope then recommendation = hard
If age = young and astigmatism = yes and tear production rate = normal then recommendation = hard
witten&eibe Docsity.com