Download Cluster Analysis: Choosing the Right Procedure and Number of Clusters and more Summaries Statistics in PDF only on Docsity!
375
C h a p t e r
Cluster Analysis
Identifying groups of individuals or objects that are similar to each other but different from individuals in other groups can be intellectually satisfying, profitable, or sometimes both. Using your customer base, you may be able to form clusters of customers who have similar buying habits or demographics. You can take advantage of these similarities to target offers to subgroups that are most likely to be receptive to them. Based on scores on psychological inventories, you can cluster patients into subgroups that have similar response patterns. This may help you in targeting appropriate treatment and studying typologies of diseases. By analyzing the mineral contents of excavated materials, you can study their origins and spread.
Tip: Although both cluster analysis and discriminant analysis classify objects (or cases) into categories, discriminant analysis requires you to know group membership for the cases used to derive the classification rule. The goal of cluster analysis is to identify the actual groups. For example, if you are interested in distinguishing between several disease groups using discriminant analysis, cases with known diagnoses must be available. Based on these cases, you derive a rule for classifying undiagnosed patients. In cluster analysis, you don’t know who or what belongs in which group. You often don’t even know the number of groups.
Examples
You need to identify people with similar patterns of past purchases so that you can tailor your marketing strategies. You’ve been assigned to group television shows into homogeneous categories based on viewer characteristics. This can be used for market segmentation.
Chapter 17
You want to cluster skulls excavated from archaeological digs into the civilizations from which they originated. Various measurements of the skulls are available. You’re trying to examine patients with a diagnosis of depression to determine if distinct subgroups can be identified, based on a symptom checklist and results from psychological tests.
In a Nutshell
You start out with a number of cases and want to subdivide them into homogeneous groups. First, you choose the variables on which you want the groups to be similar. Next, you must decide whether to standardize the variables in some way so that they all contribute equally to the distance or similarity between cases. Finally, you have to decide which clustering procedure to use, based on the number of cases and types of variables that you want to use for forming clusters. For hierarchical clustering, you choose a statistic that quantifies how far apart (or similar) two cases are. Then you select a method for forming the groups. Because you can have as many clusters as you do cases (not a useful solution!), your last step is to determine how many clusters you need to represent your data. You do this by looking at how similar clusters are when you create additional clusters or collapse existing ones. In k -means clustering, you select the number of clusters you want. The algorithm iteratively estimates the cluster means and assigns each case to the cluster for which its distance to the cluster mean is the smallest. In two-step clustering, to make large problems tractable, in the first step, cases are assigned to “preclusters.” In the second step, the preclusters are clustered using the hierarchical clustering algorithm. You can specify the number of clusters you want or let the algorithm decide based on preselected criteria.
Introduction
The term cluster analysis does not identify a particular statistical method or model, as do discriminant analysis, factor analysis, and regression. You often don’t have to make any assumptions about the underlying distribution of the data. Using cluster analysis, you can also form groups of related variables, similar to what you do in factor analysis. There are numerous ways you can sort cases into groups. The choice of a method depends on, among other things, the size of the data file. Methods commonly used for small datasets are impractical for data files with thousands of cases.
Chapter 17
Figure Skating Judges: The Example
As an example of agglomerative hierarchical clustering, you’ll look at the judging of pairs figure skating in the 2002 Olympics. Each of nine judges gave each of 20 pairs of skaters four scores: technical merit and artistry for both the short program and the long program. You’ll see which groups of judges assigned similar scores. To make the example more interesting, only the scores of the top four pairs are included. That’s where the Olympic scoring controversies were centered. (For background on the controversy concerning the 2002 Olympic Winter Games pairs figure skating, see http://en.wikipedia.org/wiki/2002_Olympic_Winter_Games_figure_skating_scandal. The actual scores are only one part of an incredibly complex, and not entirely objective, procedure for assigning medals to figure skaters and ice dancers.)*
Tip: Consider carefully the variables you will use for establishing clusters. If you don’t include variables that are important, your clusters may not be useful. For example, if you are clustering schools and don’t include information on the number of students and faculty at each school, size will not be used for establishing clusters.
How Alike (or Different) Are the Cases?
Because the goal of this cluster analysis is to form similar groups of figure-skating judges, you have to decide on the criterion to be used for measuring similarity or distance. Distance is a measure of how far apart two objects are, while similarity measures how similar two objects are. For cases that are alike, distance measures are small and similarity measures are large. There are many different definitions of distance and similarity. Some, like the Euclidean distance, are suitable for only continuous variables, while others are suitable for only categorical variables. There are also many specialized measures for binary variables. See the Help system for a description of the more than 30 distance and similarity measures available in IBM SPSS Statistics.
Warning: The computation for the selected distance measure is based on all of the variables you select. If you have a mixture of nominal and continuous variables, you must use the two-step cluster procedure because none of the distance measures in hierarchical clustering or k -means are suitable for use with both types of variables.
- I wish to thank Professor John Hartigan of Yale University for extracting the data from www.nbcolympics.com and making it available as a data file.
Cluster Analysis
To see how a simple distance measure is computed, consider the data in Figure 17-1. The table shows the ratings of the French and Canadian judges for the Russian pairs figure skating team of Berezhnaya and Sikhardulidze. Figure 17- Distances for two judges for one pair
You see that, for the long program, there is a 0.1 point difference in technical merit scores and a 0.1 difference in artistry scores between the French judge and the Canadian judge. For the short program, they assigned the same scores to the pair. This information can be combined into a single index or distance measure in many different ways. One frequently used measure is the squared Euclidean distance, which is the sum of the squared differences over all of the variables. In this example, the squared Euclidean distance is 0.02. The squared Euclidean distance suffers from the disadvantage that it depends on the units of measurement for the variables.
Standardizing the Variables
If variables are measured on different scales, variables with large values contribute more to the distance measure than variables with small values. In this example, both variables are measured on the same scale, so that’s not much of a problem, assuming the judges use the scales similarly. But if you were looking at the distance between two people based on their IQs and incomes in dollars, you would probably find that the differences in incomes would dominate any distance measures. (A difference of only $100 when squared becomes 10,000, while a difference of 30 IQ points would be only
- I’d go for the IQ points over the dollars!) Variables that are measured in large numbers will contribute to the distance more than variables recorded in smaller numbers.
Tip: In the hierarchical clustering procedure in IBM SPSS Statistics, you can standardize variables in different ways. You can compute standardized scores or divide by just the standard deviation, range, mean, or maximum. This results in all variables contributing more equally to the distance measurement. That’s not necessarily always the best strategy, since variability of a measure can provide useful information.
Long Program Short Program Judge Technical Merit Artistry Technical Merit Artistry France 5.8 5.9 5.8 5. Canada 5.7 5.8 5.8 5.
Cluster Analysis
When you have only one case in a cluster, the smallest distance between cases in two clusters is unambiguous. It’s the distance or similarity measure you selected for the proximity matrix. Once you start forming clusters with more than one case, you need to define a distance between pairs of clusters. For example, if cluster A has cases 1 and 4, and cluster B has cases 5, 6, and 7, you need a measure of how different or similar the two clusters are. There are many ways to define the distance between two clusters with more than one case in a cluster. For example, you can average the distances between all pairs of cases formed by taking one member from each of the two clusters. Or you can take the largest or smallest distance between two cases that are in different clusters. Different methods for computing the distance between clusters are available and may well result in different solutions. The methods available in IBM SPSS Statistics hierarchical clustering are described in “Distance between Cluster Pairs” on p. 387.
Summarizing the Steps: The Icicle Plot
From Figure 17-3, you can see what’s happening at each step of the cluster analysis when average linkage between groups is used to link the clusters. The figure is called an icicle plot because the columns of X ’s look (supposedly) like icicles hanging from eaves. Each column represents one of the objects you’re clustering. Each row shows a cluster solution with different numbers of clusters. You read the figure from the bottom up. The last row (that isn’t shown) is the first step of the analysis. Each of the judges is a cluster unto himself or herself. The number of clusters at that point is 9. The eight- cluster solution arises when the Russian and French judges are joined into a cluster. (Remember they had the smallest distance of all pairs.) The seven-cluster solution results from the merging of the German and Canadian judges into a cluster. The six- cluster solution is the result of combining the Japanese and U.S. judges. For the one- cluster solution, all of the cases are combined into a single cluster.
Warning: When pairs of cases are tied for the smallest distance, an arbitrary selection is made. You might get a different cluster solution if your cases are sorted differently. That doesn’t really matter, since there is no right or wrong answer to a cluster analysis. Many groupings are equally plausible.
Chapter 17
Figure 17- Vertical icicle plot
Tip: If you have a large number of cases to cluster, you can make an icicle plot in which the cases are the rows. Specify Horizontal on the Cluster Plots dialog box.
Who’s in What Cluster?
You can get a table that shows the cases in each cluster for any number of clusters. Figure 17-4 shows the judges in the three-, four-, and five-cluster solutions. Figure 17- Cluster membership
Chapter 17
The agglomeration schedule starts off using the case numbers that are displayed on the icicle plot. Once cases are added to clusters, the cluster number is always the lowest of the case numbers in the cluster. A cluster formed by merging cases 3 and 4 would forever be known as cluster 3, unless it happened to merge with cluster 1 or 2. The columns labeled Stage Cluster First Appears tell you the step at which each of the two clusters that are being joined first appear. For example, at stage 4 when cluster 3 and cluster 6 are combined, you’re told that cluster 3 was first formed at stage 1 and cluster 6 is a single case and that the resulting cluster (known as 3) will see action again at stage 5. For a small dataset, you’re much better off looking at the icicle plot than trying to follow the step-by-step clustering summarized in the agglomeration schedule.
Tip: In most situations, all you want to look at in the agglomeration schedule is the coefficient at which clusters are combined. Look at the icicle plot to see what’s going on.
Plotting Cluster Distances: The Dendrogram
If you want a visual representation of the distance at which clusters are combined, you can look at a display called the dendrogram, shown in Figure 17-6. The dendrogram is read from left to right. Vertical lines show joined clusters. The position of the line on the scale indicates the distance at which clusters are joined. The observed distances are rescaled to fall into the range of 1 to 25, so you don’t see the actual distances; however, the ratio of the rescaled distances within the dendrogram is the same as the ratio of the original distances. The first vertical line, corresponding to the smallest rescaled distance, is for the French and Russian alliance. The next vertical line is at the same distances for three merges. You see from Figure 17-5 that stages 2, 3, and 4 have the same coefficients. What you see in this plot is what you already know from the agglomeration schedule. In the last two steps, fairly dissimilar clusters are combined.
Cluster Analysis
Figure 17- The dendrogram
Tip: When you read a dendrogram, you want to determine at what stage the distances between clusters that are combined is large. You look for large distances between sequential vertical lines.
Clustering Variables
In the previous example, you saw how homogeneous groups of cases are formed. The unit of analysis was the case (each judge). You can also use cluster analysis to find homogeneous groups of variables.
Warning: When clustering variables, make sure to select the Variables radio button in the Cluster dialog box; otherwise, IBM SPSS Statistics will attempt to cluster cases, and you will have to stop the processor because it can take a very long time.
Cluster Analysis
Tip: When you use the correlation coefficient as a measure of similarity, you may want to take the absolute value of it before forming clusters. Variables with large negative correlation coefficients are just as closely related as variables with large positive coefficients.
Distance between Cluster Pairs
The most frequently used methods for combining clusters at each stage are available in IBM SPSS Statistics. These methods define the distance between two clusters at each stage of the procedure. If cluster A has cases 1 and 2 and if cluster B has cases 5, 6, and 7, you need a measure of how different or similar the two clusters are. Nearest neighbor (single linkage). If you use the nearest neighbor method to form clusters, the distance between two clusters is defined as the smallest distance between two cases in the different clusters. That means the distance between cluster A and cluster B is the smallest of the distances between the following pairs of cases: (1,5), (1,6), (1,7), (2,5), (2,6), and (2,7). At every step, the distance between two clusters is taken to be the distance between their two closest members. Furthest neighbor (complete linkage). If you use a method called furthest neighbor (also known as complete linkage), the distance between two clusters is defined as the distance between the two furthest points. UPGMA. The average-linkage-between-groups method, often aptly called UPGMA (unweighted pair-group method using arithmetic averages), defines the distance between two clusters as the average of the distances between all pairs of cases in which one member of the pair is from each of the clusters. For example, if cases 1 and 2 form cluster A and cases 5, 6, and 7 form cluster B, the average-linkage-between-groups distance between clusters A and B is the average of the distances between the same pairs of cases as before: (1,5), (1,6), (1,7), (2,5), (2,6), and (2,7). This differs from the linkage methods in that it uses information about all pairs of distances, not just the nearest or the furthest. For this reason, it is usually preferred to the single and complete linkage methods for cluster analysis. Average linkage within groups. The UPGMA method considers only distances between pairs of cases in different clusters. A variant of it, the average linkage within groups, combines clusters so that the average distance between all cases in the resulting cluster is as small as possible. Thus, the distance between two clusters is the average of the distances between all possible pairs of cases in the resulting cluster.
Chapter 17
The methods discussed above can be used with any kind of similarity or distance measure between cases. The next three methods use squared Euclidean distances. Ward’s method. For each cluster, the means for all variables are calculated. Then, for each case, the squared Euclidean distance to the cluster means is calculated. These distances are summed for all of the cases. At each step, the two clusters that merge are those that result in the smallest increase in the overall sum of the squared within-cluster distances. The coefficient in the agglomeration schedule is the within-cluster sum of squares at that step, not the distance at which clusters are joined. Centroid method. This method calculates the distance between two clusters as the sum of distances between cluster means for all of the variables. In the centroid method, the centroid of a merged cluster is a weighted combination of the centroids of the two individual clusters, where the weights are proportional to the sizes of the clusters. One disadvantage of the centroid method is that the distance at which clusters are combined can actually decrease from one step to the next. This is an undesirable property because clusters merged at later stages are more dissimilar than those merged at early stages. Median method. With this method, the two clusters being combined are weighted equally in the computation of the centroid, regardless of the number of cases in each. This allows small groups to have an equal effect on the characterization of larger clusters into which they are merged.
Tip: Different combinations of distance measures and linkage methods are best for clusters of particular shapes. For example, nearest neighbor works well for elongated clusters with unequal variances and unequal sample sizes.
K-Means Clustering
Hierarchical clustering requires a distance or similarity matrix between all pairs of cases. That’s a humongous matrix if you have tens of thousands of cases trapped in your data file. Even today’s computers will take pause, as will you, waiting for results. A clustering method that doesn’t require computation of all possible distances is k -means clustering. It differs from hierarchical clustering in several ways. You have to know in advance the number of clusters you want. You can’t get solutions for a range of cluster numbers unless you rerun the analysis for each different number of clusters. The algorithm repeatedly reassigns cases to clusters, so the same case can move from cluster to cluster during the analysis. In agglomerative hierarchical clustering, on the other hand, cases are added only to existing clusters. They’re forever captive in their cluster, with a widening circle of neighbors.
Chapter 17
Initial Cluster Centers
The first step in k -means clustering is finding the k centers. This is done iteratively. You start with an initial set of centers and then modify them until the change between two iterations is small enough. If you have good guesses for the centers, you can use those as initial starting points; otherwise, you can let IBM SPSS Statistics find k cases that are well-separated and use these values as initial cluster centers. Figure 17-8 shows the initial centers for the pottery example. Figure 17- Initial cluster centers
Warning: K -means clustering is very sensitive to outliers, since they will usually be selected as initial cluster centers. This will result in outliers forming clusters with small numbers of cases. Before you start a cluster analysis, screen the data for outliers and remove them from the initial analysis. The solution may also depend on the order of the cases in the file.
After the initial cluster centers have been selected, each case is assigned to the closest cluster, based on its distance from the cluster centers. After all of the cases have been assigned to clusters, the cluster centers are recomputed, based on all of the cases in the cluster. Case assignment is done again, using these updated cluster centers. You keep assigning cases and recomputing the cluster centers until no cluster center changes appreciably or the maximum number of iterations (10 by default) is reached.
From Figure 17-9, you see that three iterations were enough for the pottery data. Figure 17- Iteration history
Cluster Analysis
Tip: You can update the cluster centers after each case is classified, instead of after all cases are classified, if you select the Use Running Means check box in the Iterate dialog box.
Final Cluster Centers
After iteration stops, all cases are assigned to clusters, based on the last set of cluster centers. After all of the cases are clustered, the cluster centers are computed one last time. Using the final cluster centers, you can describe the clusters. In Figure 17-10, you see that cluster 1 has an average sodium percentage that is much higher than the other clusters. Cluster 2 has higher-than-average values for calcium, iron, and magnesium, an average value for sodium, and a smaller-than-average value for aluminum. Cluster 3 has below-average values for all of the minerals except aluminum. Figure 17- Final cluster centers
Tip: You can save the final cluster centers and use them to classify new cases. In the Cluster dialog box, save the cluster centers by selecting Write Final As and then clicking File to assign a filename. To use these cluster centers to classify new cases, select Classify Only, select Read Initial From, and then click File to specify the file of cluster centers that you saved earlier.
Differences between Clusters
You can compute F ratios that describe the differences between the clusters. As the footnote in Figure 17-11 warns, the observed significance levels should not be interpreted in the usual fashion because the clusters have been selected to maximize the differences between clusters. The point of Figure 17-11 is to give you a handle on the differences for each of the variables among the clusters. If the observed significance level for a variable is large, you can be pretty sure that the variable doesn’t contribute much to the separation of the clusters.
Cluster Analysis
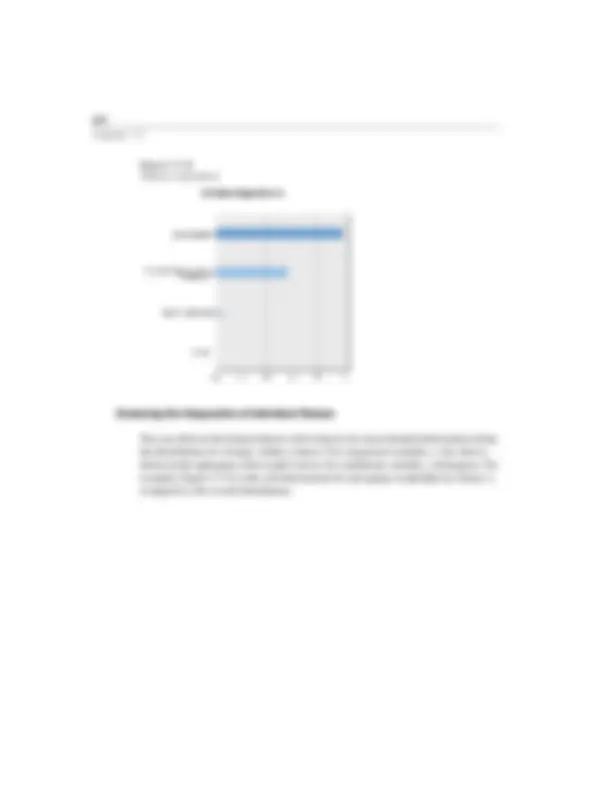
Figure 17- Plot of distances to cluster centers
You can decrease the number of clusters to be used to two and that would most likely eliminate the two-case cluster at the expense of making the clusters more heterogeneous. Or you could increase the number of clusters and see how the solution changes. In this example, increasing the number of clusters causes clusters 2 and 3 to split, while cluster 1 remains with the two cases that are characterized by very high levels of sodium.
Locations of the Pottery
The pottery in the dataset was found in one of four locations. To see whether pottery found at the same site is homogeneous with respect to metallic composition, you can crosstabulate the site where a pot was found and the cluster to which it was assigned, as shown in Figure 17-14.
1 2 3
1.50^ excavation site Llanederyn Caldicot Ashley Rails^ Island Thorns
Cluster Number of Case
Distance of Case from its Classication Cluster Center
Chapter 17
Figure 17- Crosstabulation of site and cluster
You see that the anomalous pottery in cluster 1 was found at the first site. Most of the cases in cluster 2 were also from the first site, although two of them were from the second. Pottery from the third and fourth sites were all in cluster 3. It looks like there is a relationship between the metallic composition of a piece of pottery and the site where it was excavated.
Two-Step Cluster
When you have a really large dataset or you need a clustering procedure that can rapidly form clusters on the basis of either categorical or continuous data, neither of the previous two procedures fills the bill. Hierarchical clustering requires a matrix of distances between all pairs of cases, and k -means requires shuffling cases in and out of clusters and knowing the number of clusters in advance. The IBM SPSS Statistics TwoStep Cluster Analysis procedure was designed for such applications. It requires only one pass of data (which is important for very large data files), and it can produce solutions based on mixtures of continuous and categorical variables and for varying numbers of clusters. The clustering algorithm is based on a distance measure that gives the best results if all variables are independent, continuous variables that have a normal distribution, and categorical variables that have a multinomial distribution. This is seldom the case in practice, but the algorithm is thought to behave reasonably well when the assumptions are not met. Because cluster analysis does not involve hypothesis testing and calculation of observed significance levels, other than for descriptive follow-up, it’s perfectly acceptable to cluster data that may not meet the assumptions for best performance. Only you can determine whether the solution is satisfactory for your needs.