Download High Performance Computing Lecture 38: Parallel Computing and Flynn's Classification and more Slides Computer Science in PDF only on Docsity!
High Performance Computing
Lecture 38
2 Agenda
- Program execution: Compilation, Object files, Function call and return, Address space, Data & its representation (4)
- Computer organization: Memory, Registers, Instruction set architecture, Instruction processing (6)
- Virtual memory: Address translation, Paging (4)
- Operating system: Processes, System calls, Process management (6)
- Pipelined processors: Structural, data and control hazards, impact on programming (4)
- Cache memory: Organization, impact on programming (5)
- Program profiling (2)
- File systems: Disk management, Name management, Protection (4)
- Parallel programming: Inter-process communication, Synchronization, Mutual exclusion, Parallel architecture, Programming with message passing using MPI (5)
4
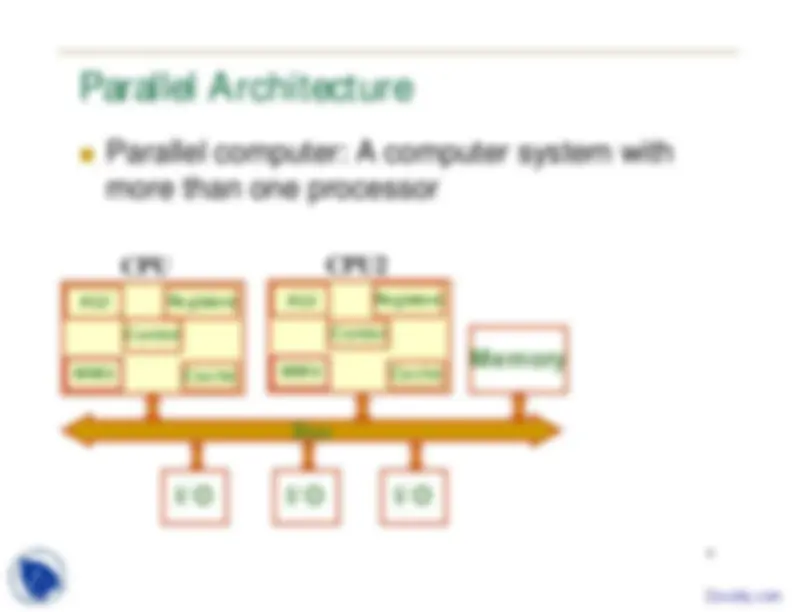
Parallel computer: A computer system with
more than one processor
Parallel Architecture Memory I/O Bus I/O I/O MMU Cache ALU Registers
CPU
Control MMU Cache ALU Registers
CPU
Control
5 Parallel Architecture
Question: Is a network of computers a parallel
computer?
Yes, but the time involved in interaction
(communication) might be high, as the
system is designed assuming that the
machines are more or less independent
Special parallel machines would be
designed to make this interaction overhead
less
7 Classification of Parallel Computers
Flynn’s Classification
In terms of the number of Instruction streams
and Data streams
Instruction stream: A path to instruction
memory (i.e., a program counter or PC)
Data stream: A path to data memory
SISD: single instruction stream single data stream
SIMD: single instruction stream multiple data
streams
MIMD: multiple instruction stream multiple data
streams
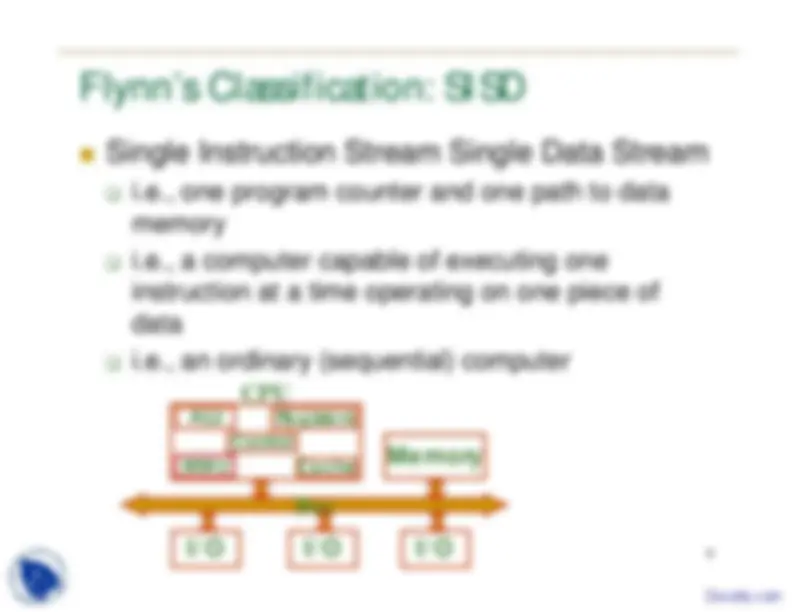
8 Flynn’s Classification: SISD
Single Instruction Stream Single Data Stream
i.e., one program counter and one path to data
memory
i.e., a computer capable of executing one
instruction at a time operating on one piece of
data
i.e., an ordinary (sequential) computer
Cache Memory I/O Bus I/O I/O MMU ALU (^) Registers
CPU
Control
10
Flynn’s Classification: SIMD
Example: A computer with 1024 ALUs (each
with a separate data path to memory), but
only one program counter (PC and IR)
ALU ALU ALU
PC
IR MUL Ai, Bi The same MUL instruction is executed on each of the ALUs, but on different pieces of data
11 Flynn’s Classification: MIMD
Multiple Instruction Stream Multiple Data
Stream
i.e., a computer that can run multiple processes
or threads that are cooperating towards a
common objective
in parallel, not just concurrently
Alternatively, the MIMD computer could run
multiple independent programs at the same time
13 Shared Memory Machines
The shared memory could itself be distributed
among the processor nodes
Each processor might have some portion of the
shared physical address space that is physically
close to it and therefore accessible in less time
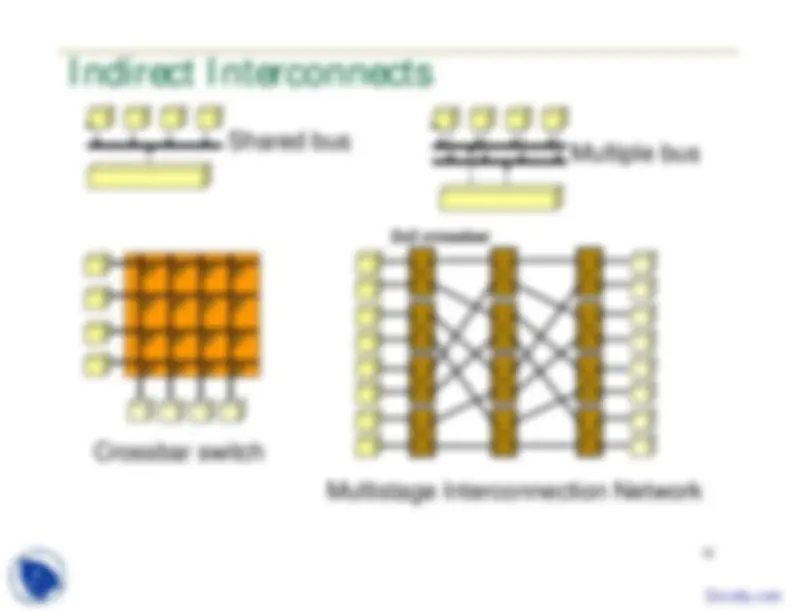
14 Parallel Architecture: Interconnections
Indirect interconnects: nodes are connected
to interconnection medium, not directly to
each other
Shared bus, multiple bus, crossbar, MIN
Direct interconnects: nodes are connected
directly to each other
Topology: linear, ring, star, mesh, torus,
hypercube
Routing techniques: how the route taken by the
message from source to destination is decided
16 Direct Interconnect Topologies Linear Ring Star Mesh
2D
Torus Hypercube(binary n-cube) n=2 n=
17
X: 0
X: 1
Shared Memory Architecture: Caches X: 0 Read X Read X X: 0 Write X= X: 1 Read X Cache hit: Wrong data!!
P1 P
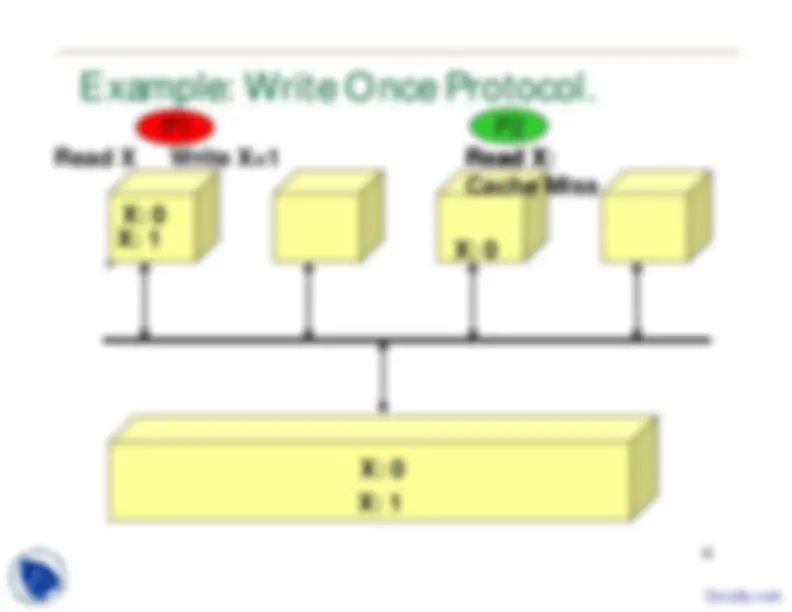
19 Example: Write Once Protocol
Assumption: shared bus interconnect where
all cache controllers monitor all bus activity
Called snooping
There is only one operation through bus at a
time; cache controllers can be built to take
corrective action and enforce coherence in
caches
Corrective action could involve updating or
invalidating a cache block
20
X: 0
X: 1
X: 0
Read X Read X X: 0 Write X= X: 1 Read X: Cache Miss
P1 P
Example: Write Once Protocol.