Download Data Hazards and Exception Handling in MIPS Processors and more Slides Computer Science in PDF only on Docsity!
CS 152: Computer Architecture
and Engineering
Lecture 14
Advanced Pipelining/Compiler Scheduling
Review: Pipelining
- Key to pipelining: smooth flow
- Making all instructions the same length can increase
performance!
- Hazards limit performance
- Structural: need more HW resources
- Data: need forwarding, compiler scheduling
- Control: early evaluation & PC, delayed branch, prediction
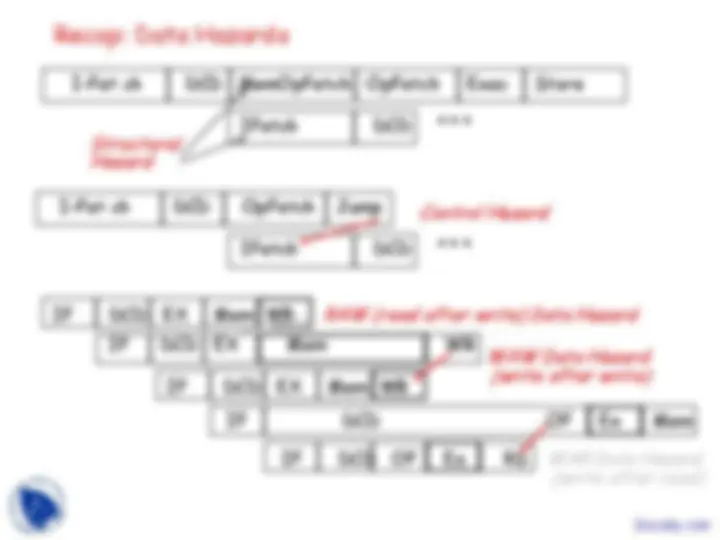
- Data hazards must be handled carefully:
- RAW (Read-After-Write) data hazards handled by forwarding
- WAW (Write-After-Write) and WAR (Write-After-Read)
hazards don’t exist in 5-stage pipeline
- MIPS I instruction set architecture made pipeline
visible (delayed branch, delayed load)
- Change in programmer semantics to make hardware simpler
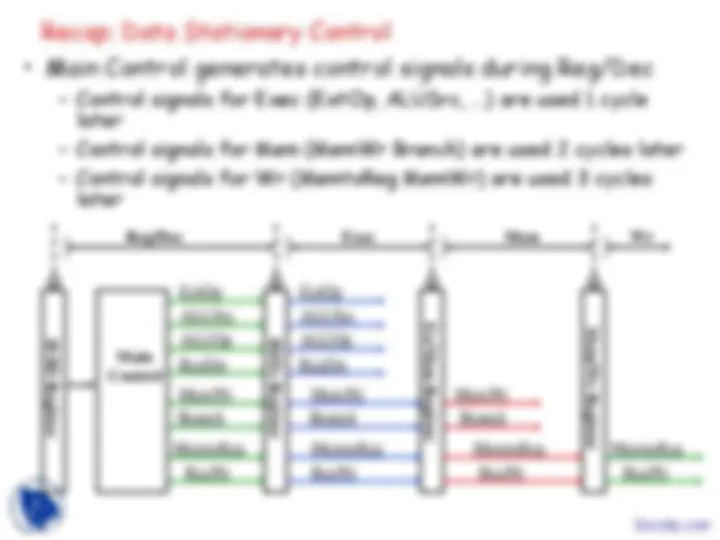
Recap: Data Stationary Control
- Main Control generates control signals during Reg/Dec
- Control signals for Exec (ExtOp, ALUSrc, ...) are used 1 cycle
later
- Control signals for Mem (MemWr Branch) are used 2 cycles later
- Control signals for Wr (MemtoReg MemWr) are used 3 cycles
later
IF/ID Register^ ID/Ex Register
Ex/Mem Register Mem/Wr Register
Reg/Dec Exec Mem
ExtOp
ALUOp RegDst
ALUSrc
Branch
MemWr
MemtoReg RegWr
Main Control
ExtOp
ALUOp RegDst
ALUSrc
MemtoReg RegWr
MemtoReg RegWr
MemtoReg RegWr
Branch
MemWr Branch
MemWr
Wr
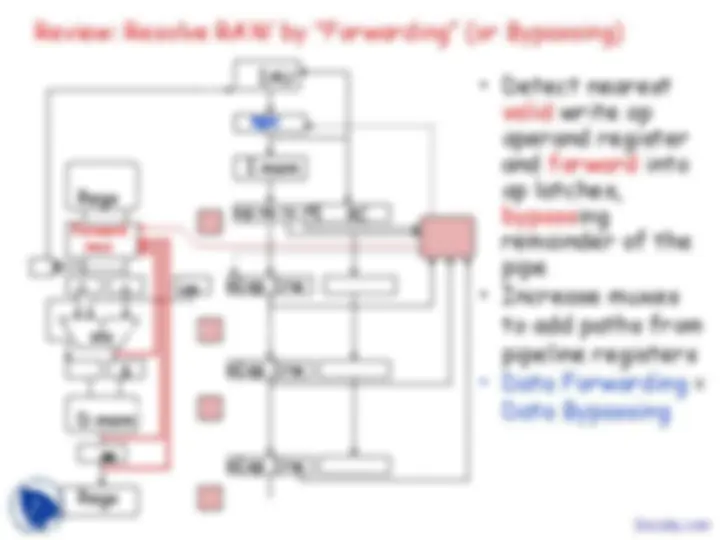
Review: Resolve RAW by “Forwarding” (or Bypassing)
valid write op
operand register
and forward into
op latches,
bypassing
remainder of the
pipe
to add paths from
pipeline registers
Data Bypassing
npc
I mem Regs
B
alu
S
D mem
m
IAU
PC
Regs
A (^) im n op^ rw
n op rw
n op rw
op rw rs rt Forward mux
What About Interrupts, Traps, Faults?
- External Interrupts:
- Allow pipeline to drain, Fill with NOPs
- Load PC with interrupt address
- Faults (within instruction, restartable)
- Force trap instruction into IF
- Disable writes till trap hits WB
- Must save multiple PCs or PC + state
- Recall: Precise Exceptions ⇒ State of the machine is
preserved as if program executed up to the
offending instruction
- All previous instructions completed
- Offending instruction and all following instructions act as if
they have not even started
- Same system code will work on different implementations
Exception/Interrupts: Implementation questions
5 instructions, executing in 5 different pipeline stages!
- Who caused the interrupt?
Stage Problem interrupts occurring
IF Page fault on instruction fetch; misaligned memory
access; memory-protection violation
ID Undefined or illegal opcode
EX Arithmetic exception
MEM Page fault on data fetch; misaligned memory
access; memory-protection violation; memory error
- How do we stop the pipeline? How do we restart it?
- Do we interrupt immediately or wait?
- How do we sort all of this out to maintain preciseness?
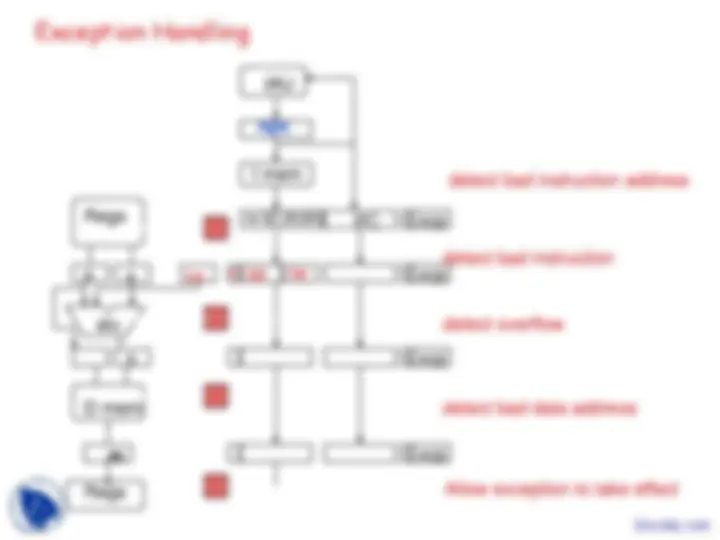
Another Look at the Exception Problem
- Use pipeline to sort this out!
- Pass exception status along with instruction.
- Keep track of PCs for every instruction in pipeline.
- Don’t act on exception until it reache WB stage
- Handle interrupts through “faulting noop” in IF stage
- When instruction reaches end of MEM stage:
- Save PC ⇒ EPC, Interrupt vector addr ⇒ PC
- Turn all instructions in earlier stages into noops!
Program Flow
Time
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
Data TLB
Bad Inst
Inst TLB fault
Overflow
Resolution: Freeze Above & Bubble Below
by setting “invalid”
bit in pipeline
npc
I mem
Regs
B
alu
S
D mem
m
IAU
PC
Regs
A (^) im n op rw
n op rw
n op rw
op rw rs rt bubble
freeze
MIPS R3000 Instruction Pipeline
Inst Fetch Decode Reg. Read
ALU / E.A Memory Write Reg
TLB I-Cache RF Operation WB
E.A. TLB D-Cache
TLB
I-cache RF ALUALU
TLB
D-Cache
WB
Resource Usage
Write in phase 1, read in phase 2 => eliminates bypass from WB
Recall: Data Hazard on r
I
n s t r.
O r d e r
Time (clock cycles)
add r1,r2,r
sub r4,r1,r
and r6,r1,r
or r8,r1,r
xor r10,r1,r
I
F
ID/R
F
E
X
ME
M
W
B
ALU Im Reg^ Dm Reg ALU Im (^) Reg Dm Reg
ALU Im (^) Reg Dm Reg
Im
ALU Reg Dm^ Reg
ALU Im (^) Reg Dm Reg
With MIPS R3000 pipeline, no need to forward from WB stage
Is CPI = 1 for our pipeline?
- Remember that CPI is an “Average # cycles/inst
- CPI here is 1, since the average throughput is 1
instruction every cycle.
- What if there are stalls or multi-cycle execution?
- Usually CPI > 1. How close can we get to 1??
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
IFetch Dcd Exec Mem WB
Recall: Compute CPI?
- Start with Base CPI
- Add stalls
= − 1 × − 1 + − 2 × − 2
= +
stall type type type type
base stall CPI STALL freq STALL freq
CPI CPI CPI
- Suppose:
- CPI (^) base =
- Freq (^) branch=20%, freq (^) load=30%
- Suppose branches always cause 1 cycle stall
- Loads cause a 100 cycle stall 1% of time
- Then: CPI = 1 + (1×0.20)+(100 × 0.30×0.01)=1.
- Multicycle? Could treat as:
CPI stall=(CYCLES-CPI base) × freq inst
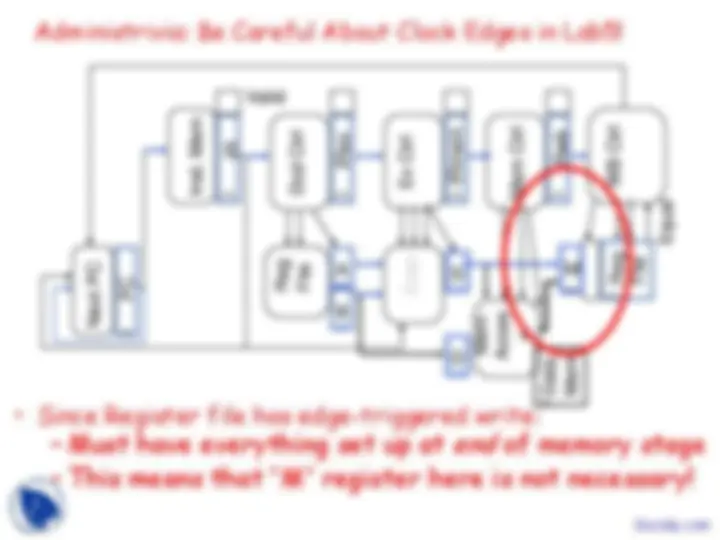
Administrivia: Be Careful About Clock Edges in Lab5!
Exec Reg.File
MemAcces
s
DataMem
A
B
S M
RegFile
Equal
PC
Next PC
IR
Inst. Mem
Valid
IRex Dcd Ctrl^ Ex Ctrl^ IRmem
IRwb Mem Ctrl
WB Ctrl
D
- Since Register file has edge-triggered write:
- Must have everything set up at end of memory stage
- This means that “M” register here is not necessary!
Case Study: MIPS R4000 (200 MHz)
- 8 Stage Pipeline:
- IF–first half of fetching of instruction; PC selection happens here as well as initiation of instruction cache access.
- IS–second half of access to instruction cache.
- RF–instruction decode and register fetch, hazard checking and also instruction cache hit detection.
- EX–execution, which includes effective address calculation, ALU operation, and branch target computation and condition evaluation.
- DF–data fetch, first half of access to data cache.
- DS–second half of access to data cache.
- TC–tag check, determine whether the data cache access hit.
- WB–write back for loads and register-register operations.
- 8 Stages:
What is impact on Load delay? Branch delay? Why?